- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
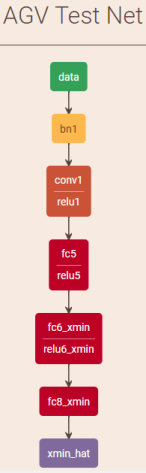
We have been using openvino for over a year. In the 2019 R2 release, we found that the model optimizer did not work as expected. The final output layer seems to have disappeared in the output model. I have attached an abbreviated example that illustrates this problem. The network is a very simple one depicted in net.png (attached). The original caffe prototxt files as well as the converted openvino model files are in the attached zip file. The output of the conversion scripts is shown below. The MO seems to finish successfully, but the output, "xmin_hat", which is present in the caffe model is absent in the openvino IR file.
Would appreciate if this can be resolved since we would like to move to the latest version.
Openvino version: 2019.2.275
OS: Ubuntu 16.04
###########################################################################
$ python3 mo.py --batch 1 --data_type FP32 --input_model caffe/simple.caffemodel --input_proto caffe/simple_deploy.prototxt --output_dir openvino
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: caffe/simple.caffemodel
- Path for generated IR: caffe.proto: mo/front/caffe/proto
- Enable resnet optimization: True
- Path to the Input prototxt: caffe/simple_deploy.prototxt
- Path to CustomLayersMapping.xml: Default
- Path to a mean file: Not specified
- Offsets for a mean file: Not specified
Model Optimizer version: 2019.2.0-436-gf5827d4
[ SUCCESS ] Generated IR model.
[ SUCCESS ] XML file: openvino/simple.xml
[ SUCCESS ] BIN file: openvino/simple.bin
[ SUCCESS ] Total execution time: 1.29 seconds.
###########################################################################
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Raghavan S,
You are correct. I reproduced this issue as well. I will file a bug on your behalf.
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Dear Raghavan S,
Some optimization happened, or "layer fusing" happened.
the layer "xmin_hat" is of type Power. This layer multiplies an elementwise input tensor with a specified value (in this topology it is 1) and adds another value elementwise (in this topology it is 0.5). This operation has been fused to the previous layer of type FullyConnected. In the initial topology it has bias equal to 0. In the converted IR it is 0.5 which is expected.
So it's not a bug, this change happened by design for optimization purposes. It should not affect the behavior of your model though - everything should still work just as before.
Hope it helps,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Shubha,
Thanks for the explanation. It makes a lot sense from an optimization point of view. But if you see from the point of view of the end user, there is still a problem:
If you run the infer request (e.g.):
out = exec_net.infer( inputs={input_blob: img_input})
The output dictionary now has the keys of the previous layer. As a result, the application code that processes the output needs to be modified since it is still looking for the previous output key. This can be inconvenient and unpredictable from a maintenance point of view especially with new releases of openvino. Further, the new output key would often not have a meaningful name making the code difficult to understand (e.g. previous output name was "xmax", while the new one is "Convolution5"). It's also not straightforward to figure out the new key value.
I request that the output key name be retained despite layer fusion so that the application code does not get affected.
Thanks
Raghavan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Raghavan S,
I think your request is reasonable. I have made this feature request on your behalf. Let's see. I will report back on this forum.
Thanks for your patience !
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Raghavan S,
Please look at the *.mapping file which gets created when you generate IR. In there, you will see this:
<map>
<framework name="xmin_hat" out_port_id="0"/>
<IR id="8" name="fc8_xmin" out_port_id="3"/>
</map>
This may be your best option to keep the "old framework name". Of course then, you'll have to add XML parsing into your app, which is kind of annoying - but that's an option.
Hope it helps,
Thanks,
Shubha
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page