- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I am facing problem when I want to run a custom object detection Yolo v3 model in openVino.
Let me explain, I have trained a custom yolo v3 model of 3 classes, then I have generated IR files using OpenVino Documentation and successfully got .xml and .bin file. now when I try the .xml file to run in a custom video, i have got error. I am running in "python object_detection_sample_ssd.py" in this code which I have got from the "sample " folder.
I gave this command:
(OpenVino_env) C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\inference_engine\samples\python\object_detection_sample_ssd>python object_detection_sample_ssd.py -i "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/test.jpg" -m "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/frozen_darknet_yolov3_model.xml"
This is the error:
[ INFO ] Creating Inference Engine
[ INFO ] Reading the network: C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/frozen_darknet_yolov3_model.xml
[ ERROR ] The sample supports models with 1 output or with 2 with the names "boxes" and "labels"
I don't understand why I have got this error, is there anything regarding the custom Yolo file because while converting the yolo model to IR files, I have used "Yolo_v3.json" file from OpenVino Model Optimizer Folder, that file is showing 80 classes but I have only 3 classes, so is there any problem on that.
Let me know, if I have .xml and .bin file for my model, then how can I run the model in a python code on a video.
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Zian Md Afique Amin,
Thank you for reaching out. The Object Detection SSD Python* Sample required models with 1 input and 1 or 2 outputs. In the last case names of output blobs must be "boxes" and "labels".
Thus, you can have a try to run your custom model with the Object Detection Python* Demo which is the input can be images, video file, or camera id.
Regards,
Syamimi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Syamimi,
For your quick response, but can you please explain a bit on the first error "required models with 1 input and 1 or 2 outputs. I mean where exactly i have to change? and what I need to change? I didn't get the idea of the "boxes" and "Label". My model is just 3 classes or labels so where can I change that?
Please I need your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Zian Md Afique Amin,
OpenVINO has certain requirements for the demo. The Object Detection SSD Python Demo is not support the yolo-v3-tf models. The validated models for this demo are mobilenet-ssd and face-detection-0206. The Object Detection SSD Python Demo that you are running is supported 1 input and 1 or 2 outputs.
For your information, I have validated the yolo-v3-tf model on Object Detection SSD Python Demo and received the same error as you:
The sample supports models with 1 output or with 2 with the names "boxes" and "labels"
Thus, we recommend you to use the Object Detection Python Demo whereby the Yolov3 model is one of the supported models of this demo. I have also verified the Yolov3 model and it works fine with this demo.
Regards,
Syamimi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Syamimi,
Thanks for the response and solution, based on your comment I changed the python file from Object Detection SSD to Object Detection Demo, but then it ran properly but showing an error while I try to input any video.
I am giving this command to run based on the Object Detection Demo Documentation From OpenVino,
(OpenVino_env) C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\inference_engine\demos\object_detection_demo\python>python object_detection_demo.py --labels "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/coco.names" -i "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/video.mp4" -m "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/frozen_darknet_yolov3_model.xml" -at yolo
I have given the correct required files (video, model, architectures, labels), but it is showing me this errors:
[ INFO ] Initializing Inference Engine...
[ INFO ] Loading network...
[ INFO ] Reading network from IR...
[ INFO ] Loading network to CPU plugin...
MFX: Unsupported extension: C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/video.mp4
[ INFO ] Starting inference...
To close the application, press 'CTRL+C' here or switch to the output window and press ESC key
Traceback (most recent call last):
File "object_detection_demo.py", line 350, in <module>
sys.exit(main() or 0)
File "object_detection_demo.py", line 260, in main
results = detector_pipeline.get_result(next_frame_id_to_show)
File "C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\deployment_tools\open_model_zoo\demos\common\python\pipelines\async_pipeline.py", line 132, in get_result
return self.model.postprocess(raw_result, preprocess_meta), meta
File "C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\deployment_tools\open_model_zoo\demos\common\python\models\yolo.py", line 206, in postprocess
out_blob.shape = layer_params[0]
ValueError: cannot reshape array of size 172380 into shape (1,24,26,26)
One is Unsupported Video extension and another one is Video Shape error, please help me to solve these errors, how can I solve the reshape error, where I need to change the value or What I need to do? and for the Video Extension is there any specific video extension for OpenVino. Please I need your help.
For your Information, I am using OpenVino 2021 version, YoloV3 custom model with 3 classes and then converted the model in IR files to generate .cml and .bin file and now working in the video to detect custom objects. Need your help to succeed.
Thanks
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Zian Md Afique Amin,
Did you give the correct model optimizer arguments to your model ?
Refer to the following model optimizer arguments for the yolo-v3-tf model:
- --input_shape=[1,416,416,3]
- --input=input_1
- --scale_values=input_1[255]
- --reverse_input_channels
- --transformations_config=$dl_dir/yolo-v3.json
- --input_model=$dl_dir/yolo-v3.pb
Or can you please share your model with us ? So that we can try to replicate on our side.
Regards,
Syamimi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Syamimi,
I don't know where exactly I have to put this arguments, is it in the command line? or in the code. Because after train my custom model on Yolo I converted the .weights file to .xml and .bin file that's it. So automatically it have given me the file I didn't put anything manually. So Please if you think there is any file or anything that I am missing please fix them:
https://drive.google.com/drive/folders/1Wo69aPEbfohgGRmcmVHnVTBQTAaL3EJz?usp=sharing
Here, in the link you will find models(.xml, .bin. mapping), .weight file, input video.
I have worked with 3 classes of products(Coca-cola, pepsi , Sprite) detection. If everything works well then it will detect those products in the video.
Please, I need your help.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@zian123 as you probably know, YOLO model output layer dimensions depends on training parameters (number of classes is one of them). Open Model Zoo demo implemented for particular YOLO models, available from OMZ and may not work with your custom trained YOLO model because of not expected output layer dimensions. You may need to modify demo for your particular case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @Vladimir_Dudnik ,
Yes I know about the custom training parameters and based on that I have prepared the model, I gave the Class Num=3 and also changed others, then I have tested the model using Local Machine Camera, it worked perfectly and Then I have saved the model(into .weight file). Then, I tried to convert the model for OpenVino to get to good accuracy or increasing the FPS Rate.
So, actually now I didnt get where exactly I am missing the points? So in case if I need to modify the Demo, are you talking about modifying "<omz>/demos/object_detection_demo.py" this file? If so, then where to modify if my class no is 3, please let me know or help me modifying that as I have provided all the models in my previous post (google drive link given). I am trying to configuring this problems for a long time of period, so please help.
or @Syamimi_Intel I have provided the model, can you find the problems or can you try to replicate from your side. I really appreciate and need that help.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks @Eduard_Zamaliev ,
I mentioned about this in previous post back, that I didn't edit the json file. So do you thinks that's why it is giving me error.
I changed the class to 3 , Do I need to change anything else?? If not then I will try to generate the the IR files again and test it again in with the OpenVino OMZ.
| [ | |
| { | |
| "id": "TFYOLOV3", | |
| "match_kind": "general", | |
| "custom_attributes": { | |
| "classes": 3, | |
| "anchors": [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326], | |
| "coords": 4, | |
| "num": 9, | |
| "masks":[[6, 7, 8], [3, 4, 5], [0, 1, 2]], | |
| "entry_points": ["detector/yolo-v3/Reshape", "detector/yolo-v3/Reshape_4", "detector/yolo-v3/Reshape_8"] | |
| } |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, it could be an error. There is an error in your IR:
<layer id="533" name="detector/yolo-v3/Conv_14/BiasAdd/YoloRegion" type="RegionYolo" version="opset1"> <data anchors="10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326" axis="1" classes="80" coords="4" do_softmax="false" end_axis="3" mask="3, 4, 5" num="9"/> <input> <port id="0" precision="FP32"> <dim>1</dim> <dim>24</dim> <dim>26</dim> <dim>26</dim> </port> </input> <output> <port id="1" precision="FP32"> <dim>1</dim> <dim>255</dim> <dim>26</dim> <dim>26</dim> </port> </output> </layer> <layer id="534" name="detector/yolo-v3/Conv_14/BiasAdd/YoloRegion/sink_port_0" type="Result" version="opset1"> <input> <port id="0" precision="FP32"> <dim>1</dim> <dim>255</dim> <dim>26</dim> <dim>26</dim> </port> </input> </layer> </layers>
The YoloRegion (added during MO conversion) has right input shape (24x26x26), but incorrect output (255x26x26)
Also, you may change the `entry points` to the output names from .pb, but as I see you convert it well without it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So here in layer id= 533, I will change the output 255 to 24. and for the anchors and mask for anchors, how do I know that whether I need to change it or not?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No, you should NOT change any IR file, it could lead to undefined behavior. Just make changes in *.json file and rerun MO conversion, as you done before
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also, if you are using different anchors or mask for anchors, you should change them in yolo.json too.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks @Eduard_Zamaliev , I have tried to do so, I just changed the yolov3.json file, I replace the classes to 3, and then run this command to generate IR files,
python mo_tf.py --input_model "C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/frozen_darknet_yolov3_model.pb" -b 1 --tensorflow_use_custom_operations_config "C:/Program Files (x86)/IntelSWTools/openvino_2021.4.582/deployment_tools/model_optimizer/extensions/front/tf/yolo_v3.json" --output_dir "C:\Users\Md. Afique Amin Zian\Desktop\New folder"
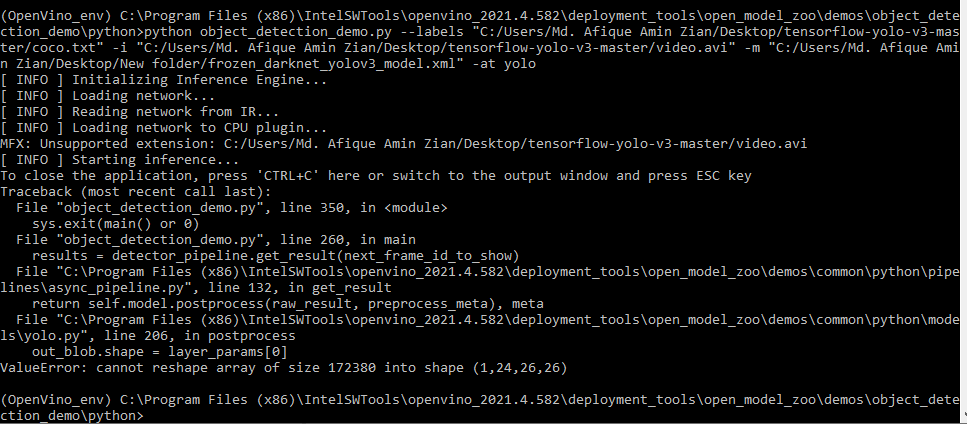
I have run it on mo_tf.py file, then get the IR files,(.xml and .bin), then I run this command to see whether its working on video file or not,
python object_detection_demo.py --labels “C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/coco.txt” -i “C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/video.avi” -m “C:/Users/Md. Afique Amin Zian/Desktop/New folder/frozen_darknet_yolov3_model.xml” -at yolo
But it is giving me the same error:
[ INFO ] Initializing Inference Engine...
[ INFO ] Loading network...
[ INFO ] Reading network from IR...
[ INFO ] Loading network to CPU plugin...
MFX: Unsupported extension: C:/Users/Md. Afique Amin Zian/Desktop/tensorflow-yolo-v3-master/video.avi
[ INFO ] Starting inference...
To close the application, press 'CTRL+C' here or switch to the output window and press ESC key
Traceback (most recent call last):
File "object_detection_demo.py", line 350, in <module>
sys.exit(main() or 0)
File "object_detection_demo.py", line 260, in main
results = detector_pipeline.get_result(next_frame_id_to_show)
File "C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\deployment_tools\open_model_zoo\demos\common\python\pipelines\async_pipeline.py", line 132, in get_result
return self.model.postprocess(raw_result, preprocess_meta), meta
File "C:\Program Files (x86)\IntelSWTools\openvino_2021.4.582\deployment_tools\open_model_zoo\demos\common\python\models\yolo.py", line 206, in postprocess
out_blob.shape = layer_params[0]
ValueError: cannot reshape array of size 172380 into shape (1,24,26,26)
There is a problems in this IR Files which I cannot figure out, today I tried with one pretrained model of OpenVIno(Vehicle-car-bike detection), when I gave the command and the .xml file, it clearly detecting from videos, but I don't know what's wrong with this Custom Model.
The new IR Files that I have got now, i saved in this link, you can refer to that and if You find any problem let me know please.
https://drive.google.com/drive/folders/1_nHYxYx2a0TJeT5AZ8SqZT7W_75QuMSG?usp=sharing
Thanks
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have also tried to compared the two IR files (Previous one with 80 classes json file and the new one with 3 classes json file), but its 9557 lines of code and I it seems the both file are same.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It seems, that MO use another, old, json instead of one with fixes, because in IR are still classes=80. Please recheck all
Also, you can try to replace the "entries" field with output names in your model PB file.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Zian Md Afique Amin,
I tried to replicate your custom model and received the same error as you.
This issue might be due to the weight size is not equal to the actual network.
There are some discussions on GitHub, you can try checking at the following link:
https://github.com/mystic123/tensorflow-yolo-v3/issues/62
If none of the suggestions in the above thread works for you, I would suggest you to:
- Prepare yolo-v3 configuration files
- Retrain your yolo-v3 model
- Reconvert weights to TensorFlow frozen model.
After that, you can use Model Optimizer to convert the TensorFlow frozen model to IR format, using the following arguments:
- --input_shape=[1,416,416,3]
- --input=input_1
- --scale_values=input_1[255]
- --reverse_input_channels
- --transformations_config=$dl_dir/yolo-v3.json
- --input_model=$dl_dir/yolo-v3.pb
Notes:
- Please give your network's input for the input shape parameter.
- Please create a new yolo-v3.json file for your custom model.
You can refer to this link as a reference to retrain the yolo-v3 custom model.
You can refer to this file when creating your own json file.
Regards,
Syamimi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hlw all,
Thanks everyone, @Syamimi_Intel @Eduard_Zamaliev @Vladimir_Dudnik .
I have successfully managed to run my Yolov3 Custom model in OpenVino Inference. Actually the problem was with the IR files(.xml file) as I while generating it I didn't change the class number in my Json file. I changed it again and then saved it, it asked for some administrative permission and then it saved successfully, then I ran the command, generate the model and then it worked in my custom video, now I know all the procedures. Thanks.
But, my model accuracy is not that much again the FPS Rate is very slow(nearly 2-3) and latency is very high, also the video that I used as an input video is not running smoothly, it is running very slowly, it looks like I play the video in Slow Motion. Can you please suggest me any idea how can I enhance the FPS rate or decrease the Latency .
Thanks In Advance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Zian Md Afique Amin,
There are several methods that you can do to increase your FPS rate such as:
- Try to reduce your video input size.
- Try to use a GPU system, or
- Change your model yolo-v3 to yolo-v3-tiny but you need to re-train the model.
You can refer to the following link to get an idea on how to increase the FPS rate:
https://towardsdatascience.com/no-gpu-for-your-production-server-a20616bb04bd
Regards,
Syamimi
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page