- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
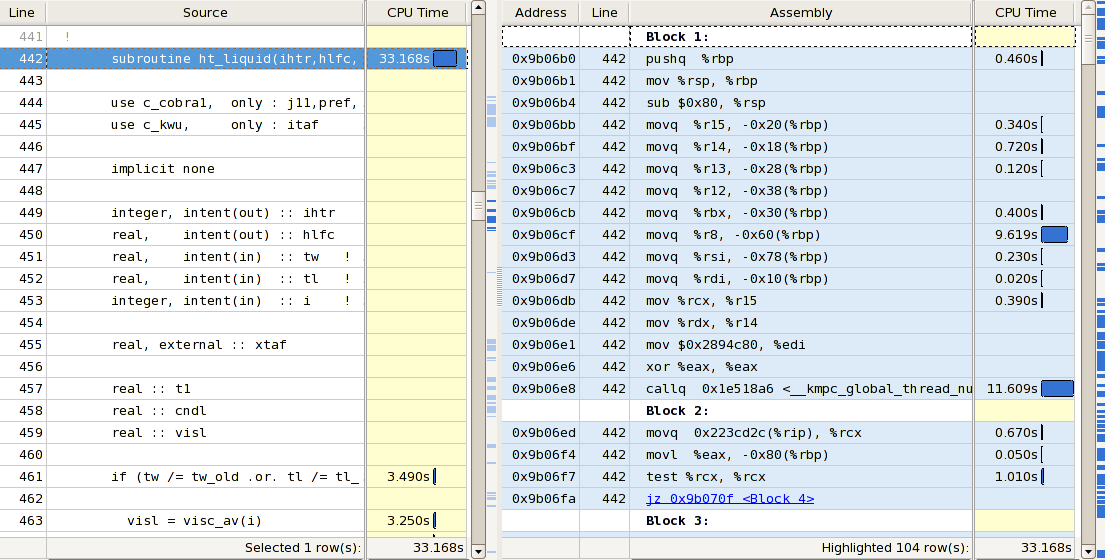
Benchmarking of an OpenMP code on a WestmereEX machine (40 cores) has exposed another instance of what I believemust befalse sharing. In this special case the problem appears to be out of direct control as it is located in the head of a subroutine, where the arguments are loaded. The subroutine takes 11 scalar arguments, 3 of them are output, the rest is input.
The assembly output of oprofile looks as follows:
The last mov instruction has an enormous amount of profile samples. Using fewer threads the sample percentage decreases which is typical for false sharing.
The question is how false sharing can occur on the stack of a thread and what can be done to avoid it.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You should expect higher hit counts for reads immediately followed by use (read to %rsi, immediately use %rsi). This stall is not necessarily false sharing.
In counting the ticks before the last mov we fine ~10000 ticks. The last mov has ~115x the number of ticks. Which would indicate that the read is not pulling from L1 cache.
Is there something you haven't told us relating to this function and what calls the function?
a) is this function located in O/S space requiring a thunk to transition from user space to O/S space?
b) is another thread on the processor, perhaps HT sibling, issuing serialization instructions (e.g. CPUID, RDTSC, ...)?
c) have you enabled one of the VTune options that track call tree information? (this may flush cache)
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I still believe it must be a cache related issue. The machine has 10 cores per socket. When running 8 to 10 threads on the same socket things are fine. As soon as I go across the socket boundary (e.g. from 10 to 12 cores) the runtime in this routine roughly doubles. And it more than doubles again when the third socket is involved.
BTW all your questions above can be answered with "no".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
115099422.4541:9a176e:mov0x10(%rbp),%rsi
1483012.8931:9a1772:cmpl$0x0,(%rsi)
The first statement above is copying what was the last argument pushed onto the stack into %rsi, which looks as if it is a reference to a variable. The second statement is testing the memory location pointed to by the reference (%rsi) against 0.
The first statement should expect to see no worse than L1 latency (typically 4 clock ticks), unless the memory port is stalled with the 5 writes to 0xoffset(%rbp). Direct read from memory of local processor is ~64 clocks, across NUMA node will add a few more per hop (in your case only 1 hop could possibly beinvolved).
What is this argument? (tell me the 1st and last argument)
Would this happen to be a shared, volatile, and high contention variable?
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page