- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm trying to compile a model. I tried both compile_tool and the Export function, and they lead to the same result:
Inference Engine:
API version ............ 2.1
Build .................. 2021.2.0-1877-176bdf51370-releases/2021/2
Description ....... API
Network inputs:
Placeholder : FP32 / NCHW
Placeholder_1 : FP32 / NCHW
Placeholder_2 : FP32 / NCHW
Network outputs:
generator/Conv/BiasAdd/Add : FP32 / NCHW
[NOT_IMPLEMENTED]I only tried on Windows for now. Could I get some visibility on the not implemented layers? Is there a workaround (not compiling is not option for us because of the loading time on GPU)?
The network is in attachment.
Thanks in advance,
- Tags:
- compile tool
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For anyone interested, we cannot use import/export at the moment for GPU.
However, the solution was to give Openvino a cache directory to store the compiled cl kernels. This way, the kernels are generated the first time your application runs, and then will be loaded from the same directory for additional runs. This should speed-up the loading.
ie.SetConfig( { { CONFIG_KEY( CACHE_DIR ), "your_path" } }, "GPU" );
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings,
The OpenVINO Compile tool is a C++ application that enables you to dump a loaded executable network blob. The tool is delivered as an executable file that can be run on both Linux* and Windows*.
you may refer here: https://docs.openvinotoolkit.org/latest/openvino_inference_engine_tools_compile_tool_README.html
and this is guide on how to Compile the Inference-Engine Samples :
https://www.youtube.com/watch?v=6Ww_zLDGfII
Sincerely,
Iffa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Iffa,
Thanks for your answer. Unfortunately that is not my question.
I know what the compile tool is, and in fact my message is the output of this compile tool. My problem is that the compile tool returns a "NOT IMPLEMENTED" and I can't figure out why and/or what is not implemented from my network.
I posted a network so you can reproduce the problem on your end.
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm using OpenVINO version 2021.2 with Windows 10.
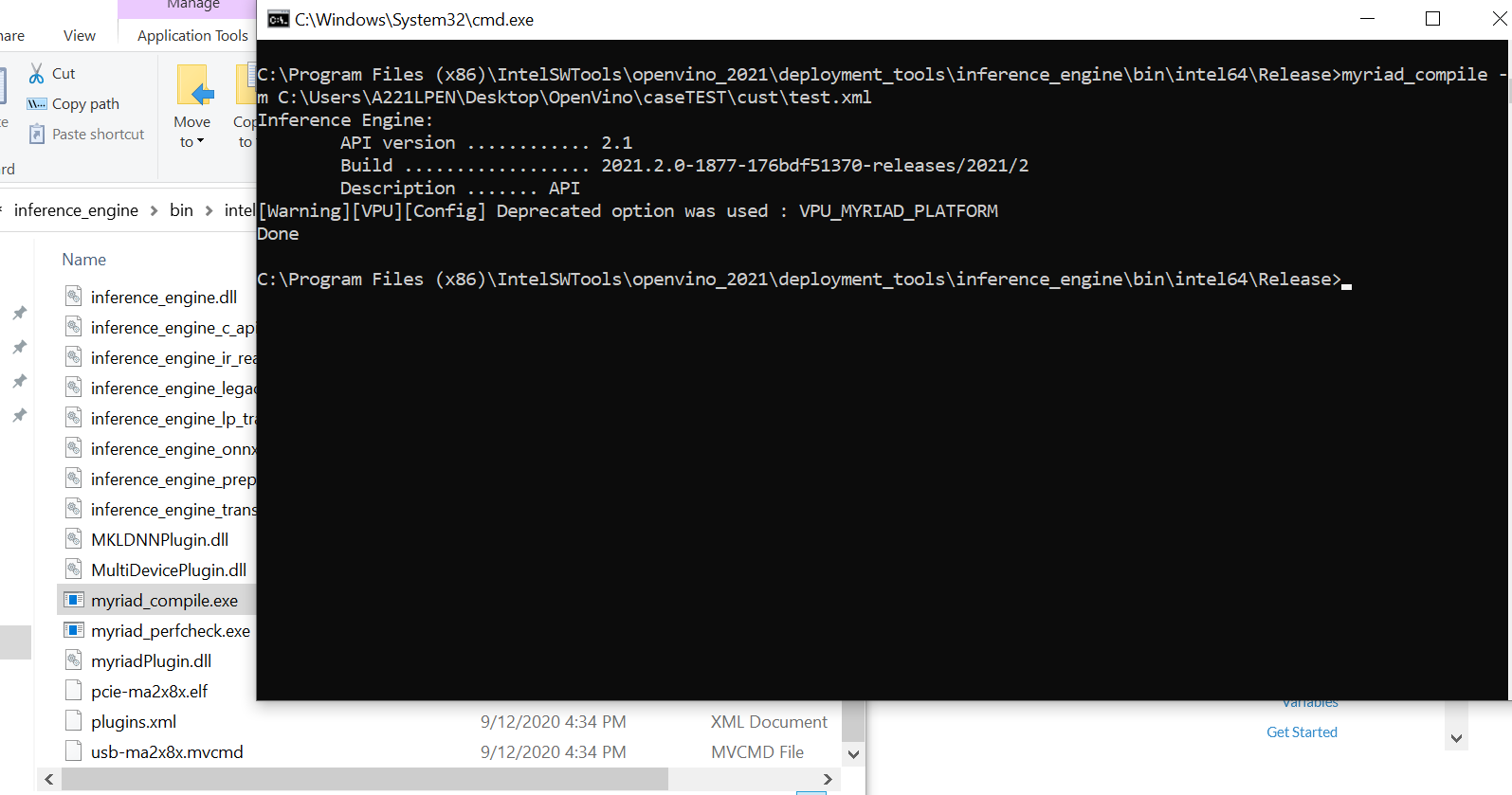
I'm able to use your file with the compile tool. However please take note that it's a myriad_compile.exe.
You can refer to my attachment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Iffa,
Ok for Myriad. But it does not help in my case for CPU and GPU, does it? Using the compile tool, I'm getting "NOT_IMPLEMENTED" for both CPU and GPU. It outputs an empty blob file.
I'm also using OpenVINO version 2021.2 with Windows 10. I also tried with linux and it leads to the same result.
Thanks
- Tags:
- Hiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you show me the location of the compile tool that you are using, together with the complete command that you use?
Sincerely,
Iffa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We are investigating this further and will update you as soon as possible.
Sincerely,
Iffa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey,
I ran into the same issue with an optimized onnx model in .bin/.xml form that can be compiled with the MYRIAD flag, but not with the cpu flag.
Just to say this once: I run an azure maschine with a xeon E5-2690, maybe there is some azure-sided virtualization in the background that messes with the -d "CPU" Flag?
Do you also use a cloud computer @nwidynski ? Did you happen to find a workaround yet?
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @nano ,
I haven't found a workaround/solution yet. I tried the compile tool on multiple local computers, -d CPU, -d GPU, and same results (no cloud computer).
My next step would be to compile OpenVino in Debug to generate the pdb and step into the code.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey @nwidynski ,
check out the github issue I opened for this problem: https://github.com/openvinotoolkit/openvino/issues/3863
Apparently compiling with the -d cpu flag is not supported currently. Compiling for CPU must be done during runtime using the IR.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @nano ,
Thanks for the ticket and the link! Ok, it makes sense for CPU. Unfortunately, I'm mainly interested on the GPU case, since loading the network compiles it, and it takes more than 30 seconds to do so for that target. I don't see how a model can be deployed with that limitation.
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For anyone interested, we cannot use import/export at the moment for GPU.
However, the solution was to give Openvino a cache directory to store the compiled cl kernels. This way, the kernels are generated the first time your application runs, and then will be loaded from the same directory for additional runs. This should speed-up the loading.
ie.SetConfig( { { CONFIG_KEY( CACHE_DIR ), "your_path" } }, "GPU" );
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings,
Fyi, as you previously heard, the compile_tool only supports Myriad, FPGA for now and myriad_compile supports only Myriad.
documents will be updated accordingly by the developer soon.
Sincerely,
Iffa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings,
Intel will no longer monitor this thread since we have provided a solution. If you need any additional information from Intel, please submit a new question.
Sincerely,
Iffa
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page