- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello everybody,
After three long days, I come here in search of help.
Context:
I am running a N-body code written in Fortran, using OMP directives (the only one used is a $omp parallel directive). I am running the code natively in the Xeon Phi. I am having no problem in executing the code. After much reading, I can not bring down the time execution of my code. It is fast, but not as fast as it should be. What I mean by that?
I have done a few test for two sets of particles 960 and 9600, with different flags/directives. The results show below correspond to calculate the coulomb repulsion of N particles 101 times. I averaged over the last 100 times (I through away the first run, to be sure that there is no initialization issues), I also compute the standard deviation of such 100 time executions. The results are:
1st case: Desactivate vectorizations and simd
flags = -mmic -w -O3 -opt-matmul -no-prec-div -ip -ipp -fpp -openmp -par-num-threads=240 -align array64byte -vec-report0 -no-vec -no-sim
Nparticles / average execution time / standard deviation
960 1.155452728271484E-003 5.689634014904931E-005
9600 6.604535579681396E-002 1.237208427569816E-004
2nd case: activate vectorization and sim
flags = -mmic -w -O3 -opt-matmul -no-prec-div -ip -ipp -fpp -openmp -par-num-threads=240 -align array64byte -vec-report0
Nparticles / average execution time / standard deviation
960 3.155016899108887E-004 7.613400033109344E-006
9600 2.110156297683716E-002 9.613492695550194E-005
9600 → time(-no-sim -no-vec) / time() = 3.13
960 → time(-no-sim -no-vec) / time() = 3.66
If I get it right, I should get a theoretical speed up of 8 (and not 3) in a Intel Xeon Phi (512Bits = 64Bytes at the time, that means 8 double at the time).
As you can see, I am using -align array64byte when compiling and using:
!dir$ attributes align:64
for all the long arrays (not for simple scalars)
I have read the different reports that can be generated, but they are a bit confusing for my level.
So first explicit question:
Could somebody comment on this results? Are they normal? The speed-up of a factor of 3 explained above seems ok?
Second question:
I was asking myself if I was being too picky, so I wanted to measure somehow the "flops" of my executable. And therefore I turned to Vtuen (first time using it).
I found different texts on the web of how to use it with the Xeon Phi and native applications. However none of the examples used openmp. My problem is the libiomp.so file. For example, when I execute:
/opt/intel/vtune_amplifier_xe/bin64/amplxe-cl -collect knc-lightweight-hotspots --search-dir all:/home/jofre/mic0fs -- ssh mic0 /home/jofre/mic0fs/a.out
I get an error:/home/jofre/mic0fs/a.out: error while loading shared libraries: libiomp5.so: cannot open shared object file: No such file or directory
Obviously, the file is right there. When I execute normally, I have first set
export LD_LIBRARY_PATH=/home/jofre/mic0fs
otherwise I get the same error. Someone knows what I can do to solve it?
If you read until to here, you deserve a big "thank you"!
Jofre
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just found the solution to the second question:
I have make a very simple script "lunch_exe.sh" that contains:
source /home/jofre/mic0fs/set_omp_variables_jofre.sh
./a.out
where "set_omp_variables_jofre.sh" contains:
export LD_LIBRARY_PATH=/home/jofre/mic0fs
export KMP_AFFINITY=balanced
export KMP_PLACE_THREADS=60c,4t
export OMP_NUM_THREADS=240
Know, I can use the following command:
/opt/intel/vtune_amplifier_xe/bin64/amplxe-cl -collect knc-lightweight-hotspots -- ssh mic0 /home/jofre/mic0fs/lunch_exe.sh
without issues.
At least that solved!
Jofre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jofre,
Glad to hear you muddled through getting VTune to profile your code... There's some software utility that I got working once that simultaneously puts your code on the MIC, copies all the libraries you need, and exports the variables for you but I didn't keep good enough notes to do it again, so I had to hack something together like that.
Anyways, here's my experience so far with MIC (note, I'm not doing anything huge like matrix-matrix multiplies where there are mature libraries... mine are lots of 50x50 matrix multiplies/cholesky factorizations that I had to hand-tune):
1) OpenMP support sucks compared to Cilk support. If you are doing something relatively straightforward like #pragma omp parallel for loops, it's pretty easy to convert into a cilk_for loop (at least in C... dunno about Fortran). When I did that, I got about a 2x speed up because almost all the time was spent in OpenMP thread joining operations.
2) You will have to work hard to get full vectorization, and even when I did, my dual E5-2609 (8 cores @ 2.4GHz) still beats the Xeon Phi. I haven't been able to squeeze any more performance out of the Phi version, and all the VTune metrics are green...
Hope that helps somewhat. I can't say I've had amazing success with it yet, but I'm intrigued enough by the easy programming paradigm vs. CUDA to keep an eye out for the next generation.
Andrew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1) OpenMP support sucks compared to Cilk support. If you are doing something relatively straightforward like #pragma omp parallel for loops, it's pretty easy to convert into a cilk_for loop (at least in C... dunno about Fortran). When I did that, I got about a 2x speed up because almost all the time was spent in OpenMP thread joining operations
That is almost certainly an issue of the OpenMP model and load-imbalance, not that "OpenMP support sucks". The OpenMP programming model is that there is a barrier at the join. The whole point of a barrier is to make threads wait. They have to do that somewhere, and that is inside the OpenMP runtime (in kmp_wait_sleep). The fact that you see time there does not mean that if we could speed up the barrier code you'd see a performance improvement, What it does mean is that there is load-imbalance and therefore the threads are arriving at the barrier at different times.
Load imbalance can result because either
- You simply don't have enough pieces of work in the parallel loop. (If you're using 240 threads you need around 2,400 iterations to guarantee 90% efficiency even if the pieces of work all take the same time)
- The pieces of work execute for different times, in which case a static loop schedule (which is the default) won't be able to balance them out.
So you need to
- Ensure you have enough work
- Try a different loop schedule ("schedule(guided)" is a good first guess, "schedule(dynamic)" is worth trying if there's a lot of imbalance, but it has more overhead).
The fact that you get better results with Cilk suggests that there may well be load imbalance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi James,
Fair enough, this workman shouldn't go around blaming his tools... that was just the conclusion I came to after a week of banging my head against a wall. I tried other schedules that didn't help, and then tried breaking my million iteration loop into a nested loop with the outer loop parallelized and the inner loop not which also did not help.
Could you explain (or point to documentation that explains) the difference in the Cilk model that would account for the vastly better performance?
Thanks,
Andrew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
James Cownie (Intel) wrote:
- Try a different loop schedule ("schedule(guided)" is a good first guess, "schedule(dynamic)" is worth trying if there's a lot of imbalance, but it has more overhead).
For OpenMP parallel regions where some threads get twice the average work, my cases show best results on MIC with schedule (dynamic,2) where guided is best on host. schedule(auto) may also be a workable choice. It's important to try spreading a smaller number of threads across the least busy cores, e.g. KMP_PLACE_THREADS=59c,3t, noting that 1 or 2 cores will be very busy with MPSS and OpenMP supervision. schedule(runtime) allows you to test various schedules by setting OMP_SCHEDULE.
Don't be concerned about the large numbers of OpenMP run-time instructions executed by idle threads, although it means that you will need to discover and filter in on the important working threads if profiling in VTune.
cilk_for is intended to be better suited than OpenMP for running multiple jobs simultaneously without explicitly partitioning the cores between jobs, but it doesn't turn MIC into an effectively shareable platform, nor does it compete with OpenMP when properly used.
Vectorization speedup is highly dependent on loop counts and alignments, and may be degraded by running too many threads or failing to achieve sufficient cache locality. A vector speedup of 6 for doubles is good.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply.
You are right, I did not give any details of my implementation. The key aspects of the code is that the algorithm used shares the ions equally among the threads [see http://tel.archives-ouvertes.fr/tel-00641606 for details in french sorry!] assuming that are enough of them obviously. Also, I have created my own algorithm to distribute the ions through the threads, it is stored in the variables ia2 and ib2 (see below) so openmp does not have to distribute them all the time. The subroutine looks like:
subroutine a_Coulomb_1sp( )
implicit none
!dir$ attributes align:64 :: ri
!dir$ attributes align:64 :: rji
!dir$ attributes align:64 :: rji3
!dir$ attributes align:64 :: aji
!--------------- Locals ----------------------------------------------
integer :: i, im,j, n_cut3, ii, j1, n_cut31, k
double precision, dimension(3) :: ri, rji, rji3, aji, a_aux
!-----------------------------------------------------------------------
av1 = 0.0d0
n_cut3 = n_cut(1) - mod(n_cut(1),2)
n_cut31 = n_cut3 + 1
!$omp parallel default(none) reduction(+:av1) &
!$omp private(im, i,ii,j, ri, rji, rji3, aji, j1, k, a_aux) &
!$omp shared(n_cut, xv, ia2, ib2, ia, ib, n_cut3, n_cut31)
im = omp_get_thread_num()+1
do i = ia2(im,1), ib2(im,1)
ri = xv(:,i)
a_aux = 0.0d0
do j = i+1, n_cut3
rji = xv(:,j) - ri
rji3 = (dsqrt(sum( rji**2)))**3
aji = rji / rji3
av1(:,j) = av1(:,j) + aji
a_aux = a_aux + aji
enddo
av1(:,i) = av1(:,i) - a_aux
ii = int(n_cut31-i)
ri = xv(:, ii)
a_aux = 0.0d0
do j = ii+1, n_cut3
rji = xv(:,j) - ri
rji3 = (dsqrt(sum( rji**2)))**3
aji = rji / rji3
av1(:,j) = av1(:,j) + aji
a_aux = a_aux + aji
enddo
av1(:,ii) = av1(:,ii) - a_aux
enddo
!$omp end parallel
av1(:,1:n_cut(1)) = alpha(1)*av1(:,1:n_cut(1))
end subroutine
The xv and av1 are defined in a module also using the !dir$ attributes align:64 directive.
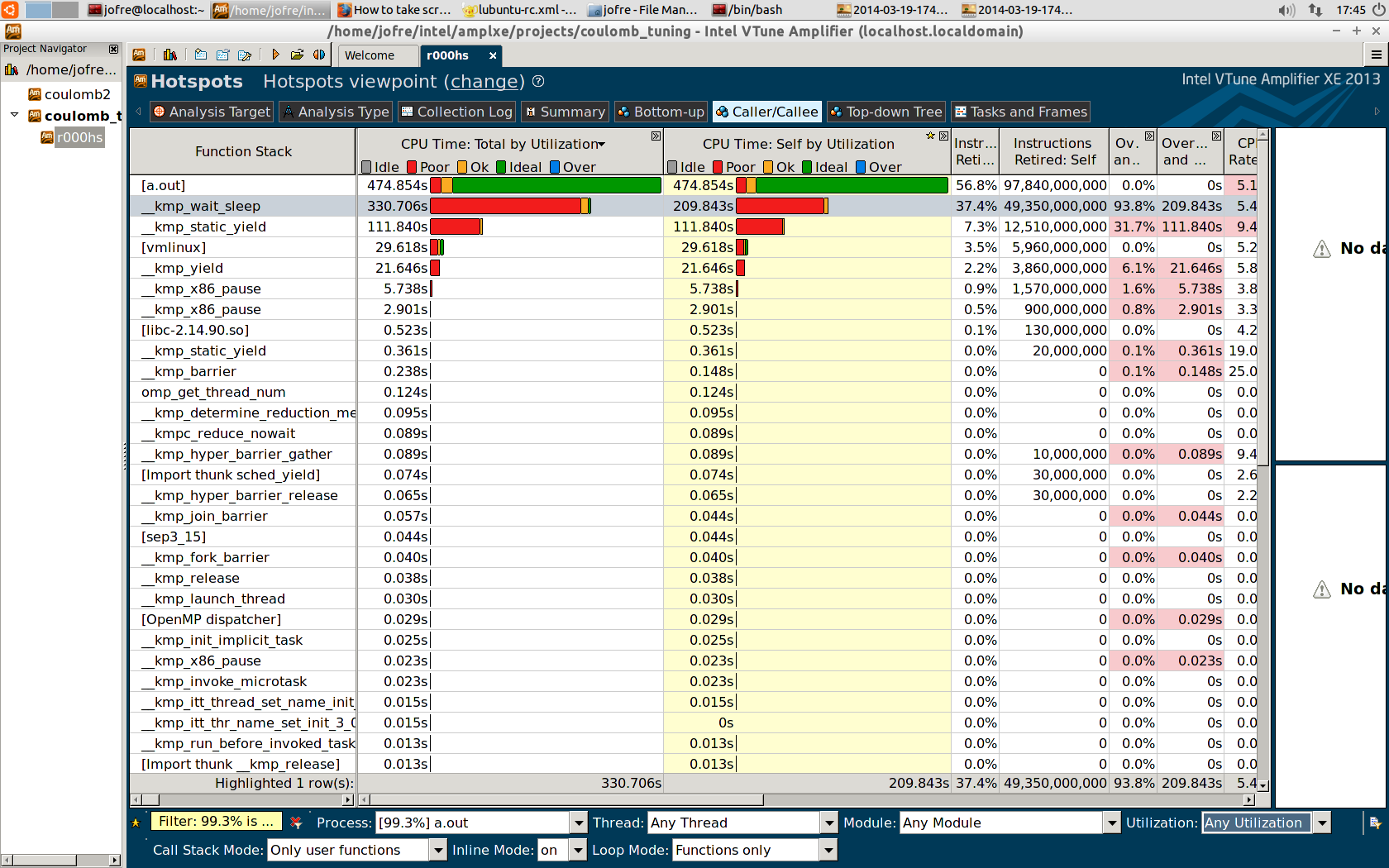
I have attached some screen-shots of the results of the Vtune. They represent good and bad news: bad news because I thought I had a highly optimized code (naive I know), good news because this means that there is, potentially, a lot of speed up to obtain!
However, a bit of insight of how to change the red into green would be welcome...
All the best, Jofre
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again,
I found an explanation to the problem of the high kmp_wait_sleep (just by chance!):
In theory in native mode I have access to the 60 cores, so 240 threads. For some reason, when running the tests from Vtune, there seem to be only 239 threads and not 240. As I had setup the code and the environment variables for 240 threads there was a huge kmp_wait_sleep. I obtained best results by changing the number of threads to 236 in the code and the environment to 59c,4t. and the kmp_wait_sleep time was reduced from 2762.8s to 323.7s (see the two screenshots of Vtune comming from the "hotspots" tests). I must say that I was calling the parallelized subroutine 1001 times.
I found in the web (http://crd.lbl.gov/assets/pubs_presos/ovsub.pdf) that OpenMP has a default waiting time of 200ms delay after each parallel section. Apparantly this waiting time can be changed (in the intel version at least) by the environment variable KMP_BLOCKTIME. I tried
export KMP_BLOCKTIME=1000
to increase and see an effect, but I did not see any appreciable difference. I must assume that I not changing the parameter, pity.
In a different register, if I run the "general exploration" test, I see that the L1 Hit Ratio is not very good.
Also, I am calculating correctly (Instruction Retired / CPU Time) I am far from the theoretical 1TFlop/s
Data collected before solving the wait_sleep issue (see above): (it should not affect the L1 Hit Ratio and Misses):
Particle L1 Hit Ratio L1 misses a_coulomb kmp_wait_sleep kmp_static_yield GFlop/s
240*2 1 0 18.719s 22.15s 11.55s 61
240*4 0.993 105,000,000 60.188s 75.34s 40.44s 164
240*8 0.960 1,288,000,000 210.084s 201.49s 108.28s 181
240*40 0.954 27,629,700,000 5816.408s 2822.69s 1461.03s 177
So, that seems like a bottleneck: if I want to have many particles per thread then L1 misses kicks in, in the other hand, if I have few ions per thread, then wait_sleep time becomes dominant!
I need to think a way out of this...
Nice day,
Jofre
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
VTune on MIC does have the effect of tieing up one core; as most Intel developers have used 61-core platforms, the implications may be evident. If you want to use all 60 cores, VTune will distort performance.
I might expect better performance if you replace 1/dsqrt(x)**3 by 1/x/sqrt(x), unless the compiler is smarter than it used to be.
The 200ms default block time (resettable by environment variable) is shared by libgomp (which I don't think is available for MIC), but there isn't a satisfactory portable way to use environment variables to control it.
L2 misses would usually be more important than L1 misses, but with such high L1 hit rates it doesn't appear that you have a problem with cache.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
KMP_BLOCKTIME should normally not be relevant on Xeon Phi, since what it does is determine how long a thread spins actively before suspending itself in the kernel. On Xeon Phi you should already be avoiding over-subscription, so it should make little difference to the performance whether a thread is spinning (with "pause" equivalents) or waiting in the kernel, since there ought to be no other threads to run on that core anyway.
So, setting KMP_BLOCKTIME=infinite ought to be fine, and seeing no effect from changing it doesn't mean that you failed to change it. (You can, of course, set KMP_SETTINGS=1 to check that you really did change it).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your comments Tim and Andrew.
The modification of 1/dsqrt(x)**3 by 1/x/sqrt(x) made little difference (maybe because x = sum(rji(1:3)**2)
However, I still do not understand one thing. If Tim is right, and I do not have a problem with the cache, why I am not able to get more than 177GFlop/s? That's very far from the theoretical 1TFlop/s! I mean, I was not expecting to obtain all the flops, but 177 is really far form it...
The problem is that I do not have suspects:
- Cache does not seems to be
- the code achieves very good load balance
It is true that the following indicators from Vtune do not seem ideal:
CPI rate 5.325
Vectorization Intensity 6.181
L1 Compute to Data Access Ratio 11.083
L2 Compute to Data Access Ratio 267.297
But my knowledge does not allow me here to progress, what I do with the above information, where I should be looking? Can anybody tell me which type of test I could do to narrow source of the problem?
Thanks,
Jofre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you will need to verify that the big loops are vectorized outside the ones with sum(rji(1:3)**2). If not, you may need !dir$ simd or to replace sum with rji(1)**2 + rji(2)**2 + rji(3)**2 (or both?).
If important loops aren't vectorized, it's too early to worry about those cache ratios. Vectorization could improve or worsen them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jofre,
Part of your lack of performance problem is the organization of your data does not lend itself well to vectorization. In particular you have:
xv(3,nParticles) and av(3,nParticles)
Then you go about manipulating the positions and accelerations. The more efficient route, for vectorization, is to use:
PosX(nParticles), PosY(nParticles), PosZ(nParticles) and AccX(nParticles), AccY(nParticles), AccZ(nParticles)
Although this necessitates more arrays, and a few more statements, the end result is better vectorization. IOW performing 8-wide vectors of doubles as opposed to 1-wide scalar computations.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page