- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi there,
I'm working on a project that involves Token2Token-Vision Transformer for classification task. Information on model here. During conversion from Pytorch weights to IR through onnx, some layers weren't supported with opset version 9, but I managed to export with opset version 12. INT8 & FP16 model works without any problem, but FP16 GPU inference outputs all Nan values. Is it because of version incompatibility?
I'm using the latest version of Openvino 2022.1. Please see the attached screenshot. Any suggestion would be appreciated.
Thanks and regards
iJema
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi iJema,
Thanks for reaching out.
Does the Nan values output occurs only when running on GPU? From the list of T2T-Vit Models, which specified model you are using?
Please share all the necessary files and inputs to reproduce this issue from our end. You can put all the files in Google Drive and share the link here or privately to my email:
noor.aznie.syaarriehaahx.binti.baharuddin@intel.com
Regards,
Aznie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Aznie,
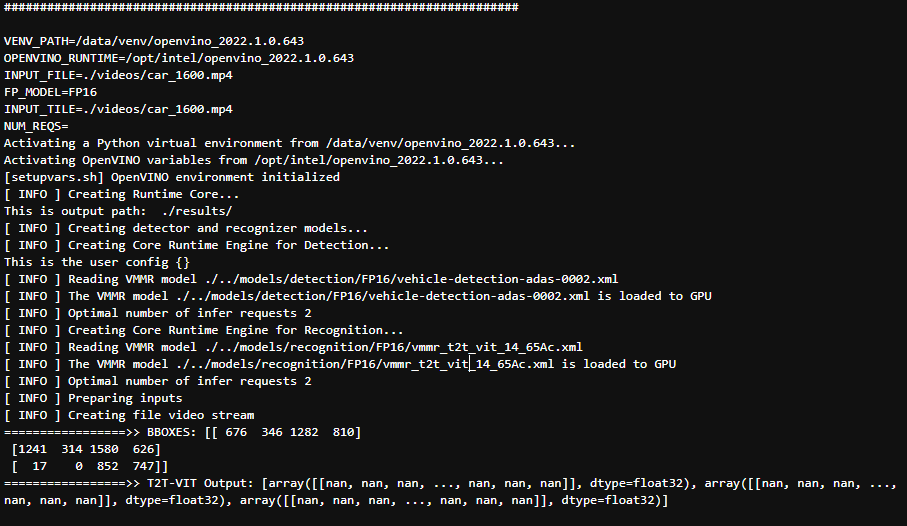
Sorry for late replying. Yes, the Nan output occurs only when running on GPU. Also, I specifically tested T2T-VIT-14 model. Please find the code here . The test_vmmr_img.py has been set up for GPU inference. Just run the file, in console you should be able to see the output from model. Please let me know if you face any problem running the code.
Thanks and regards,
iJema
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi iJema,
I observed the same output from my end and also encountered an IndexError when running the FP16 precision model on GPU.
.jpg")
{kind=link}
The performance of T2T-VIT-14 with FP16 precision on GPU was expected and the error encountered was due to missing transposes to MatMul. Our development team is working to rectify this and potentially, the fixes will be available in the next releases.
For the 2022.1 release, I would suggest you use INT8 with GPU instead.
Regards,
Aznie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry for late replying and thanks for the suggestion! I'll try the model again with next release of OpenVino.
Regards,
iJema
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi iJema,
This thread will no longer be monitored since we have provided a solution. If you need any additional information from Intel, please submit a new question.
Regards,
Aznie
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page