- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello there,
We have a few questions regarding DL Workbench.
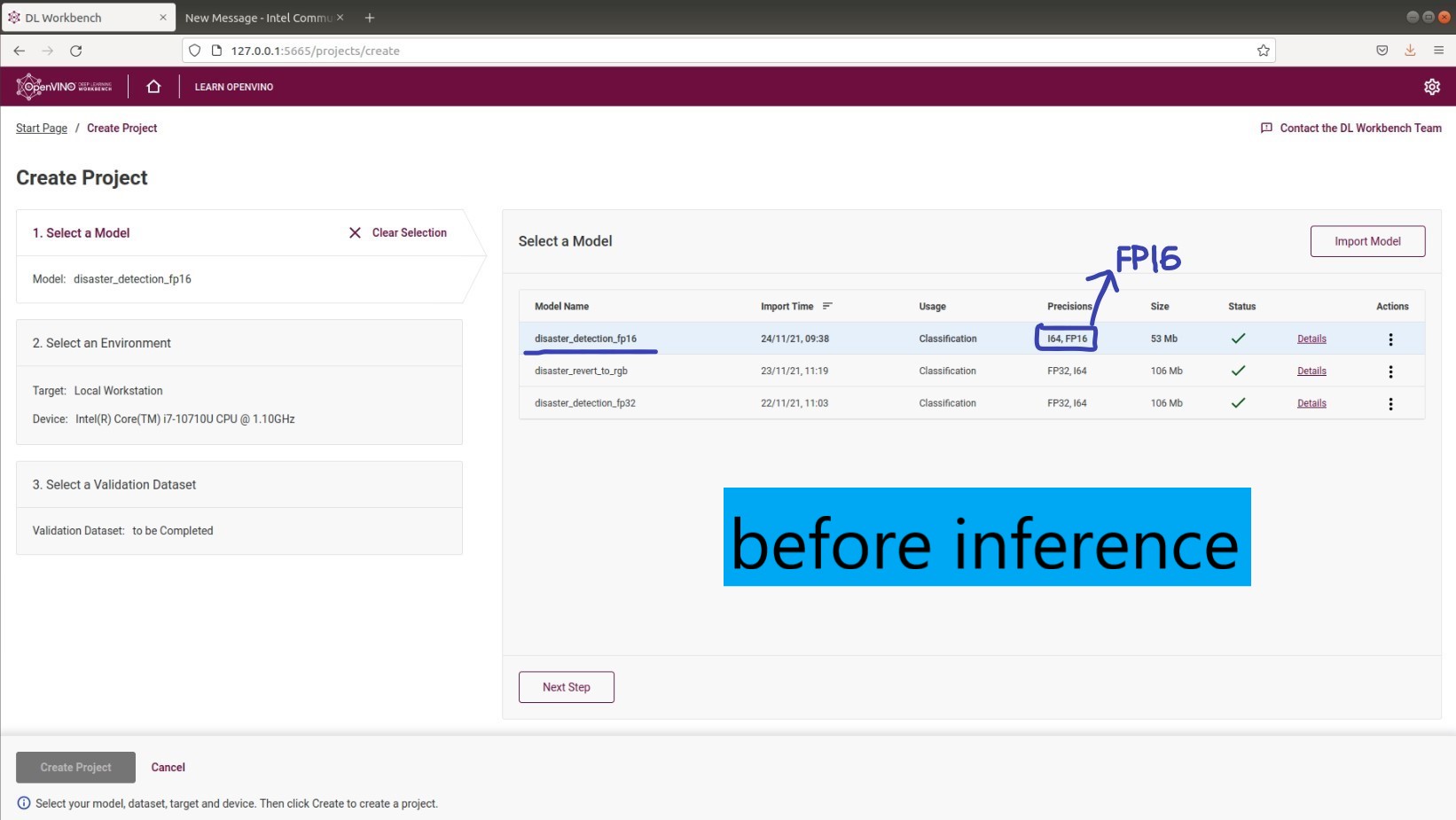
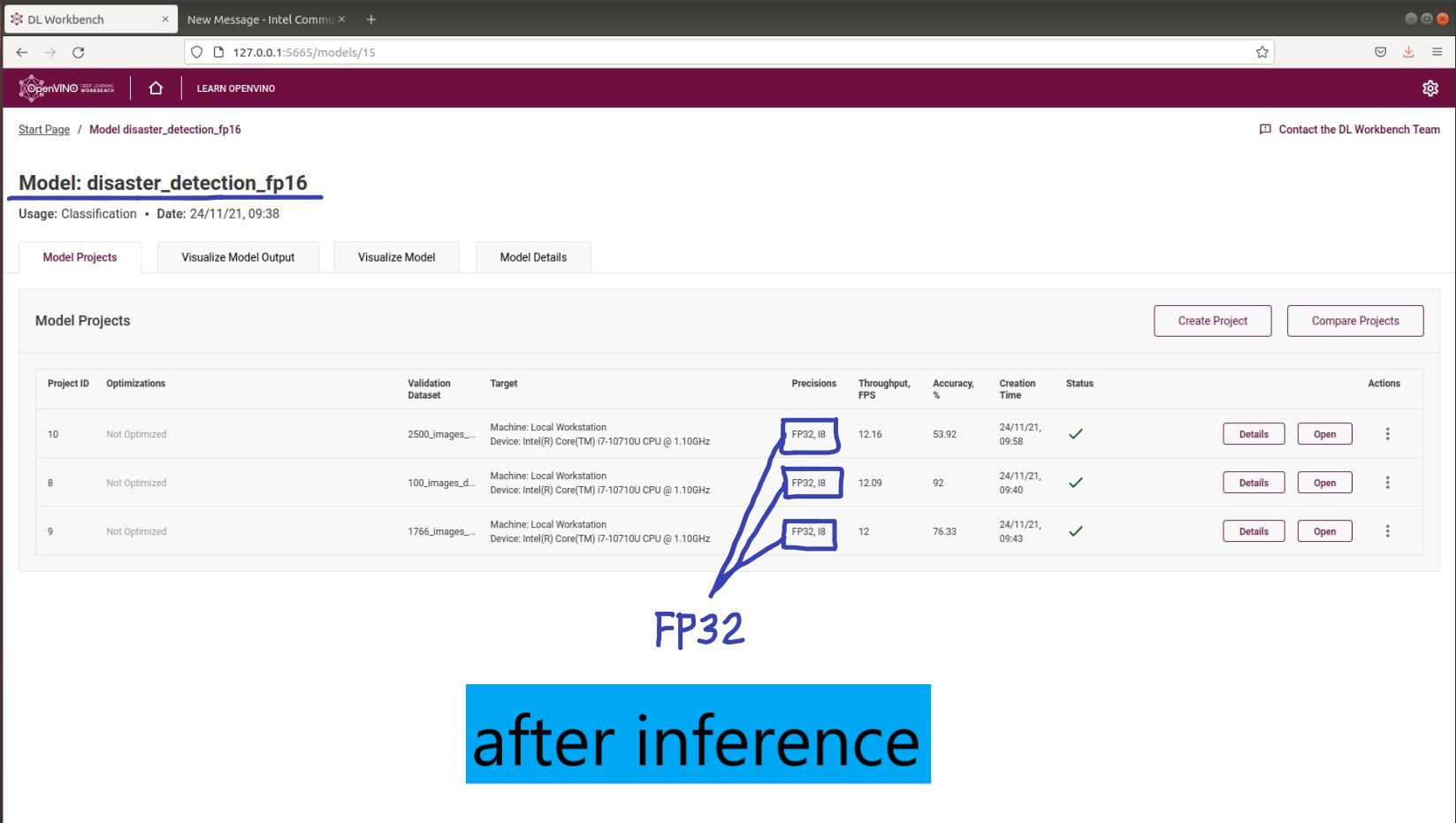
1. We have done a conversion of a TF model into OpenVINO IR (FP16) Model. The model can be seen as FP16 precision when we import it into DL Workbench (at the "Create Project" page). However, the FP16 Model automatically become FP32 after performing inference in DL Workbench. Why does this happen? Attached screenshot 001 & 002.
2. We wanted to do a performance comparison of the IR model by setting the IR model's input to BGR or RGB format. By default, the input to my IR model is in BGR format. Hence, we want to make the input to RGB format, by providing the argument "--reverse_input_channels" during the IR conversion. But, even with the argument, the model still in BGR format as shown in screenshot 003 & 004.
3. At the "Model Parameters", section "Theoretical Analysis", we assume this is the original (unoptimized) model. This assumption was made because we have converted the original model to FP32 (default) and FP16, and both of them have the exact same parameters in the "Model Parameters", section "Theoretical Analysis". The question is that, how to evaluate the performance of FP32 and FP16 models? Where can we access the similar parameters but for the optimized model? I mean for FP32 model will have more weights than that of FP16... or perhaps in terms of memory consumption. See screenshot 005 & 006.
4. Lastly, we use a python file/script when we do the inference in a terminal. We did not see any input in DL Workbench where we can use our custom python file. How do we input our custom .py file in DL workbench?
Thanks for reading my questions and any help would be great.
Regards,
nat98
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi nat98,
Regarding your questions:
1) While I can't speak with absolute certainty, the behavior you're observing may be caused by the device you choose to perform inference on. Most CPUs upscale the half precisions to full FP32 while performing inference, which may cause DL Workbench to pick up on this through Benchmark App and adjust the displayed precisions accordingly. Can you provide the hardware specifications of your device so we could look further into it?
2) To confirm, have you converted the model through DL Workbench, or through other means such as the MO CLI? This might either be a conversion page issue or a model summary bug, but in either case, could you specify the Workbench version you're using?
3) Workbench gathers the info on parameters by loading the IR into Inference Engine and analyzing the execution graph which is identical to that obtained during inference. Hence, this issue loops back to question 1) and may be caused by the inference tools accounting for the scaling of half-precisions. Again, more details on selected hardware would help to look further into this.
4) Can you provide more info on the nature of the scripts mentioned? I am not quite sure what kind of scripts you're referring to, but as far as I'm aware the only form of user scripts DL Workbench currently supports are Model Optimizer transformation configs which define changes to the graph to perform during conversion.
Regards,
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi VladimirG,
1. The device is an Intel NUC10i7FNH, with Intel Core i7-10710U CPU. 64 GB of DDR4 RAM installed.
2. We did not convert the model through DL Workbench. Model was converted using the command "python3 mo_tf.py --saved_model_dir <saved_model_dir> --output_dir <output_dir> --input_shape [1,224,224,3] --reverse_input_channels".
DL Workbench version: 1.0.3853.fa158fbb
DL Workbench Image Name: openvino/workbench:2021.4.1 (seen from the terminal)
3. If so, does DL Workbench have any tools where we can obtain the info of the (optimized) model so that we can evaluate the performance of FP32 and FP16 models?
4. What the Python script does is that it loads the model, uses a video as an input, extract the frames of the video, performs inference of each frames and label them accordingly. This is fine for normal use (performs exactly like in DL workbench). However, if we wanted the model to have a higher accuracy, for example, label an event only if the prediction probability is greater than 0.8 and label anything lower as otherwise, then the necessary codes will be written inside this Python script.
Regards,
nat98
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi nat98,
Thank you for the clarifications. Based on what I understand of the situation now, I can say the following regarding your questions:
1) Since you're performing the inference on the NUC, which doesn't have a GPU, this is indeed the issue of the Benchmark App's handling of FP16. Unfortunately, this isn't something that can be circumvented on your particular device, however if you're not tied to a specific hardware, you may want to explore DL Workbench's capabilities of working with remote targets and/or DevCloud to try and compare FP32 and FP16 performance.
2) This indeed looks like a visual bug and is something we intend to look into. That being said, I'd also like to point out that DL Workbench generally expects uploaded models to be in BGR color space as most tools in OpenVINO by default rely on OpenCV to handle image processing. This may affect things such accuracy measurements on your model, for which you'll most likely have to manually adjust the configuration.
3) As mentioned before, this question is directly tied to 1), meaning that you won't be able to evaluate the differences in theoretical data on your NUC. However, as the name implies, this data can only provide a rough estimate, and what DL Workbench provides apart from that is configurable inference using Benchmark App, visualization of execution data and quantization to INT8 using POT. Upon which note, have you been able to successfully utilize any of the mentioned features?
4) From what I gather, the script you mention operates with video data. Unfortunately, Workbench does not support video data at present, so you'll have to convert it to image form and create a dataset matching a format which supports the given task. As for the labeling part, this particular operation is not something we support, but is something that can be requested as a postprocessing feature for the Accuracy Checker tool.
Regards,
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi VladimirG,
Thanks for your reply.
1. When we run the IR model in terminal (using the Python script I mentioned), we can run the IR model in CPU or GPU by specifying "-d CPU" or "-d GPU", respectively. At the moment, we can benchmark the performance in terms of frames per second, but not accuracy. That said, does DL Workbench supports Intel GPU to perform the inference? If so, how do we make it use GPU? Do you guys have any resources (like Python script) where we can measure the accuracy on a terminal instead of DL Workbench?
More information: At the "2. Select an Environment" in DL Workbench, we only can select the CPU and no GPU selection. Note that the device has the latest Intel Graphics driver version installed as seen from the screenshot.
2. Noted.
3. We have yet to try out the POT feature. Any useful tutorials regarding the usage of Benchmark App, visualization of execution data and quantization to INT8 using POT?
4. If possible, better to have an option to input (Python file) as a postprocessing feature for the Accuracy Checker tool in the future.
Regards,
nat98
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nat98,
Thanks for reaching out to us.
DL Workbench does supports Intel GPU to perform the inference. To start DL Workbench with Python Starter, you need to use --enable-gpu argument. Please refer to Advanced DL Workbench Configurations for the complete list of command-line interface arguments for Python Starter, and additional docker run command-line options.
On another note, with the DL Workbench, you can perform INT8 calibrate your model locally, on a remote target, or in the Intel® DevCloud for the Edge. To read more about INT8 inference, see Using Low-Precision INT8 Integer Inference and Post-Training Optimization Toolkit.
On the other hand, we appreciate your request and agree that an option to input a Python file as a postprocessing feature for the Accuracy Checker tool could be a useful option to have. We will keep this feature request in mind for a future release.
Regards,
Wan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nat98,
Thanks for your question.
This thread will no longer be monitored since we have provided suggestions.
If you need any additional information from Intel, please submit a new question.
Regards,
Wan
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page