- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear All
Hi
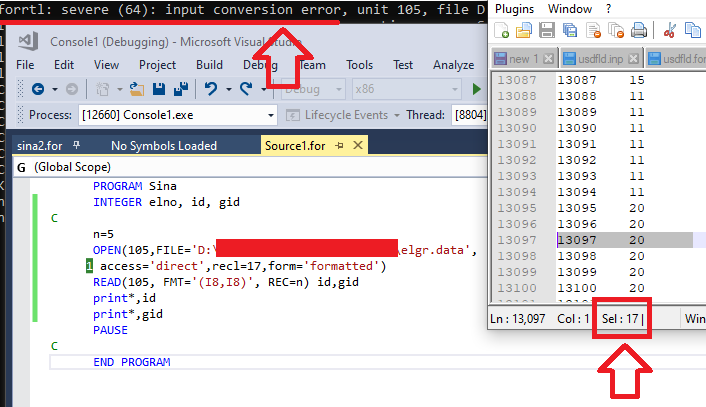
I am new to Fortran and I'm trying to read a specific line in a text file that is generated with python (numpy library).
I searched and find that maybe I can do this using direct access to a file like below:
Please see the attached image:
OPEN(105,FILE='D:\elgr.data', &
access='direct',recl=17,form='formatted')
READ(105, fmt='(I8,I8)', rec=n) id,gid
data is written to file using numpy:
two 8 width integers with space between
If you could give me some clues, I really appreciate it.
many thanks in advance
Sina
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is difficult to respond to an incomplete and vague report such as this. You have not presented the actual data file or the fortran source code, and you made it necessary to know or use Python to guess what is in the data file.
Here is my guess. The data file actually contains ten characters per line, plus one or two characters to separate lines (LF or CR+LF), because the Python print statement left-justified the data in each 8-character field. (Most text editors strip blanks from the right side of lines in text files. Text editors usually do not show "non-printable" characters, so a screen-shot of a data file opened in a text editor is hardly useful when the exact contents matter.) The result is that the actual record length is no longer 17, but something else.
I have attached a zip file containing a data file with two records, and a program that reads that file without error.
As a beginner, you would be better off using list-directed I/O using text files instead of formatted input/output statements and direct access files.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your reply and the attached files..
Unfortunately and surprisingly it can just read the first line of data and then return error:
severe (64) : input conversion error..
its kind of strange for me
I can not notice any difference between line 1 and 2...
I have attached the data file...
I really appreciate if you can take a look at it..
thank you in advance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your file contains 16000 records, and each record contains 17 bytes of data, plus CR+LF at the end of each line. If you want to continue to use direct access I/O, use RECL=19. As a check, note that 16000 X 19 = 304000, which is indeed the size of the data file in bytes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
your data is two integers separated by a set of spaces
transform it into two integers, separated by a comma using notepad++ - 20 seconds work and then do a
read(3,*)it1, it2
where 3 is file name and it1 and it2 are integers
Taking apart a record length of 19 is a pain.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think mistakenly thought:
instead of skipping lines each time with READ in loops to reach a certain line of data this is more efficient way.
I clearly know nothing about efficiency
So what's the best approach for reading a specific line in Fortran?
actually this is part of a subroutine in Abaqus software and this it will be run 16000 times (1 time for each of 16000 elements) and only 1 line of data is associated with each element
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why do you need direct access? Will you need to read the lines in sequential order, or in some other order? Will you read each line only once, or many times?
Why not read all the 16000 pairs of integers into a 16000 X 2 integer array once for all, and access those integers in the array in any order desired?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To be honest..
I thought storing them in array is not the efficient way and will consume more memory
I thought this way it only read the value from specific line (I saw other people do it with direct access so this way they could use rec number) and perform the operation on it without storing the whole data in memory..
Can you recommend something in general?
I'm just curious to know, For example next time maybe we have 500000 lines instead of 16000 lines and maybe 2 more columns then what? (Aside from tricks that we can split data in to some smaller files and etc...)
and for this exact data, do you recommend store in an array and access it?
you know I have no experience with memory allocation and these concepts
So the answer to your question is definitely my lack of knowledge
I am really thankful for your replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please answer the questions that I asked. Until you do so, we will be engaging in constructing solution methods for a problem that we have not yet defined.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks again
I'm sorry if my answer was incomplete or misleading..
I will answer your questions more explicitly:
Why do you need direct access?
I need to access nth row of a file and I found a topic here that you suggested the direct access as the solution. Before that I thought it is needed to skip lines using READ(*,*) in a loop. I was not familiar with the concept of direct access but I thought it is more efficient than storing data in an array.
Will you need to read the lines in sequential order, or in some other order?
I have a model with 16000 elements. The Fortran is going to run on each element (16000 times open and read and close file). But only 1 line of data is needed for each element (the line associated with that element ID).
Will you read each line only once, or many times?
It will read each line once and perform an operation based on that. This operation will be done only once for each element. When its done for all elements there is no need to file. For example it will read file and assign properties for each element, once its done there is no need to data anymore.
Why not read all the 16000 pairs of integers into a 16000 X 2 integer array once for all, and access those integers in the array in any order desired?
I am really new to Fortran and I though putting such a huge data in array will be consume far more memory than access it through a file (read nth line and do the operation). I thought this way it will be more efficient and faster.
Many thank for your time..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The length of your data set is the number of elements in your FEA model and there is a small number of bytes per element in your specific problem. If the number of elements to 'too big' then your analysis has far bigger problems to content with than your 16 bytes per element. Allocate an array and read the data once, the direct access file method will many times slower.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear andrew_4619
Thank you for your reply.
You are Right and I will store the data in an array.
Many Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SinaR93,
I asked:
"Why not read all the 16000 pairs of integers into a 16000 X 2 integer array once for all, and access those integers in the array in any order desired?"
and you replied:
"I am really new to Fortran and I though putting such a huge data in array will be consume far more memory than access it through a file (read nth line and do the operation). I thought this way it will be more efficient and faster."
Sorry, wrong on many counts. A PC sold today has 8 GB or more of RAM. You think that using 128 kB of that, i.e, 1/64000 of the RAM on your PC, would slow the computer down? That's like walking barefoot on sharp gravel because you don't want to distress your shoes.
Regardless of which language you program in, I suggest that you do some serious reading about RAM, storage media, sequential versus random access, etc. For instance, view the tables at this site.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear mecej4
All I was trying to tell you is that I have very little knowledge on this field and I asked your wisdom on the problem to learn. I am sorry if I annoyed you with my questions, I am deeply sorry.
Again thank you for your replies and the suggestion and your time, They helped me a lot.
I will work on the concepts that you suggested.
Many Thanks
Best
Sina
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SinaR93:
What I find irksome is your pattern of choosing a bad algorithm/technique based on absent or incorrect information, and then asking for help to make that bad design work well.
Take, for example, your statement:
I have a model with 16000 elements. The Fortran is going to run on each element (16000 times open and read and close file). But only 1 line of data is needed for each element (the line associated with that element ID).
That is a bad design, with those 16000 OPEN/CLOSE operations. It is doomed to be the cause of major delays.
Instead of making up false conjectures regarding efficiency, perhaps you should try a few test programs with different patterns of file I/O, and time them. Here is one such program.
program DirAccTest
implicit none
integer nrec,i,lrec
real :: t1, t2, t3
real, allocatable :: a(:)
integer, allocatable :: ia(:),ib(:)
!
nrec = 16000
lrec = 15 ! Gfortran
!lrec = 16 ! Ifort
allocate(ia(nrec),ib(nrec),a(nrec))
! Step 1. Generate data
call cpu_time(t1)
call random_number(a)
ia = nint(16373.0*a)
ib = nint(111.0*a)
call cpu_time(t2)
print 20,t2-t1
20 format(' Generated data in ',F7.3,' sec')
! Step 2. Write data to formatted file
open(10,file='gdat.txt',form='formatted',status='replace')
call cpu_time(t1)
write(10,15)(ia(i),ib(i),i=1,nrec)
15 format(I10,I4)
call cpu_time(t2)
print 30,t2-t1
30 format(' Wrote sequential file in ',F7.3,' sec')
! Step 3. Read file sequentially
call cpu_time(t1)
rewind(10)
read(10,'(I10,i4)')(ia(i),ib(i),i=1,nrec)
call cpu_time(t2)
close(10)
print 35,t2-t1
35 format(' Read sequential file in ',F7.3,' sec')
! Step 4. Read file in reverse order, using direct access
open(11,file='gdat.txt',access='direct',recl=lrec,status='old', &
form='formatted')
call cpu_time(t1)
do i=nrec,1,-1
read(11,fmt=40,rec=i)ia(i),ib(i)
end do
40 format(I10,I4)
call cpu_time(t2)
print 45,t2-t1
close(11)
45 format(' Read direct access file in ',F7.3,' sec')
! Step 5. As in Step 4, but in addition OPEN/CLOSE for each record
call cpu_time(t1)
do i=nrec,1,-1 ! read in reverse order
open(12,file='gdat.txt',form='formatted',status='old', &
access='direct',recl=lrec)
read(12,fmt=40,rec=i)ia(i),ib(i)
close(12)
end do
call cpu_time(t2)
print 50,t2-t1
50 format(' with OPEN/CLOSE for each rec',F6.3,' sec')
end program
Here are the results (1.1 GHz i7 gen. 10 CPU, Windows 10-64, Cygwin-64, Gfortran 10.2, files on 7200 r.p.m. HDD).
$ time /cygdrive/s/lang/diracc
Generated data in 0.000 sec
Wrote sequential file in 0.015 sec
Read sequential file in 0.000 sec
Read direct access file in 0.062 sec
with OPEN/CLOSE for each rec 2.094 sec
real 0m4.351s
user 0m0.218s
sys 0m1.968s
Note the huge burden of the avoidable OPEN/CLOSE operations, which you can see from comparing the fourth and fifth output lines.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page