- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
I'm learning openmp and Lattice Boltzmann Method(LBM). I modified the example LBM program 'F90-bgk' a little and analyzed it with Amplifier Vtune. The results revealed that the 'computeFeq' 'collide' 'stream' 'computeMacros' subroutines took up most of the cpu usage, so i tried to parallel them with openmp. But the performance of the parallel code is even worse than the serial one. The comparison is as follows:
the serial one:
>ifort -g unsteady.f90
> time ./a.out
...
7233900.95342814 cells per second
real 1m14.997s
user 1m10.864s
sys 0m4.028s
the paralle one:
>ifort -g -openmp unsteady.f90 -o a-mp
> time ./a-mp
...
1155580.41337423 cells per second
real 3m43.193s
user 7m10.685s
sys 0m9.054s
I analyzed the parallel program with Amplified Vtune and the results shows a significant time was spent and waiting and synchronization. I have no idea why threads took so many time to start and clone.

My OS is opensuse 12.3 and the version of ifort is 14.0.0 and VTune(TM) Amplifier XE 2013 Update 13. Need your help please. The source code and the Amplifier project are attached.
Thanks,
Sung, Hui
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you have HyperThreading enabled, or use a dual CPU platform, you must set appropriate OMP_NUM_THREADS and KMP_AFFINITY so as to pin 1 thread per core, if you hope to see any gain from OpenMP.
When you parallelize outer loops with a count of 8, you will be using only up to 4, or maybe 8 threads with any effectiveness. If collapse() worked, it might enable use of other numbers of threads.
You should filter down to the most time-consuming thread in VTune so as to see where the elapsed time is spent. You would expect the total time of all threads to increase with parallelization.
Current compilers implement workshare as an omp single, so you can't expect stream to benefit the way you did it. Slowdown might come from optimizations which would otherwise occur, e.g. fusion, being prevented in an OpenMP region. Check opt-report. Even if compilers come along which implement parallel workshare in "simple" cases, this is not "simple." As only 1 thread is running, VTune will show a great deal of OpenMP activity on idle threads. You would need to write out the outer loops as F77 DO loops, fusing as many as possible (including tricks such as fusing loops with count differering by 1 or 2), applying OpenMP on individual DO loops, and testing with varying numbers of threads. At least keep any fusion which the compiler reports when not using OpenMP.
Did -parallel help any part of it, once you take care of NUM_THREADS and affinity?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In couputeFeq consider swapping loop order of i and x. This will benefit you two ways: a) the outer loop can be split up amongst more threads (assuming more than 9 available), b) the inner most loop y (500) will likely experience L1 hits on 8 of the 9 references to rho(y,x) and uSqr(y,x). and 499*9 of the references to u(y,x,0) and u(y,x,1), and v(i,0), v(i,1)
500 * 8 * 4 = 8KB for u(y,x,0) and u(y,x,1), rho(y,x) and uSqr(y,x)
then less than 1KB for the remainder v(i,:)
* 2 threads/core = 18KB
Also consider using streaming stores on fEq if possible. Let us know what happens.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks TimP. Sorry i forgot to say about my hardware. The computer is Ideapad Z460 with Inter Core 350M, 2 cores with 2 threads per core. I did not know about the KMP_AFFINITY so i read some realated articles. Now i set these two environment variables as
export OMP_NUM_THREADS=2
export KMP_AFFINITY=granularity=fine,compact,1,0
I replaced the workshare part codes of 'stream' subroutine with a do-loop but the efficiency is worse than the original workshare. Is this do-loop not suitable to parallel?
[fortran]
!$omp do private(y_n,x_e,y_s,x_w)
do y = 1,yDim
do x = 1,xDim
y_n = mod(y,yDim)+1
x_e = mod(x,xDim)+1
y_s = yDim-mod(yDim+1-y,yDim)
x_w = xDim-mod(xDim+1-x,xDim)
fnew( y , x , 0 ) = f(y,x,0)
fnew( y , x_e , 1 ) = f(y,x,1)
fnew( y_n , x , 2 ) = f(y,x,2)
fnew( y , x_w , 3 ) = f(y,x,3) ! n
fnew( y_s , x , 4 ) = f(y,x,4) ! . . .
fnew( y_n , x_e , 5 ) = f(y,x,5) ! w . . . e
fnew( y_n , x_w , 6 ) = f(y,x,6) ! . . .
fnew( y_s , x_w , 7 ) = f(y,x,7) ! s
fnew( y_s , x_e , 8 ) = f(y,x,8)
end do
end do
!$omp end do
[/fortran]
The -parallel option help little. The main problem is still that, the thread concurrency seems to be 2 from Vtune's analysis, but the spin time is very long, about 150s. Can you help to analysis this problem?

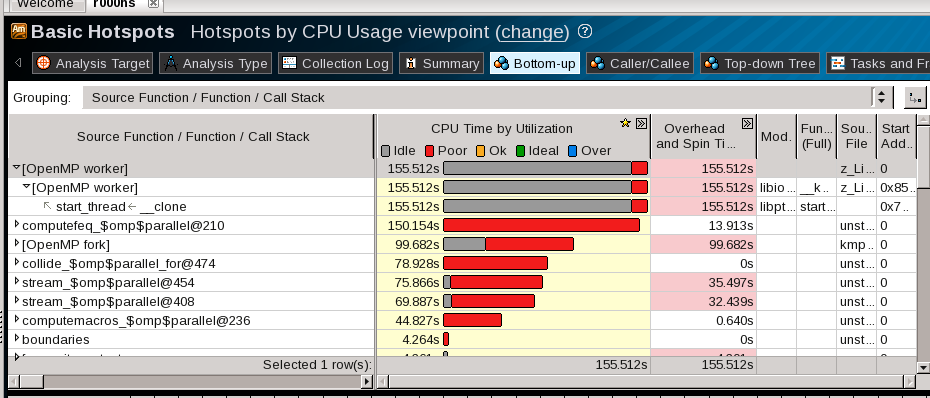{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It looks like swapping the loops should help. Please do create the opt-report and try to get vectorized inner loop.
With vectorization, you may get some advantage from the architecture options -xHost or -msse4.1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You might consider not using parallel workshare in subroutine stream, whereby you effectively have a barrier after each statement (24 barriers). Instead use parallel sections, with the number of sections equal to the number of threads (2/4), each section also containing close to the same number of variables copied. Programming in this manner results in one barrier (thus reducing spinwait time, if work is evenly divided). The current layout with minor reposition, permits equal partitioning.
[fortran]
!$omp parallel
if(omp_get_num_threads() == 2) then
!$omp sections
! -------------------------------------
! right direction
fnew(:,2:xDim,1) = f(:,1:xDim-1,1)
fnew(:,1,1) = f(:,xDim,1)
! -------------------------------------
! up direction
fnew(yDim,:,4) = f(1,:,4)
fnew(1:yDim-1,:,4) = f(2:yDim,:,4)
! -------------------------------------
! up-right direction
fnew(1:yDim-1,2:xDim,8) = f(2:yDim,1:xDim-1,8)
fnew(yDim,2:xDim,8) = f(1,1:xDim-1,8)
fnew(yDim,1,8) = f(1,xDim,8)
fnew(1:yDim-1,1,8) = f(2:yDim,xDim,8)
! -------------------------------------
! up-left direction
fnew(1:yDim-1,1:xDim-1,7) = f(2:yDim,2:xDim,7)
fnew(yDim,1:xDim-1,7) = f(1,2:xDim,7)
fnew(yDim,xDim,7) = f(1,1,7)
fnew(1:yDim-1,xDim,7) = f(2:yDim,1,7)
!$omp section
! -------------------------------------
! left direction
fnew(:,xDim,3) = f(:,1,3)
fnew(:,1:xDim-1,3) = f(:,2:xDim,3)
! -------------------------------------
! down direction
fnew(1,:,2) = f(yDim,:,2)
fnew(2:yDim,:,2) = f(1:yDim-1,:,2)
! -------------------------------------
! down-left direction
fnew(2:yDim,1:xDim-1,6) = f(1:yDim-1,2:xDim,6)
fnew(1,1:xDim-1,6) = f(yDim,2:xDim,6)
fnew(1,xDim,6) = f(yDim,1,6)
fnew(2:yDim,xDim,6) = f(1:yDim-1,1,6)
! -------------------------------------
! down-right direction
fnew(2:yDim,2:xDim,5) = f(1:yDim-1,1:xDim-1,5)
fnew(1,2:xDim,5) = f(yDim,1:xDim-1,5)
fnew(1,1,5) = f(yDim,xDim,5)
fnew(2:yDim,1,5) = f(1:yDim-1,xDim,5)
!$omp end sections
else
!$omp sections
! -------------------------------------
! right direction
fnew(:,2:xDim,1) = f(:,1:xDim-1,1)
fnew(:,1,1) = f(:,xDim,1)
! -------------------------------------
! up-right direction
fnew(1:yDim-1,2:xDim,8) = f(2:yDim,1:xDim-1,8)
fnew(yDim,2:xDim,8) = f(1,1:xDim-1,8)
fnew(yDim,1,8) = f(1,xDim,8)
fnew(1:yDim-1,1,8) = f(2:yDim,xDim,8)
!$omp section
! -------------------------------------
! up direction
fnew(yDim,:,4) = f(1,:,4)
fnew(1:yDim-1,:,4) = f(2:yDim,:,4)
! -------------------------------------
! up-left direction
fnew(1:yDim-1,1:xDim-1,7) = f(2:yDim,2:xDim,7)
fnew(yDim,1:xDim-1,7) = f(1,2:xDim,7)
fnew(yDim,xDim,7) = f(1,1,7)
fnew(1:yDim-1,xDim,7) = f(2:yDim,1,7)
!$omp section
! -------------------------------------
! left direction
fnew(:,xDim,3) = f(:,1,3)
fnew(:,1:xDim-1,3) = f(:,2:xDim,3)
! -------------------------------------
! down-left direction
fnew(2:yDim,1:xDim-1,6) = f(1:yDim-1,2:xDim,6)
fnew(1,1:xDim-1,6) = f(yDim,2:xDim,6)
fnew(1,xDim,6) = f(yDim,1,6)
fnew(2:yDim,xDim,6) = f(1:yDim-1,1,6)
!$omp section
! -------------------------------------
! down direction
fnew(1,:,2) = f(yDim,:,2)
fnew(2:yDim,:,2) = f(1:yDim-1,:,2)
! -------------------------------------
! down-right direction
fnew(2:yDim,2:xDim,5) = f(1:yDim-1,1:xDim-1,5)
fnew(1,2:xDim,5) = f(yDim,1:xDim-1,5)
fnew(1,1,5) = f(yDim,xDim,5)
fnew(2:yDim,1,5) = f(1:yDim-1,xDim,5)
!$omp end sections
endif
!$omp end parallel
[/fortran]
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks jimdempseyatthecove,
Sorry for replying late. I tried to, but the forum prompt me about spam messages.
'swapping loop order of i and x' helps, this skill and the above one about barriers are awesome though i'm not totally understand, but i'll try to.
Also, i combine subroutine 'computeFeq' and 'collison' as you suggested. Now the efficiency of parallel codes is acceptable, but just as i said above, the spin time is still high. Please comment on how to analyse and solve this problem. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In stream, you still have the x and y loops nested backwards. That may be the biggest problem. OpenMP prevents the compiler from involving the outer loop in loop nesting optimizations, so you must choose the right one yourself. It would be one of the reasons why workshare can't be implemented effectively in general.
It's difficult to guess whether the i=1,8 loop should be on the outside and be the one on which you parallelize, but if you can use only 2 or 4 threads, that seems a reasonable choice. If you don't wish to be consistent about it, you may need to test each choice individually.
Even experts are confused about the significance of OpenMP time. As I mentioned, you should try to filter down to the slowest threads in VTune in hope of determining which are the important obstacles.
As long as you leave HyperThreading enabled, you may expect a great deal of OpenMP time. Consider that you are trying to reduce elapsed time by 10% while providing partial resources for double the number of threads; the additional thread time which can't be used productively and can't be used by sleeps should be expected to go into OpenMP. So it will be nearly impossible to judge whether you have excessive OpenMP events while HT is enabled. Also, on a single CPU without HT, you should get near optimum OpenMP performance without KMP_AFFINITY, in case you have doubts about those settings.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks TimP, if i combine the x and y loops, like the followings
[fortran]
do m = 1,xDim*yDim
x = (m - 1)/yDim+1
y = mod(m-1,yDim)+1
...
end do
[/fortran]
will this combined loop get better performance generally?
I'm not familiar with Vtune, so can you give some hints about how to 'filter down to the slowest threads in VTune'? Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The ideal situation is to have large stride parallelization on the outer loop, stride 1 vectorization on the inner loop. Both forms of parallelization must coexist effectively in order to achieve advertised performance.
In the absence of OpenMP, the compiler should consider a hidden transformation such as you have written, which could account for fairly good single thread performance.
If you force combination of the levels of loops as you have done, you should still at least check with vec-report or opt-report to see if you got vectorization or can achieve it by !$opt parallel do simd (in ifort 14.0). This is a reasonable idea, if it can report both parallelization and vectorization, but you would want to compare it with the correctly nested pair of loops.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks TimP, i compared the efficiencies and decide not to combine the do loops. The reports from opt-report option are very useful for understand the parallelization. Jim and Timp, really thanks for your help. The skills revealed from your replies are greatly helpful for me.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page