- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I measured a stream benchmark on the login node of our cluster today. The node has a Intel® Xeon® Processor E5-4650 with 4 x 8 cores.
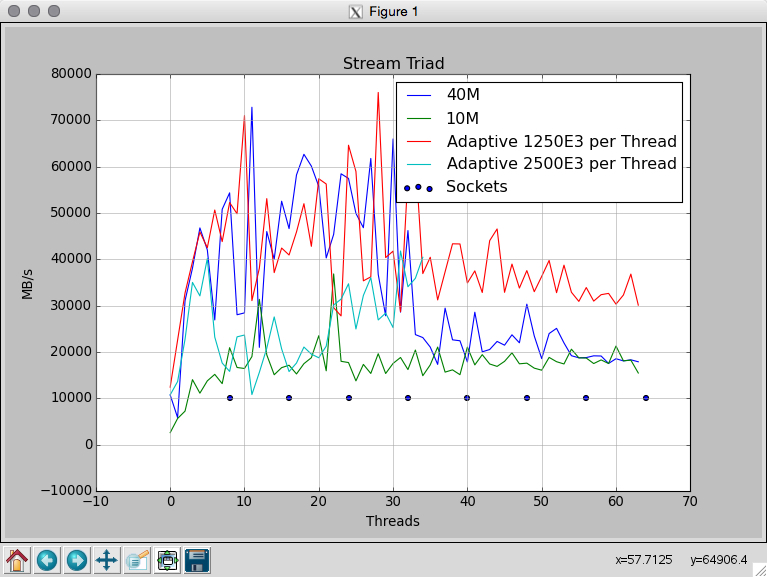
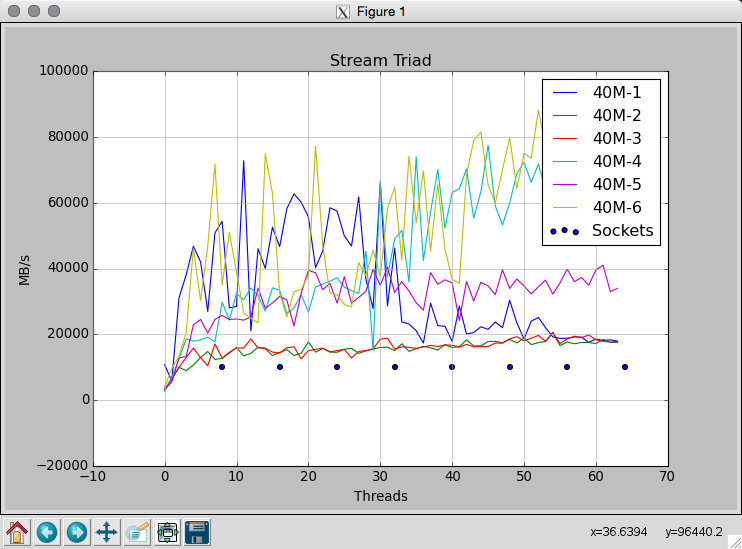
I measure multiple configurations shown in the two pictures attached. When I set the STREAM_ARRAY_SIZE to 40e6 and tune OMP_NUM_THREADS from 1 to 64, I get very noisy results. I expected this due to NUMA issues. But I measured the same configuration 6 times and I get completely different results here (shown in the second picture).
Then I changed the array size per thread in that way that I tuned STREAM_ARRAY_SIZE (compile time) and OMP_NUM_THREADS at the same time. Comparing this to having the array size fixed gives me different results.
What is the right way of doing the measurements when sweeping the number threads used? Why is the difference between measurements of the same configuration so big. Results of a benchmark should be reproducible (I guess I do something wrong).
regards
- Grischa
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You should be reading John McCalpin's advice first, as there is too much useful advice to repeat here.
Non-repeatable results are likely when you don't set affinity, e.g. OMP_PLACES=cores (when not over-subscribing), plus a setting to divide threads evenly among CPUs (if that is what you want). You will expect results to degrade when over-subscribing (HyperThreads don't help bandwidth).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Given the capabilities of the Linux OS and the capabilities of OpenMP, getting repeatable STREAM results requires a bit of extra work. This is frustrating, but once you get used to forcing thread binding the reward of repeatable performance makes it worthwhile.
I published results on a similar system in January of 2013 -- the STREAM submission contains extra instructions on exactly how to compile and run the job: http://www.cs.virginia.edu/stream/stream_mail/2013/0000.html
Repeating the instructions here -- pay extra attention to the lines in bold.
- System: Dell PowerEdge 820 --- one of the "large memory" nodes in the TACC Stampede system (c400-101 in the current configuration)
- Processors: 4 Intel Xeon E5-4650 (2.70 GHz)
- Memory: 1024 GB DDR3/1333 (32 DIMMs of 32 GB each)
- O/S: RHEL6.3 (2.6.32-279.el6.x86_64)
- Compiler: Intel icc (ICC) 13.0.1 20121010
- Compile Flags: -xAVX -O3 -ffreestanding -openmp -mcmodel=medium -DVERBOSE -DSTREAM_TYPE=double -DSTREAM_ARRAY_SIZE=30000000000
- Runtime environment: KMP_AFFINITY=compact, OMP_NUM_THREADS=32
- Execution: numactl –l ./stream.snb_O3_freestanding_double.30000M
Comments:
1. This used the new version of stream.c (revision 5.10)
2. Results were nearly identical for all suitably large array sizes (100 million to 30 billion elements per array)
3. The compiler flag –ffreestanding prevents the compiler from replacing the STREAM Copy kernel with a call to a library routine.
4. On the Xeon E5-4650, the use of streaming stores does not change STREAM performance — results were identical when compiled with -opt-streaming-stores never
5. Reported bandwidth was essentially identical when compiled for 32-bit arrays with -DSTREAM_TYPE=float.
6. IMPORTANT: If HyperThreading is enabled, switch the first KMP_AFFINITY value from "compact" to "scatter".
7. The array size used in these results does not meet the minimum size for the STREAM run rules, so please continue to use at least 40M for this system. I will show below that it does not make any difference on this particular platform, so I did not feel any need to update the published results.
Assuming that your system's memory is configured for 1333 MHz operation (which is the fastest available for the memory configuration on my system), you should get results very similar to the ones I published:
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 75539.6505 6.3555 6.3543 6.3566
Scale: 75749.1105 6.3383 6.3367 6.3405
Add: 83372.5882 8.6375 8.6359 8.6389
Triad: 83381.4416 8.6372 8.6350 8.6384
-------------------------------------------------------------
The array size here (30 million) is a bit smaller than the minimum called for by the STREAM run rules, but later tests showed that there is no significant change for larger sizes, so I did not bother to update the submission. Here is an example of the variation in performance as I change the array size from 1/2 of the minimum required size to 250 times the minimum required size:
Function Best Rate MB/s Avg time Min time Max time
20M:Triad: 84598.1141 0.0057 0.0057 0.0057
24M:Triad: 84932.9972 0.0068 0.0068 0.006830M:Triad: 85216.4027 0.0085 0.0084 0.0085
100M:Triad: 85607.5042 0.0281 0.0280 0.0282
200M:Triad: 85708.0912 0.0560 0.0560 0.0561
400M:Triad: 85795.5676 0.1120 0.1119 0.1120
600M:Triad: 85756.6469 0.1680 0.1679 0.1682
800M:Triad: 85774.0929 0.2240 0.2238 0.2240
1000M:Triad: 85743.3525 0.2800 0.2799 0.2802
2000M:Triad: 85760.2268 0.5599 0.5597 0.5601
4000M:Triad: 85771.4984 1.1198 1.1193 1.1229
6000M:Triad: 85756.7564 1.6795 1.6792 1.6802
10000M:Triad: 85755.2369 2.7992 2.7987 2.7997
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can someone point me to "Stream v0.15.20190814" ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ummm..... Never heard of it..... Maybe an internal engineering version?
The official source distribution is still http://www.cs.virginia.edu/stream/FTP/Code/stream.c (revision 5.10). The next revision will be nearly identical -- I have added one extra OpenMP pragma to parallelize the results checking in checkSTREAMresults() and have increased the default array size from 10 million elements to 80 million elements. I am still undecided about adding more "#ifdef" blocks to enable new OpenMP features (like processor binding) that only exist in OpenMP version 4 and later compilers/runtimes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have a problem to achieve 60%+ of hardware peak for intel Xeon Platinum 8558. Do you have any idea how to achieve 80% of 44 instead of given 20!
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page