- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I can't seem to get the GPU to run OpenCL kernels asynchronously/in parallel, which is crucial for my use case. Without this I can't make full use of the GPU's compute resources. I use local memory so each workgroup is confined to a single subslice, and the number of workgroups in each enqueued command isn't sufficient to fill more than one subslice of the GPU anyway.
I have created a very simple test case with four tiny (but sufficiently long-running) kernels, enqueuing these kernels 100 times (with a workgroup size of 256 though I tried smaller sizes, too) across multiple queues created with CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE. I'm using no sync objects at all and using different buffers for each enqueue command so there shouldn't be any implicit synchronization at all. The test kernels don't use local memory.
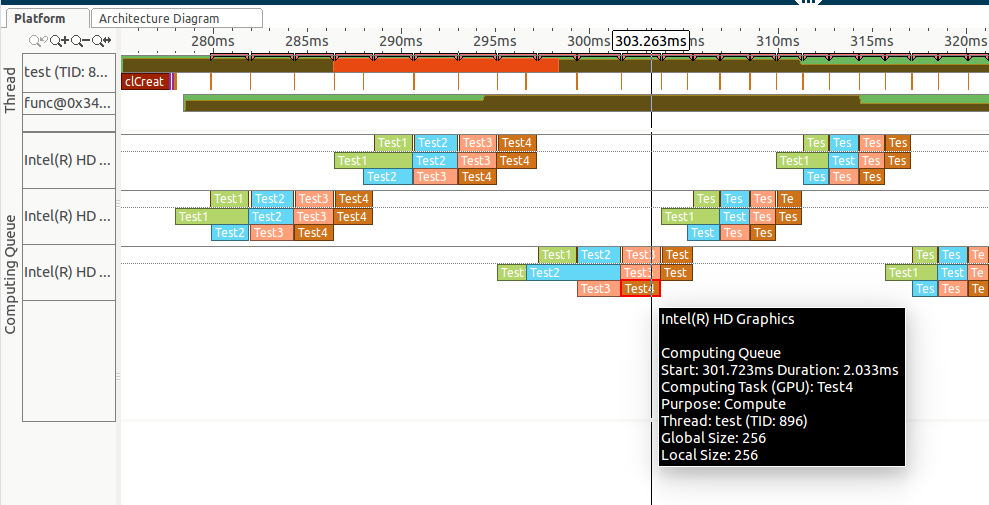
Yet when I use VTune Amplifier XE 2016 to look at GPU usage I see no overlap in GPU execution between commands, neither between kernels in the same queue nor between queues (see the attached screenshot).
What could I be doing wrong? Is this expected behaviour?
Configuration details:
Core i7-5557U with Iris 6100 GPU
Standalone Intel OpenCL drivers 1.2.1.0-47971
Ubuntu 14.04.3 LTS
Linux kernel 4.1.0 with patches from OpenCL driver package
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georg,
I discussed this issue with the implementer. He is suspecting that VTune may add event profiling implicitly.
1. Make sure that the queues don't have event profiling enabled.
2. Try to create one in-order queue and submit 1000 kernels to it + clFinish. Measure wall clock time for the actual completion.
3. Try to create one out of order queue and submit 1000 kernels to it + clFinish. Measure wall clock time and see if there is any difference.
4. If you could, please send me your original workload.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page