- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm using the intel cluster toolkit on our cluster and so ifort (mpif90). I'm trying to optimize our program : I have tested gprof, oprofile and vtune (compiled with "-g -o2" or "-O3 -xT -Qdyncom"dummyblock" "). All the 3 programs show me the same result: one of our subroutine take 20% of all the time...there is a problem because this subroutine is not so important in the code.
When I take a look into the sources with vtune, I see a surprising thing:
do inp=icst,icen
su(inp)=d0
pp(inp)=d0
enddo
takes a lot of time (but the icst,icen are not sooo big)!!! All the others "do loops" for initialization take a lot of time too...
So I have decided to write this into 2 "Do loops" :
do inp=icst,icen
su(inp)=d0
enddo
do inp=icst,icen
pp(inp)=d0
enddo
I restart vtune and see that these 2 "do loop" don't take time anymore...But a new subroutine appears in the results: intel_new_memset and takes a lot of time.
How can I interprete these results ? Could someone help me to understand why in this subroutine these "do loops" are a hotsport ?
Thx a lot,
Best regards,
Guillaume
I'm using the intel cluster toolkit on our cluster and so ifort (mpif90). I'm trying to optimize our program : I have tested gprof, oprofile and vtune (compiled with "-g -o2" or "-O3 -xT -Qdyncom"dummyblock" "). All the 3 programs show me the same result: one of our subroutine take 20% of all the time...there is a problem because this subroutine is not so important in the code.
When I take a look into the sources with vtune, I see a surprising thing:
do inp=icst,icen
su(inp)=d0
pp(inp)=d0
enddo
takes a lot of time (but the icst,icen are not sooo big)!!! All the others "do loops" for initialization take a lot of time too...
So I have decided to write this into 2 "Do loops" :
do inp=icst,icen
su(inp)=d0
enddo
do inp=icst,icen
pp(inp)=d0
enddo
I restart vtune and see that these 2 "do loop" don't take time anymore...But a new subroutine appears in the results: intel_new_memset and takes a lot of time.
How can I interprete these results ? Could someone help me to understand why in this subroutine these "do loops" are a hotsport ?
Thx a lot,
Best regards,
Guillaume
Link Copied
18 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You have expressed surprise at your timing results but the information that you have given is insufficient to make me share your surprise. In particular, you have not stated:
1) the types of the variables,
2) the number of times that the subroutines are called,
3) the number of repetitions in the DO loops,
4) how the statements in question affect cache coherency, and
5) the number of times that "intel_net_memset" is called.
It is hardly surprising that the optimizer can substitute
CALL MEMSET(su,d0,(icen+1-icst)*sizeof(int))
for
do inp=icst,icen
su(inp)=d0
enddo
However, when there is more than one assignment in the DO loop, similar calls can be made only if the optimizer can ascertain that the arrays (whose elements are being set) are distinct, have no overlap, etc. The language standards may impose some restrictions on how DO loops and other constructs are compiled into machine code, particularly if the arrays are dummy arguments.
Statements such as "a lot of time" and "not important" are subjective, and can make sense only when the question "compared to what?" can be answered in each instance. It makes a difference if the surprise is caused by (i) mere novelty or (ii) failure to meet well-reasoned expectations.
1) the types of the variables,
2) the number of times that the subroutines are called,
3) the number of repetitions in the DO loops,
4) how the statements in question affect cache coherency, and
5) the number of times that "intel_net_memset" is called.
It is hardly surprising that the optimizer can substitute
CALL MEMSET(su,d0,(icen+1-icst)*sizeof(int))
for
do inp=icst,icen
su(inp)=d0
enddo
However, when there is more than one assignment in the DO loop, similar calls can be made only if the optimizer can ascertain that the arrays (whose elements are being set) are distinct, have no overlap, etc. The language standards may impose some restrictions on how DO loops and other constructs are compiled into machine code, particularly if the arrays are dummy arguments.
Statements such as "a lot of time" and "not important" are subjective, and can make sense only when the question "compared to what?" can be answered in each instance. It makes a difference if the surprise is caused by (i) mere novelty or (ii) failure to meet well-reasoned expectations.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi! thx for your answer.
1)
integer inp,icst,icen
real*8 su(nxyza),pp(nxyza)
2)
our problematic subroutine is called 8 times per time step and for our test with Vtune I have run the program with 100 time steps. So our problematic subroutine was called 800 times (confirmed by gprof).
3)
The number of repetitions is different for each thread. But here for this test:
icst=1
icen < 10000
4)
I don't understand your question, sorry. Do you mean the cache of the processor ?
our processors are:
- intel Xeon E5620: http://ark.intel.com/Product.aspx?id=47925
- intel Xeon X5650: http://ark.intel.com/Product.aspx?id=47922
So 12M of cache.
5)
Where can I see this ??? under Vtune ???
With gprof I get:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
15.19 2.65 2.65 __intel_new_memset
12.39 4.81 2.16 40000 0.00 0.00 resforward3d_
9.81 6.52 1.71 800 0.00 0.01 calcp_exp_
So I don't see how many times intel_new_memset was called.
So If I understand:
with
do inp=icst,icen
su(inp)=d0
pp(inp)=d0
enddo
The optimizer doesn't replace them with "CALL MEMSET", but with
do inp=icst,icen
su(inp)=d0
enddo
do inp=icst,icen
pp(inp)=d0
enddo
the both are replaced with this sub ?
Im' surprising with these results because the program is a fluid solver. And what takes time in a fluid solver is the fluid problem to solve...and this subroutine doesn't solve the fluid problem...There is "more" "Do loop" in the sub where the fluid system is solved as in this problematic subroutine...
Thx for your help.
Guillaume
1)
integer inp,icst,icen
real*8 su(nxyza),pp(nxyza)
2)
our problematic subroutine is called 8 times per time step and for our test with Vtune I have run the program with 100 time steps. So our problematic subroutine was called 800 times (confirmed by gprof).
3)
The number of repetitions is different for each thread. But here for this test:
icst=1
icen < 10000
4)
I don't understand your question, sorry. Do you mean the cache of the processor ?
our processors are:
- intel Xeon E5620: http://ark.intel.com/Product.aspx?id=47925
- intel Xeon X5650: http://ark.intel.com/Product.aspx?id=47922
So 12M of cache.
5)
Where can I see this ??? under Vtune ???
With gprof I get:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
15.19 2.65 2.65 __intel_new_memset
12.39 4.81 2.16 40000 0.00 0.00 resforward3d_
9.81 6.52 1.71 800 0.00 0.01 calcp_exp_
So I don't see how many times intel_new_memset was called.
So If I understand:
with
do inp=icst,icen
su(inp)=d0
pp(inp)=d0
enddo
The optimizer doesn't replace them with "CALL MEMSET", but with
do inp=icst,icen
su(inp)=d0
enddo
do inp=icst,icen
pp(inp)=d0
enddo
the both are replaced with this sub ?
Im' surprising with these results because the program is a fluid solver. And what takes time in a fluid solver is the fluid problem to solve...and this subroutine doesn't solve the fluid problem...There is "more" "Do loop" in the sub where the fluid system is solved as in this problematic subroutine...
Thx for your help.
Guillaume
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The compiler makes the automatic substitution of memset when you zero a single array. If the loop is long enough to be a major hot spot, this is a good substitution, particularly as it enables the library to decide at run time whether to use non-temporal store (bypassing the zeroing out of cache). Nontemporal is likely to come out ahead for arrays which span a large fraction of cache.
You should check whether the additional time spent by memset is less than the time saved in the caller function.
You could encourage the compiler to use nontemporal on one or both of the arrays by setting !dir$ vector nontemporal. Due to the probable impossibility of determining alignment at compile time, the loop has to be split into 2 memset calls to use nontemporal for both.
The old -xT option, in case you didn't notice it, is meant specifically for early Core 2 or Woodcrest CPUs; it's not so good for current CPUs, even if you change to current spelling.
Of course, you should check whether you need to zero the array so often, or whether you can postpone that until you are using it for other purposes.
You should check whether the additional time spent by memset is less than the time saved in the caller function.
You could encourage the compiler to use nontemporal on one or both of the arrays by setting !dir$ vector nontemporal. Due to the probable impossibility of determining alignment at compile time, the loop has to be split into 2 memset calls to use nontemporal for both.
The old -xT option, in case you didn't notice it, is meant specifically for early Core 2 or Woodcrest CPUs; it's not so good for current CPUs, even if you change to current spelling.
Of course, you should check whether you need to zero the array so often, or whether you can postpone that until you are using it for other purposes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Guillaume,
If the zeroing of these two arrays consume 20% of the run time, then either
a) the remainder of your program (the other 80%) does very little work
or
b) you may be unnecessarily zeroingout the arrays.
Note, in an MPI cluster, the controlling program alone may be performing the zeroing (initializing) of the arrays. If (icen-icst) is quite large, then consider using more than one thread to zero the arrays. If OpenMP can be blended into your app, try
!$omp parallel sections
do inp=icst,icen
su(inp)=d0
enddo
!$omp section
do inp=icst,icen
pp(inp)=d0
enddo
!$omp end parallel sections
Jim Dempsey
If the zeroing of these two arrays consume 20% of the run time, then either
a) the remainder of your program (the other 80%) does very little work
or
b) you may be unnecessarily zeroingout the arrays.
Note, in an MPI cluster, the controlling program alone may be performing the zeroing (initializing) of the arrays. If (icen-icst) is quite large, then consider using more than one thread to zero the arrays. If OpenMP can be blended into your app, try
!$omp parallel sections
do inp=icst,icen
su(inp)=d0
enddo
!$omp section
do inp=icst,icen
pp(inp)=d0
enddo
!$omp end parallel sections
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you follow Jim's suggestion, and this doesn't produce a memset substitution, you should try the !dir$ vector nontemporal. If using just 2 threads, you may need to take action to distribute the threads between CPUs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you can also experiment with disabling the call to memset with option
-nolib-inline
and see if this helps. I have seen some code where the memset is not as fast as I'd like.
ron
-nolib-inline
and see if this helps. I have seen some code where the memset is not as fast as I'd like.
ron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Out of curiosity, should there be any difference as far as the compiler is concerned between
do inp=icst,icen
su(inp) = 0.d0
end do
and
su(icst:icen) = 0.d0
in terms of optimization or performance?
Thanks,
Andrew McLeod
do inp=icst,icen
su(inp) = 0.d0
end do
and
su(icst:icen) = 0.d0
in terms of optimization or performance?
Thanks,
Andrew McLeod
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
thx for your suggestions:
- We don't want to use openMP (at the moment).
- I'm checking for each arrays if initializing is necessary.
- The "-xT" option is now removed, but I don't see any but differences. Is there an option which optimize automatically the code for the processor, where the program is compiled ? (our code is compiled and running on a lot of different platforms...and these platforms are periodically updated).
- I have tested with the "nontemporal" directive. But I don't see any improvements or differences. Could you share links about this directive and her friends. What I found on the net was not very clear (for me... :) ). So perhaps I did something wrong.
- I have tested with "-nolib-inline". The sum of the cpu time of intel_new_memset + "problematic subroutine" (without -nolib-inline) is almost equal to the cpu time of the "problematic subroutine" with "-nolib-inline". So with or without memset I have the "same" results.
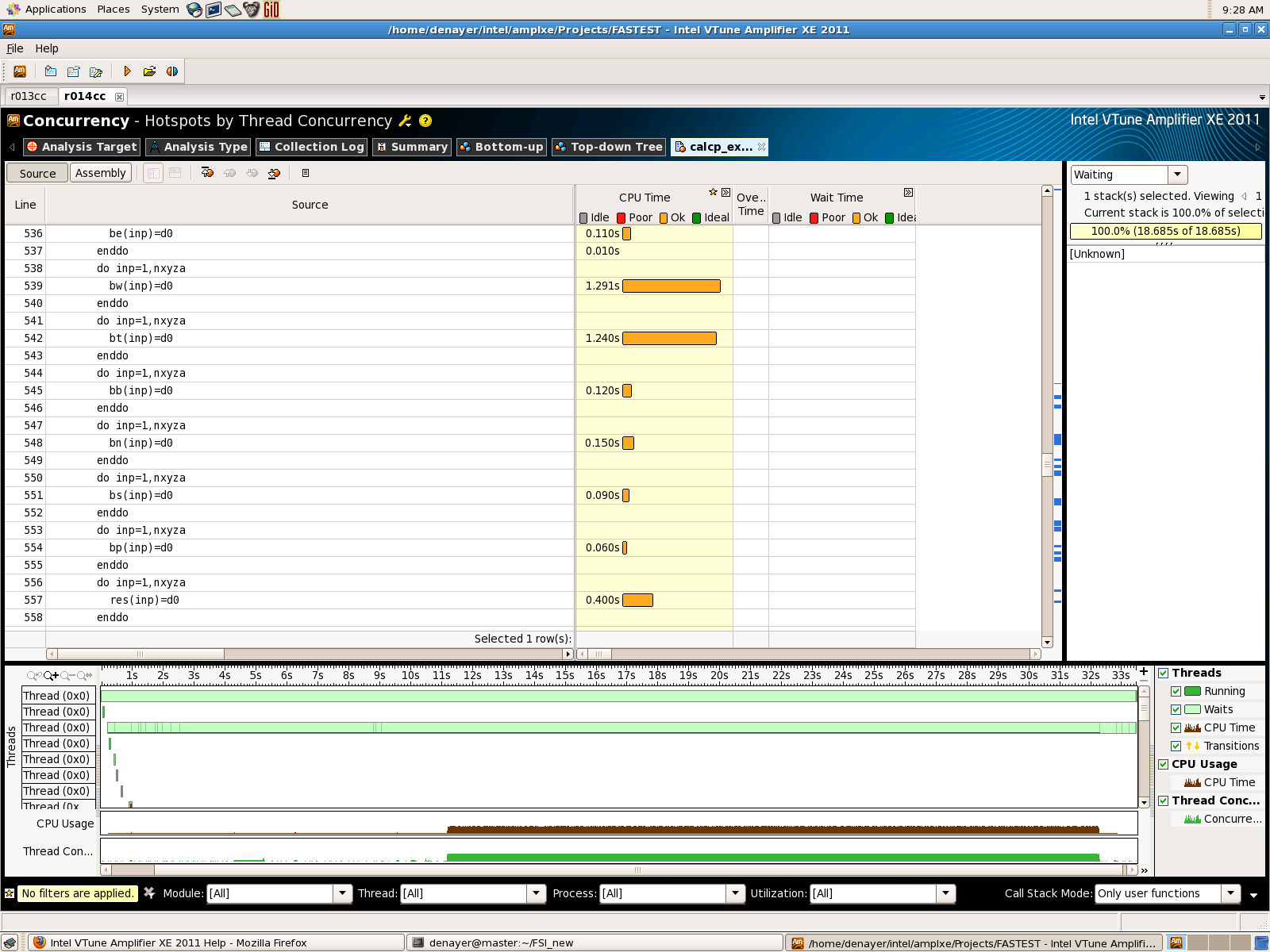
In the NEW figure in attachment, we can see 8 "DO loops" with the same number of iterations "nxyza". Why are there "DO loop", which take 10 times longer ??? (for the vectors bw and bt). Is there any influence of the previous values in the vector ? I mean, if the vector is already set to zero, goes it faster than if it is full of 10^10 ??? Or is it a problem with the place of the vectors in the memory ?
I hace tested with "su(icst:icen) = 0.d0". But I don't notice any difference.
Thx a lot for all your suggestion and your help!
Guillaume
thx for your suggestions:
- We don't want to use openMP (at the moment).
- I'm checking for each arrays if initializing is necessary.
- The "-xT" option is now removed, but I don't see any but differences. Is there an option which optimize automatically the code for the processor, where the program is compiled ? (our code is compiled and running on a lot of different platforms...and these platforms are periodically updated).
- I have tested with the "nontemporal" directive. But I don't see any improvements or differences. Could you share links about this directive and her friends. What I found on the net was not very clear (for me... :) ). So perhaps I did something wrong.
- I have tested with "-nolib-inline". The sum of the cpu time of intel_new_memset + "problematic subroutine" (without -nolib-inline) is almost equal to the cpu time of the "problematic subroutine" with "-nolib-inline". So with or without memset I have the "same" results.
In the NEW figure in attachment, we can see 8 "DO loops" with the same number of iterations "nxyza". Why are there "DO loop", which take 10 times longer ??? (for the vectors bw and bt). Is there any influence of the previous values in the vector ? I mean, if the vector is already set to zero, goes it faster than if it is full of 10^10 ??? Or is it a problem with the place of the vectors in the memory ?
I hace tested with "su(icst:icen) = 0.d0". But I don't notice any difference.
Thx a lot for all your suggestion and your help!
Guillaume
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Guillaume,
In looking at your .jpeg screenshot, the loops for bw and bt are consuming 10x the run time counts as the other loops. All the other loops were using the same extent for iterations. Therefore I suspect that bw and bt arrays may have an alignment issue. These arrays should at least be on an 8 byte boundary but may work more efficiently on a 16-byte boundary.
Run a quick check to see what the alignment of bw(1), bt(1), and the other arrays. Try to get the address in hexadecimal. If the address does not end with 0 or 8, then for some reasonthese arrays are not "naturally alligned" (not on a boundary equal to the size of the element, in this case double==8).
The other thing toconsider:
Are bw and bt arrays of doubles?
If these arrays are NOT doubles (REAL(8)) then initializing with a double (REAL(8)) will cause the loop to contain a conversion operation. This too could account for the excess run time in those loops.
Jim Dempsey
In looking at your .jpeg screenshot, the loops for bw and bt are consuming 10x the run time counts as the other loops. All the other loops were using the same extent for iterations. Therefore I suspect that bw and bt arrays may have an alignment issue. These arrays should at least be on an 8 byte boundary but may work more efficiently on a 16-byte boundary.
Run a quick check to see what the alignment of bw(1), bt(1), and the other arrays. Try to get the address in hexadecimal. If the address does not end with 0 or 8, then for some reasonthese arrays are not "naturally alligned" (not on a boundary equal to the size of the element, in this case double==8).
The other thing toconsider:
Are bw and bt arrays of doubles?
If these arrays are NOT doubles (REAL(8)) then initializing with a double (REAL(8)) will cause the loop to contain a conversion operation. This too could account for the excess run time in those loops.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
How can I get the adress in hexadecimal of bw(1), bt(1) in FORTRAN ? Could you tell me, please ?
All the arrays are doubles (REAL(8)).
Regards,
Guillaume
How can I get the adress in hexadecimal of bw(1), bt(1) in FORTRAN ? Could you tell me, please ?
All the arrays are doubles (REAL(8)).
Regards,
Guillaume
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The legacy function loc(), or the similar standard c_loc function from iso_c_binding, give you the address. You want to know whether the low order bits are zero.
IF(iand(c_loc(bw(1)),3) /= 0)write(*,*) "bw not aligned for real(8)"
As Jim pointed out, such a misalignment could account for poor performance, except that the memset substitution would apply a run-time correction, to the extent that is possible.
You could go further; if you can assure that iand(c_loc(array),7) == 0 for all arrays, you can put them all in one loop, and set
!dir$ vector nontemporal
!dir$ vector aligned
do ....
for that loop. In such a case, you could expect to gain performance by zeroing up to 8 arrays in one loop.
IF(iand(c_loc(bw(1)),3) /= 0)write(*,*) "bw not aligned for real(8)"
As Jim pointed out, such a misalignment could account for poor performance, except that the memset substitution would apply a run-time correction, to the extent that is possible.
You could go further; if you can assure that iand(c_loc(array),7) == 0 for all arrays, you can put them all in one loop, and set
!dir$ vector nontemporal
!dir$ vector aligned
do ....
for that loop. In such a case, you could expect to gain performance by zeroing up to 8 arrays in one loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Guillaume,
If you are using the debugger, it should have an option to toggle between decimal and hexadecimal. As to how you do this it depends on the debugger. In Visual Studio, you hover the mouse over the variable, it shows value in current radix, if not the radix you want, then right click (as you hover and see wrong radix value), then choose Hexadicimal.
And alternate way is to perform within the debuggera memory dump at the variable, then look at the left most column, which will show you the address in hexadecimal, the remaining columns will show the contents.
If you want to do this from within FORTRAN use the Zx[.m] edit descriptor. Something like
write(*,'(Z20)') loc(array(1))
Alternativley, remember we are looking for the data alignment as opposed to actual address, use
write(*,*) mod(loc(array(1)),16)
A return value of 0 or 8 is good, anything else and you (somehow) have an alignment issue.
Note, when 0, the array access using the SSE vector instructions (compiler does this for you) may be a tad faster. Don't worry about the aligned to 16 issue until later.
By the way, were the two arrays in question arrays of doubles (real(8))?
Jim Dempsey
If you are using the debugger, it should have an option to toggle between decimal and hexadecimal. As to how you do this it depends on the debugger. In Visual Studio, you hover the mouse over the variable, it shows value in current radix, if not the radix you want, then right click (as you hover and see wrong radix value), then choose Hexadicimal.
And alternate way is to perform within the debuggera memory dump at the variable, then look at the left most column, which will show you the address in hexadecimal, the remaining columns will show the contents.
If you want to do this from within FORTRAN use the Zx[.m] edit descriptor. Something like
write(*,'(Z20)') loc(array(1))
Alternativley, remember we are looking for the data alignment as opposed to actual address, use
write(*,*) mod(loc(array(1)),16)
A return value of 0 or 8 is good, anything else and you (somehow) have an alignment issue.
Note, when 0, the array access using the SSE vector instructions (compiler does this for you) may be a tad faster. Don't worry about the aligned to 16 issue until later.
By the way, were the two arrays in question arrays of doubles (real(8))?
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
pfiouuuuu too many new FORTRAN functions in 2 days ?!? :D
I have tried:
IF(iand(loc(bw(1)),3) /= 0)write(*,*) "bw not aligned"
and the same for all my arrays...NO PROBLEM.
I have tried too:
write(*,*) mod(loc(array(1)),16)
And the results for all the arrays are 0.
So I don't have any problem with alignment for these vectors.
I have tried to use the directives with untemporal and aligned...But it seems slower.
I found that a lot of the initialising loops are not necessary in our code. So the program runs 10% faster now :D.
Generally if I have a loop so:
do k=1,nkm
do i=1,nim
do j=1,njm
inp=ha(i,j,k)
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
enddo
enddo
enddo
Is it better to write this in 3 times ?
Thx for all your suggestions!!!
pfiouuuuu too many new FORTRAN functions in 2 days ?!? :D
I have tried:
IF(iand(loc(bw(1)),3) /= 0)write(*,*) "bw not aligned"
and the same for all my arrays...NO PROBLEM.
I have tried too:
write(*,*) mod(loc(array(1)),16)
And the results for all the arrays are 0.
So I don't have any problem with alignment for these vectors.
I have tried to use the directives with untemporal and aligned...But it seems slower.
I found that a lot of the initialising loops are not necessary in our code. So the program runs 10% faster now :D.
Generally if I have a loop so:
do k=1,nkm
do i=1,nim
do j=1,njm
inp=ha(i,j,k)
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
enddo
enddo
enddo
Is it better to write this in 3 times ?
Thx for all your suggestions!!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
do k=1,nkm
do i=1,nim
do j=1,njm
*** reorder indexes on ha to inner do loop to outer do loop order
*** IOW ha(j,i,k)
*** or reorderpreceeding loops to order k,j,i
inp=ha(i,j,k)
*** see notes below
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
enddo
enddo
enddo
If(nkm * nim * njm) is relatively large .AND. the above loopconsumes a considerable portion of run time, consider the following
logical(1) :: haIndex(nkm * nim * njm)
...
haIndex =.false. ! set index found to .false.
do k=1,nkm
do j=1,nim
do i=1,njm
haIndex(ha(i,j,k) = .true.
end do
end do
end do
do inp = 1,nkm * nim * njm
if(haIndex(inp)) then
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
endif
end do
Jim Dempsey
do i=1,nim
do j=1,njm
*** reorder indexes on ha to inner do loop to outer do loop order
*** IOW ha(j,i,k)
*** or reorderpreceeding loops to order k,j,i
inp=ha(i,j,k)
*** see notes below
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
enddo
enddo
enddo
If(nkm * nim * njm) is relatively large .AND. the above loopconsumes a considerable portion of run time, consider the following
logical(1) :: haIndex(nkm * nim * njm)
...
haIndex =.false. ! set index found to .false.
do k=1,nkm
do j=1,nim
do i=1,njm
haIndex(ha(i,j,k) = .true.
end do
end do
end do
do inp = 1,nkm * nim * njm
if(haIndex(inp)) then
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
endif
end do
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quoting Guillaume De Nayer
Generally if I have a loop so:
do k=1,nkm
do i=1,nim
do j=1,njm
inp=ha(i,j,k)
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
enddo
enddo
enddo
Is it better to write this in 3 times ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I forgot to add to my prior post of using a table of logicals (for which elements get calculated)
The reason for the use of the haIndex array is when processing the computation loop the be(inp)= ...are sequential (with skips for unmarked entries). This is friendlier to cache utilization.
When the runs of .true.'s and/or .false.'s are relatively long, then consider using an array of integers in place of the logical arraycontaining:
+n == n .true.'s
-n == n .false.'s
0 == end of table (or you can use a count)
With this table computed, then the do loop to compute the values always cover a sequential range IOW no if test in the do loop. Eliminating the if test will improve the vectorability of the code.
iFill = 1
iPick = 1
do while(counts(iPick) .ne. 0)
if(counts(iPick) .gt. 0) then
do inp=iFill,iFill+counts(iPick)-1
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
end do
iFill = iFill + counts(iPick)
else
iFill = iFill- counts(iPick)
endif
iPick = iPick+1
end do
Jim Dempsey
The reason for the use of the haIndex array is when processing the computation loop the be(inp)= ...are sequential (with skips for unmarked entries). This is friendlier to cache utilization.
When the runs of .true.'s and/or .false.'s are relatively long, then consider using an array of integers in place of the logical arraycontaining:
+n == n .true.'s
-n == n .false.'s
0 == end of table (or you can use a count)
With this table computed, then the do loop to compute the values always cover a sequential range IOW no if test in the do loop. Eliminating the if test will improve the vectorability of the code.
iFill = 1
iPick = 1
do while(counts(iPick) .ne. 0)
if(counts(iPick) .gt. 0) then
do inp=iFill,iFill+counts(iPick)-1
be(inp)=pp(inp)*(1.-fx(inp))+pp(inp+idew)*fx(inp)
bn(inp)=pp(inp)*(1.-fy(inp))+pp(inp+idns)*fy(inp)
bt(inp)=pp(inp)*(1.-fz(inp))+pp(inp+idtb)*fz(inp)
end do
iFill = iFill + counts(iPick)
else
iFill = iFill- counts(iPick)
endif
iPick = iPick+1
end do
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@jimdempseyatthecove
ha(j,i,k) is not an array. But a function:
ha(ii,jj,kk)=lk(kk)+li(ii)+jj
So it is not a problem to use:
do k=1,nkm
do i=1,nim
do j=1,njm
inp=ha(i,j,k)
enddo
enddo
enddo
it is a little strange...I know, but the previous developpers choose this way.
@all
I'm experimenting your suggestions for the loops.
ha(j,i,k) is not an array. But a function:
ha(ii,jj,kk)=lk(kk)+li(ii)+jj
So it is not a problem to use:
do k=1,nkm
do i=1,nim
do j=1,njm
inp=ha(i,j,k)
enddo
enddo
enddo
it is a little strange...I know, but the previous developpers choose this way.
@all
I'm experimenting your suggestions for the loops.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>ha(j,i,k) is not an array. But a function:
ha(ii,jj,kk)=lk(kk)+li(ii)+jj
Then assuming lk() and li() are arrays you would want the j index of the caller's loop to be the inner most loop (as-was written). It would not hurt to add a comment explaining this at the point in the code where the function call is made. This would serve as a notice to the next person supporting this code such that they will not make the same generalization mistake that I did.
Building the table of LOGICALS indicating referenced/not referenced, then building using that list to discover adjacent .true.'s and adjacent .false.'s might be sufficient (i.e. table of counts can be omitted)
haPicked = .false.
do k=1,nkm
do i=1,nim
do j=1,njm
haPicked(ha(i,j,k)) = .true.
enddo
enddo
enddo
last = .false.
count = 0
inp = 1
do i=1,nkm*nim*njm
if(last) then
! last was .true.
if(haPicked(i)) then
! increment count of .true.'s in a row seen
count = count+1
else
! end of .true.'s in a row
! now compute results for those entries
do j=1,count
bt(inp) = ...
...
...
end do
inp = inp + count
count = 0
last = .false.
endif
else
! last was .false
if(haPicked(i)) then
! switching from .false.'s to .true.('s)
! advance over .false.'s
inp = inp + count
last = .true.
count = 1
else
count = count + 1
endif
endif
end do
if(last) then
do j=1,count
bt(inp) = ...
...
...
end do
endif
something like the above would work.
Jim Dempsey
ha(ii,jj,kk)=lk(kk)+li(ii)+jj
Then assuming lk() and li() are arrays you would want the j index of the caller's loop to be the inner most loop (as-was written). It would not hurt to add a comment explaining this at the point in the code where the function call is made. This would serve as a notice to the next person supporting this code such that they will not make the same generalization mistake that I did.
Building the table of LOGICALS indicating referenced/not referenced, then building using that list to discover adjacent .true.'s and adjacent .false.'s might be sufficient (i.e. table of counts can be omitted)
haPicked = .false.
do k=1,nkm
do i=1,nim
do j=1,njm
haPicked(ha(i,j,k)) = .true.
enddo
enddo
enddo
last = .false.
count = 0
inp = 1
do i=1,nkm*nim*njm
if(last) then
! last was .true.
if(haPicked(i)) then
! increment count of .true.'s in a row seen
count = count+1
else
! end of .true.'s in a row
! now compute results for those entries
do j=1,count
bt(inp) = ...
...
...
end do
inp = inp + count
count = 0
last = .false.
endif
else
! last was .false
if(haPicked(i)) then
! switching from .false.'s to .true.('s)
! advance over .false.'s
inp = inp + count
last = .true.
count = 1
else
count = count + 1
endif
endif
end do
if(last) then
do j=1,count
bt(inp) = ...
...
...
end do
endif
something like the above would work.
Jim Dempsey
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page