- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thank you for posting in Intel Communities.
Could you let us know whether you are using Intel DevCloud for oneAPI or Intel DevCloud for the Edge or DevCloud for FPGA ?
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi thanks, i am using intel devcloud one api kernal for python, let me know if we have a screen sharing session via google meet
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Can you please answer the following questions:
1. How often do you face this issue? Do you face this issue immediately after you launch jupyter notebook?
2. Can you run a command line interface? (via remote ssh)
Can you please try the below workarounds:
1. Delete your browser's cache and cookies and try to run in incognito mode.
2. If your application is running for longer than 6 hours, increase the "wall time." (-l walltime=hh:mm:ss)
We will connect with you through private message to get your DevCloud ID & error screenshots.
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
i am getting on immediate effect .
here is my id- (uxxxxx)

one new error message also coming like that-

it is unable to read also
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for sharing the information. We are going to inform our admin team and get back to you with an update.
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
any update?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
The issue is related to the Ray component is allocating a lot of memory which is killing the Jupyter kernel.
Workaround solution is to start Ray with memory arguments to stay within limits like :
ray.init(
_memory=16000 * 1024 * 1024,
object_store_memory=500 * 1024 * 1024,
_driver_object_store_memory=500 * 1024 * 1024)
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi i have added this:
import ray
ray.init(_memory=16000 * 1024 * 1024,object_store_memory=500 * 1024 * 1024,_driver_object_store_memory=500 * 1024 * 1024)
but still not working :
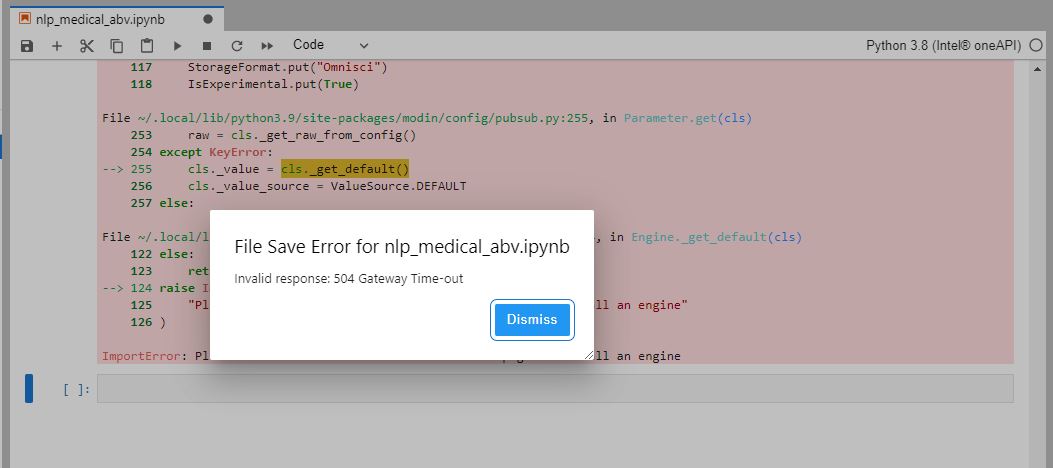
AttributeError Traceback (most recent call last) Input In [5], in <cell line: 1>() ----> 1 import ray 2 ray.init(_memory=16000 * 1024 * 1024,object_store_memory=500 * 1024 * 1024,_driver_object_store_memory=500 * 1024 * 1024) File ~/.local/lib/python3.9/site-packages/ray/__init__.py:160, in <module> 158 from ray.runtime_context import get_runtime_context # noqa: E402 159 from ray import autoscaler # noqa:E402 --> 160 from ray import data # noqa: E402,F401 161 from ray import util # noqa: E402 162 from ray import _private # noqa: E402,F401 File ~/.local/lib/python3.9/site-packages/ray/data/__init__.py:1, in <module> ----> 1 from ray.data.read_api import ( 2 from_items, 3 range, 4 range_arrow, 5 range_tensor, 6 read_parquet, 7 read_json, 8 read_csv, 9 read_binary_files, 10 from_dask, 11 from_modin, 12 from_mars, 13 from_pandas, 14 from_pandas_refs, 15 from_numpy, 16 from_arrow, 17 from_arrow_refs, 18 from_spark, 19 read_datasource, 20 read_numpy, 21 read_text, 22 ) 23 from ray.data.datasource import Datasource, ReadTask 24 from ray.data.dataset import Dataset File ~/.local/lib/python3.9/site-packages/ray/data/read_api.py:37, in <module> 28 from ray.util.annotations import PublicAPI, DeveloperAPI 29 from ray.data.block import ( 30 Block, 31 BlockAccessor, (...) 35 BlockPartitionMetadata, 36 ) ---> 37 from ray.data.context import DatasetContext 38 from ray.data.dataset import Dataset 39 from ray.data.datasource import ( 40 Datasource, 41 RangeDatasource, (...) 51 DefaultParquetMetadataProvider, 52 ) File ~/.local/lib/python3.9/site-packages/ray/data/context.py:33, in <module> 28 # Whether to furthermore fuse prior map tasks with shuffle stages. 29 DEFAULT_OPTIMIZE_FUSE_SHUFFLE_STAGES = True 32 @DeveloperAPI ---> 33 class DatasetContext: 34 """Singleton for shared Dataset resources and configurations. 35 36 This object is automatically propagated to workers and can be retrieved 37 from the driver and remote workers via DatasetContext.get_current(). 38 """ 40 def __init__( 41 self, 42 block_owner: ray.actor.ActorHandle, (...) 48 optimize_fuse_shuffle_stages: bool, 49 ): File ~/.local/lib/python3.9/site-packages/ray/data/context.py:42, in DatasetContext() 32 @DeveloperAPI 33 class DatasetContext: 34 """Singleton for shared Dataset resources and configurations. 35 36 This object is automatically propagated to workers and can be retrieved 37 from the driver and remote workers via DatasetContext.get_current(). 38 """ 40 def __init__( 41 self, ---> 42 block_owner: ray.actor.ActorHandle, 43 block_splitting_enabled: bool, 44 target_max_block_size: int, 45 enable_pandas_block: bool, 46 optimize_fuse_stages: bool, 47 optimize_fuse_read_stages: bool, 48 optimize_fuse_shuffle_stages: bool, 49 ): 50 """Private constructor (use get_current() instead).""" 51 self.block_owner = block_owner AttributeError: partially initialized module 'ray' has no attribute 'actor' (most likely due to a circular import)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I assume there is some issue while downloading the ray package.
Please follow these steps:
If you are using a Jupyter notebook use the below command:
!pip install -U rayor
If you are using terminal use the below command:
pip install -U ray
Below command to verify ray is installed properly or not:
!pip3 list | grep -i ray (Jupyter notebook)pip3 list | grep -i ray (terminal)Now import ray with the below command:
import ray
ray.init(_memory=16000 * 1024 * 1024,object_store_memory=500 * 1024 * 1024,_driver_object_store_memory=500 * 1024 * 1024)
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
new issue: not able to read csv file which can read in other local jupyter tool

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Since you gave the wrong path, I assume you're getting this error.
correct path: /home/<user_id(example: u123456)>/nlp
So the command should look like this:
df=pd.read_csv("/home/<user_id(example: u123456)>/nlp/valid.csv")Since you are in the same directory where valid.csv is present, you can also use the below command.
df=pd.read_csv("./valid.csv")
{kind=link}
If this resolves your issue, make sure to accept this as a solution. This would help others with similar issue. Thank you!
Thanks,
Jaideep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
We assume that your issue is resolved. If you need any additional information, please post a new question as this thread will no longer be monitored by Intel.
Thanks,
Jaideep
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page