- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am running a scientific program (finite element). When I profile my code with vtune, the most time consuming function is mkl_serv_cpuhaspnr.
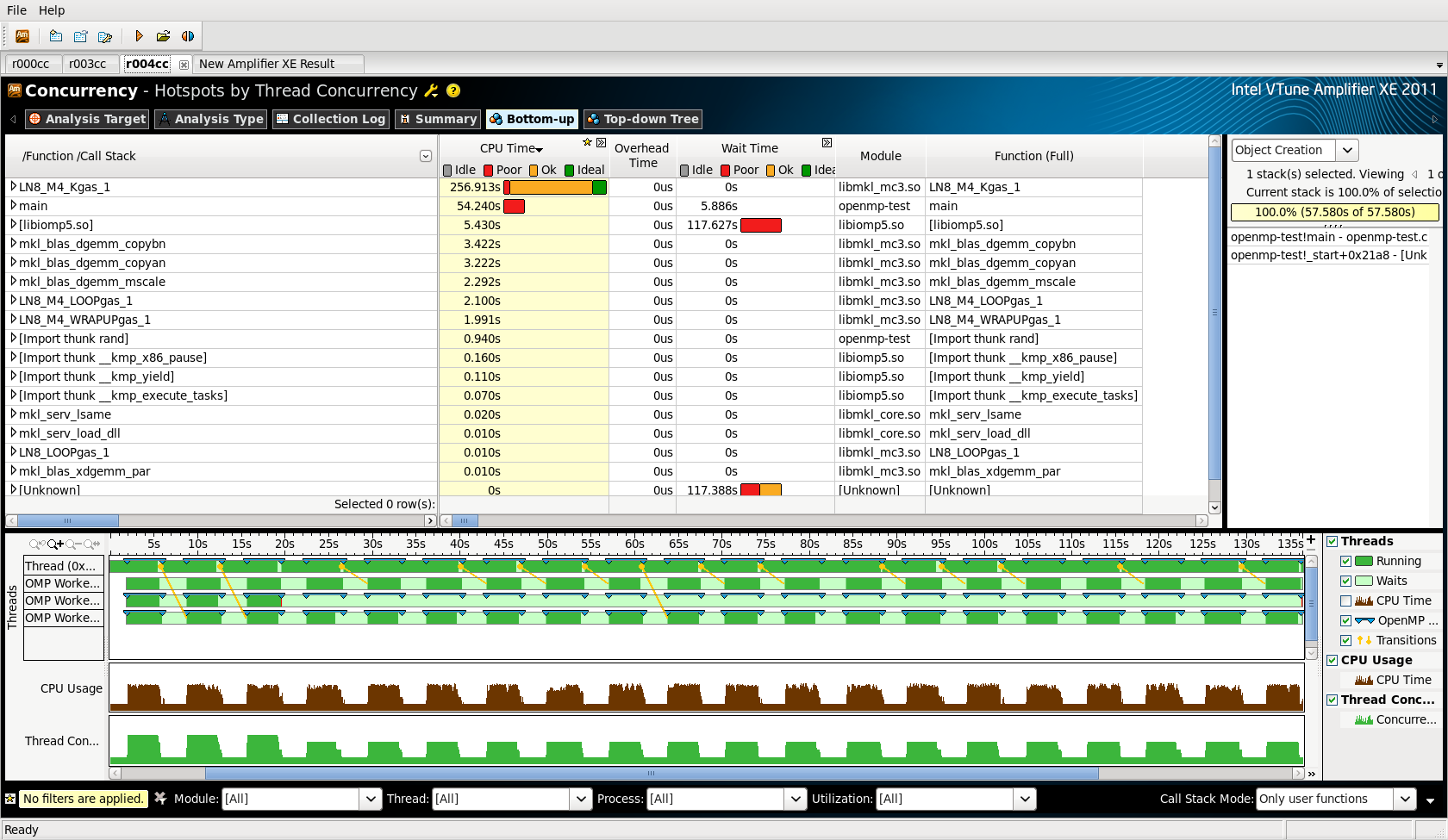
One iteration of my code shows ~2 s spent in mkl_serv_cpuhaspnr for a total run time of 20 s. And it scales with the number of iterations---that is; 10 iterations take 223 s of which 22.404s are spent in mkl_serv_cpuhaspnr. I have attached a screen capture of the summary from vtune, for the 10 iterations run.
I couldn't find much documentation about this function, except for one web site that claims that this function "Checks for SSE 4.1 (pnr=Penryn)". But then I would expect it to do it once for the entire code.
Is there a way to avoid calling this function? What does it do anyway?
My configuration:
Linux CentOS 5.5, kernel 2.6.18-194.32.1.el5
CPU: Intel Xeon CPU E5345 @ 2.33GHz
Intel Composer XE 2011 Update 3 for Linux (MKL 10.3 Update 3) (composerxe-2011.3.174)
Thanks,
David
One iteration of my code shows ~2 s spent in mkl_serv_cpuhaspnr for a total run time of 20 s. And it scales with the number of iterations---that is; 10 iterations take 223 s of which 22.404s are spent in mkl_serv_cpuhaspnr. I have attached a screen capture of the summary from vtune, for the 10 iterations run.
I couldn't find much documentation about this function, except for one web site that claims that this function "Checks for SSE 4.1 (pnr=Penryn)". But then I would expect it to do it once for the entire code.
Is there a way to avoid calling this function? What does it do anyway?
My configuration:
Linux CentOS 5.5, kernel 2.6.18-194.32.1.el5
CPU: Intel Xeon CPU E5345 @ 2.33GHz
Intel Composer XE 2011 Update 3 for Linux (MKL 10.3 Update 3) (composerxe-2011.3.174)
Thanks,
David
{kind=link}
Link Copied
5 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
David,
It's very strange that mkl_serv_cpuhaspnr takes more time than mkl_blas_dgemm. Maybe your test was run millions of times but dgemm only on very smallmatrices. Could you please describe your matrices used in your program? What parts of MKL are used there?
It's very strange that mkl_serv_cpuhaspnr takes more time than mkl_blas_dgemm. Maybe your test was run millions of times but dgemm only on very smallmatrices. Could you please describe your matrices used in your program? What parts of MKL are used there?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was doing a lot of 2x2 matrix/matrix and matrix/vector multiplications using cblas_dgemm and cblas_dgemv. I got rid of that by building my own functions and the time spent in mkl_serv_cpuhaspnr is seriously decreasing. The total run time is decreasing to.
I'll keep making the changes in my code. I didn't know that calling BLAS for small matrices was a bad idea.
Just to answer your question, I link to (sequential) MKL with the following options:
-Wl,--start-group -lmkl_intel_lp64 -lmkl_sequential -lmkl_core -Wl,--end-group -lpthread
Anyway, thanks a lot Victor for putting me on the right track.
David
I'll keep making the changes in my code. I didn't know that calling BLAS for small matrices was a bad idea.
Just to answer your question, I link to (sequential) MKL with the following options:
-Wl,--start-group -lmkl_intel_lp64 -lmkl_sequential -lmkl_core -Wl,--end-group -lpthread
Anyway, thanks a lot Victor for putting me on the right track.
David
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
David,
Yes,it's better to use direct 2x2 matrix/matrix and matrix/vector multiplications (using simpleinline) in order to eliminate huge overhead on calling of MKL functions on such small sizes. You know, MKL willgivepeak performance on medium and largetasks using parallelization.
Yes,it's better to use direct 2x2 matrix/matrix and matrix/vector multiplications (using simpleinline) in order to eliminate huge overhead on calling of MKL functions on such small sizes. You know, MKL willgivepeak performance on medium and largetasks using parallelization.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For these sizes you can try to evaluate the Intel IPP library which provide set on highly optimized functions for small matrixes calculations.The functions are optimized for operations on small matrices and small vectors, particularly for matrices of size 3x3, 4x4, 5x5, 6x6, and for vectors of length 3, 4, 5, 6.
--Gennady- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gennady,
No, for 2x2 matrices simple inline is much better than IPP functions for small sizes.
No, for 2x2 matrices simple inline is much better than IPP functions for small sizes.
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page