- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I need some help to calculate the data misses in L1,L2 and L3 caches in intel xeon E5-2640. I use vtune to collect the events data (See the attachment). When i read the intel guide i didn't fine some events used in the formula.
Regards,
Naif
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Naif:
Make sure you are referencing the correct guide.
I assume this is a dual socket server platform? What is the "name" output for the processor? Does it include "v2" or "v3"?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
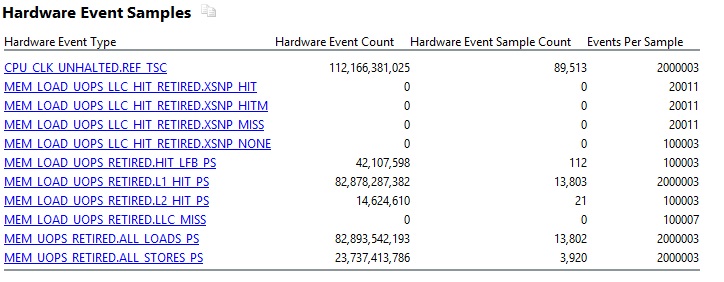
In result, counters of L1 load hits was approximated to counters of total memory loads, therefor there were less L2 memory load hits, and there was NO LLC miss for memory loads. The result did make sense!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the code was compiled with AVX vectorization and run on a Xeon E5 "Sandy Bridge" processor, then several of these events are known to count incorrectly.
This is described in section B.3.4.1 of the "Intel 64 and IA-32 Architectures Optimization Reference Manual", document 248966, revision 030, September 2013:
On 32-byte Intel AVX loads, all loads that miss in the L1 DCache show up as hits in the L1 DCache or hits in the LFB. They never show hits on any other level of memory hierarchy. Most loads arise from the line fill buffer (LFB) when Intel AVX loads miss in the L1 DCache.
Code that includes a combination 256-bit AVX loads and other loads will therefore be difficult to interpret.
VTune contains workarounds for many performance counter errata, but I don't know if it is possible to work around this bug.
When I need to understand cache hit/miss behavior using the performance counters I recompile the code so that I have a binary that uses 256-bit AVX memory references and another binary that does not -- either by forcing SSE4 compilation or by disabling vectorization with the "-no-vec" compiler flag. I run each of the codes with the hardware prefetchers enabled and with the hardware prefetchers disabled so that I can see the difference between cache hits due to re-use and cache hits due to effective prefetching. Control of the hardware prefetchers is described at:
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page