- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It looks like vdSqrt does not work correctly in multi-threaded mode. Its performance is significantly slower than a simple loop of sqrt() calls. Moreover, it ignores OMP_NUM_THREADS completely.
I have made the attached test program to reproduce the bug, which had a dramatic impact and was hard to spot in amore complex application. This simple program computes the square root of a vector of 10000 elements for 5000 times. In order to prevent the compiler from removing code, some randomy selected items are added to a variable which is later printed to the standard output.
Three different ways of computing the square root are tested:
1) vdSqrt
2) loop of sqrt()
3) OpenMP parallel loop of sqrt()
Since I'm on a dual core machine (Core i5 430M), I run the code with OMP_NUM_THREADS=1 and OMP_NUM_THREADS=2. This measurements are obtained in a VMware virtual machine but the same behavior was observed on physical machines as well. The issue was reproduced on Debian 5, Ubuntu 8.04 and Ubuntu 10.10.
OMP_NUM_THREADS=1 OMP_NUM_THREADS=2
1) 0.99 s 0.96 s
2) 0.33 s 0.33 s
3) 0.34 s 0.21 s
If I force the code to run on fewer core by setting processor affinity with taskset the results are vastly different for vdSqrt:
taskset -c 0 taskset -c 0,2
1) 0.33 s 1.19 s
In a more complex program, replacing vdSqrt with a loop of sqrt yielded a 9x speedup.
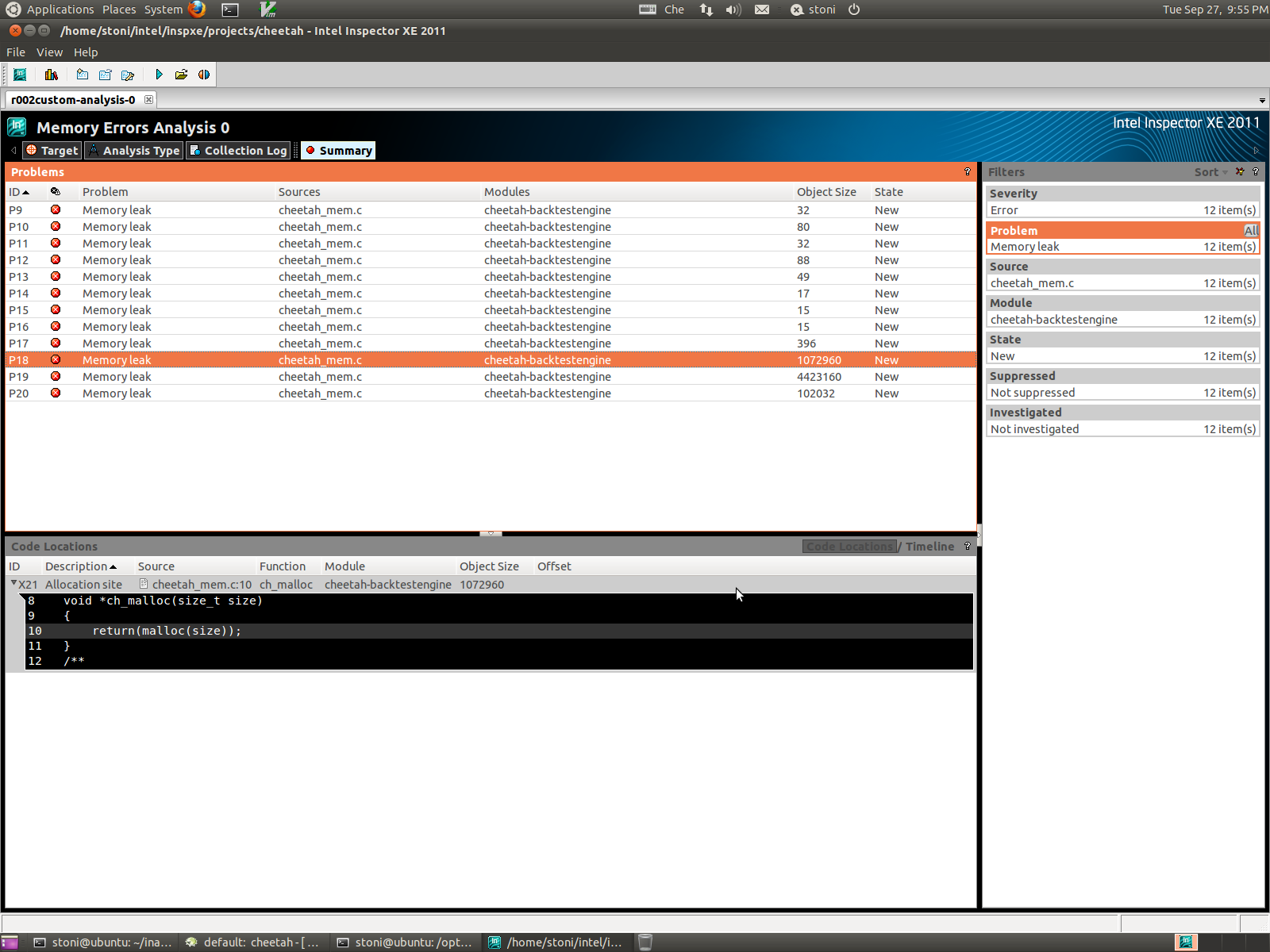
Performing a concurrency analysis with VTunes gives a better insight on the problem. While the third method and other MKL routines such as dgemv and dgemm only spawn a single worker thread with OMP_NUM_THREADS=2, vdSqrt spawns about 20 worker threads. The attached pictures highlights the issue.
I have made the attached test program to reproduce the bug, which had a dramatic impact and was hard to spot in amore complex application. This simple program computes the square root of a vector of 10000 elements for 5000 times. In order to prevent the compiler from removing code, some randomy selected items are added to a variable which is later printed to the standard output.
Three different ways of computing the square root are tested:
1) vdSqrt
2) loop of sqrt()
3) OpenMP parallel loop of sqrt()
Since I'm on a dual core machine (Core i5 430M), I run the code with OMP_NUM_THREADS=1 and OMP_NUM_THREADS=2. This measurements are obtained in a VMware virtual machine but the same behavior was observed on physical machines as well. The issue was reproduced on Debian 5, Ubuntu 8.04 and Ubuntu 10.10.
OMP_NUM_THREADS=1 OMP_NUM_THREADS=2
1) 0.99 s 0.96 s
2) 0.33 s 0.33 s
3) 0.34 s 0.21 s
If I force the code to run on fewer core by setting processor affinity with taskset the results are vastly different for vdSqrt:
taskset -c 0 taskset -c 0,2
1) 0.33 s 1.19 s
In a more complex program, replacing vdSqrt with a loop of sqrt yielded a 9x speedup.
Performing a concurrency analysis with VTunes gives a better insight on the problem. While the third method and other MKL routines such as dgemv and dgemm only spawn a single worker thread with OMP_NUM_THREADS=2, vdSqrt spawns about 20 worker threads. The attached pictures highlights the issue.
{kind=link}
1 Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is a knownissue with MKL 10.3 and has been fixed in MKL 10.3 update 1.
Please refer this KB for more details.
http://software.intel.com/en-us/articles/vml-routines-shows-a-noticeable-decrease-in-the-rate-of-this-function-in-case-of-multi-threading
--Vipin
Please refer this KB for more details.
http://software.intel.com/en-us/articles/vml-routines-shows-a-noticeable-decrease-in-the-rate-of-this-function-in-case-of-multi-threading
--Vipin
Link Copied
2 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Seemslike the problem size is too small and that's the reason you don't see much speedup in vdSqrt. Can you increase the size of the vectorand check?
--Vipin
--Vipin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is a knownissue with MKL 10.3 and has been fixed in MKL 10.3 update 1.
Please refer this KB for more details.
http://software.intel.com/en-us/articles/vml-routines-shows-a-noticeable-decrease-in-the-rate-of-this-function-in-case-of-multi-threading
--Vipin
Please refer this KB for more details.
http://software.intel.com/en-us/articles/vml-routines-shows-a-noticeable-decrease-in-the-rate-of-this-function-in-case-of-multi-threading
--Vipin
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page