- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've been playing with OpenVino WorkBench, and I quantized a ResNet. After doing so in the Kernel-Level Performance graph I noticed that I8 outputs are going straight into Quantize layers... Why is this happening? It makes no sense to me since the values are already I8...
I also noticed that OpenVino documentation does not contain a Quantize layer, only FakeQuantize. Is the former referring to the latter in the graph, or are those different things?
Yet another question: I've been trying to download the IR of the quantized model, but whenever I "Export Project" or "Create Deployment Package" it only includes the IR of the original FP32 model...
Thank you for your time!
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi PovilasM,
Thanks for reaching out. We are currently investigating this and will update you with the information soon. Meanwhile, could you share the step that you have done to quantized the ResNet in the Kernel-Level Performance graph so that we can have a detailed understanding of the issue.
Thanks
Regards,
Aznie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It seems the quantized data feeding into quantization layers only occurs on one specific model (didn't realize that before posting), and unfortunately I cannot share it due to company policy... I'll update you if I figure out what happened there.
In the meantime, I'd love to hear the answers to my other two questions.
Thank you,
Povilas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi PovilasM,
Thanks for your patience. Here is the finding for your questions.
1) I8 outputs are going straight into Quantize layers
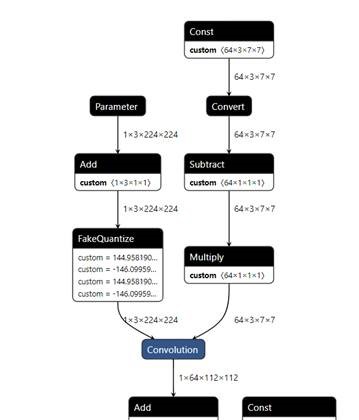
We have used Resnet-50-tf from Open Model Zoo and perform INT8 quantization on the DL workbench. As result, we don’t observe the behavior described by you in which the INT8 output goes into Quantize layer. I attached the snapshot of the layer below.
You can refer to this instruction step for the INT8 calibration.
https://docs.openvinotoolkit.org/latest/workbench_docs_Workbench_DG_Int_8_Quantization.html
2)OpenVINO documentation does not contain a Quantize layer, only FakeQuantize
Based on the latest OpenVINO (2021.3), Quantize layer has been rename to FakeQuantize layer. Also, based on this documentation quantized network describes that "FakeQuantize is a high-level overview. At runtime each FakeQuantize can be split into two independent operations: Quantize and Dequantize."
3) When "Export Project" or "Create Deployment Package" only includes the IR of the original FP32 model.
Regarding the Export Projects, you might want to click on the optimized model (INT8), the Export Projects tab, you can include model then click on Export, the model with I8 will be I8 will be download into your system. In the same step for Create Deployment Package, the optimized model will be download into your system. The instruction step available here:
https://docs.openvinotoolkit.org/latest/workbench_docs_Workbench_DG_Export_Project.html
Regards,
Aznie
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi PovilasM,
This thread will no longer be monitored since we have provided a solution. If you need any additional information from Intel, please submit a new question.
Regards,
Aznie
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page