- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
i created a simple memtest that allocate large vector that get random number and update the vector data.
pseudo code
DataCell* dataCells = new DataCell[VECTOR_SIZE]
for(int cycles = 0; cycles < gCycles; cycles++){ u64 randVal = random()
DataCell* dataCell = dataCells[randVal % VECTOR_SIZE]
dataCell->m_count = cycles
dataCell->m_random = randVal
dataCell->m_flag = 1
}
i'm using perf util to gather performance counter info.
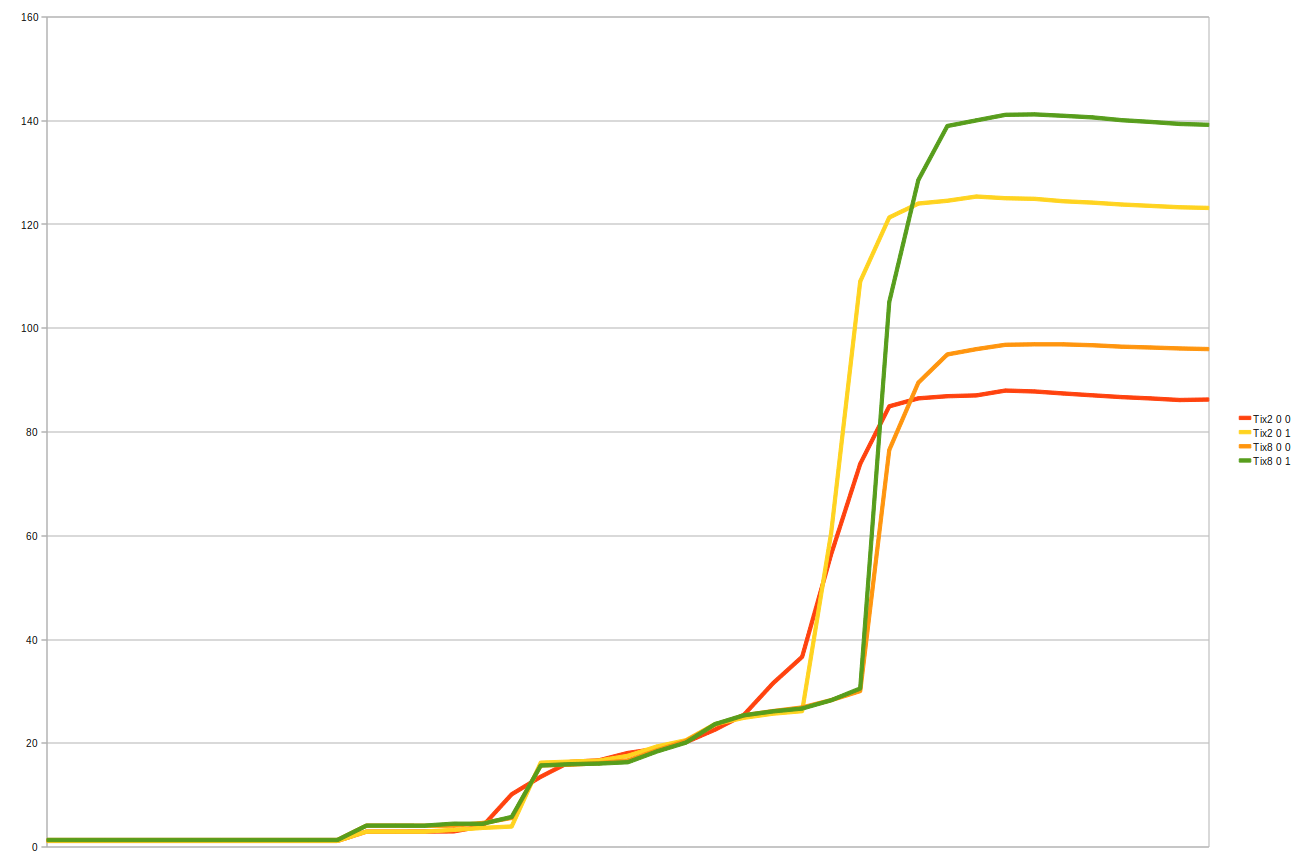
the most interesting results are when the vector size is larger then the cache size tix8 20MB tix2 12MB
hardware specification
tix2 - cpu X5680 3.33GHz, mother board - Supermicro X8DTU , memory - 64GB divided 32GB to each bank at 1.33GHz
tix8 - cpu E5-2690 2.90GHz, mother board - Intel S2600GZ, memory - 64GB divided 32GB to each bank at 1.60GHz
compiled with gcc 4.6.1 -O3 -mtune=native -march=native
amk@tix2:~/amir/memtest$ perf stat -e cycles:u -e instructions:u -e l1-dcache-loads:u -e l1-dcache-load-misses:u -e L1-dcache-stores:u -e L1-dcache-store-misses:u ./memtest -v 10000019 -c 100000000
total Time (rdtsc) 21800971556 nano time 6542908630 vector size 240000456
Performance counter stats for './memtest -v 10000019 -c 100000000':
21842742688 cycles # 0.000 M/sec
5869556879 instructions # 0.269 IPC
1700665337 L1-dcache-loads # 0.000 M/sec
221870903 L1-dcache-load-misses # 0.000 M/sec
1130278738 L1-dcache-stores # 0.000 M/sec
0 L1-dcache-store-misses # 0.000 M/sec
6.628680493 seconds time elapsed
amk@tix8:~/amir/memtest$ perf stat -e cycles:u -e instructions:u -e l1-dcache-loads:u -e l1-dcache-load-misses:u -e L1-dcache-stores:u -e L1-dcache-store-misses:u ./memtest -v 10000019 -c 100000000
total Time (rdtsc) 24362574412 nano time 8424126698 vector size 240000456
Performance counter stats for './memtest -v 10000019 -c 100000000':
24409499958 cycles # 0.000 M/sec
5869656821 instructions # 0.240 IPC
1192635035 L1-dcache-loads # 0.000 M/sec
94702716 L1-dcache-load-misses # 0.000 M/sec
1373779283 L1-dcache-stores # 0.000 M/sec
306775598 L1-dcache-store-misses # 0.000 M/sec
8.525456817 seconds time elapsed
what am is missing is Sandy bridge slower then Westmere ???????
Amir.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page