- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
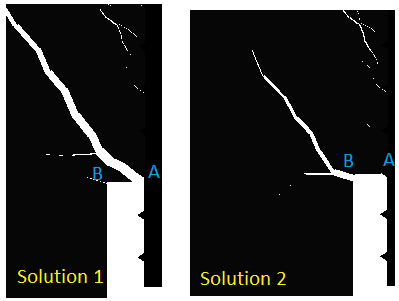
I just noticed each time I run my model, initial steps are exactly same until after a specific step I get slightly different results.
First I was almost sure that I made a mistake in my code but when I visualize the results I see that each case makes sense:
Solution 1: a crack starts from A and propagates
Solution 2: a crack starts from B and propagates

I now suspect dual solution; but I don't understand how it is possible that one code can generate different results each time I run it.
I am not using any randomization and the problem is exactly same.
I would appreciate if you could help me to understand 'what am I facing'?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, the MKL documentation covers the topic 'reproducible results' also, if I remember correctly. Further I found these documents:
In my codes I use the following settings and get normally good reproducible results (openmp/no openmp, Od vs. O3):
/fp:source /Qfp-speculation=safe /Qimf-precision:high
Further, to find issues with missing initialization, although I don't think from comparison debug/release that this is an issue for you, you can choose the compiler options:
/Qinit:snan /Qinit:arrays
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, just a speculation:
- the used numerical model/solver is not robust, nice book which covers this topic along many interesting Fortran topics is Damian Rouson et. al. "Scientific Software Design The Object-Oriented Way"
- you did not proper initialize your data arrays
- you use a not appropriate floating point model (https://software.intel.com/en-us/node/522970 or https://software.intel.com/en-us/articles/consistency-of-floating-point-results-using-the-intel-compiler) Do you get the same results in debug and release mode?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Another possibility: are you using OpenMP or other multithreading/multiprocessing constructs? If so, you can simply not be sure that from one calculation to the next things are handled in exactly the same way. As we do not know anything about your program, it is difficult to be more specific.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Johannes,
Thank you very much, your comments are really useful for me, especially the floating point model.
johannes k. wrote:
- ...Do you get the same results in debug and release mode?
I could verify some difference in debug mode (from step 4 iteration 180):
Run 1
Analysis started.. Total steps: 20 2018/03/16 15:47:44.2
Step 1 out of 20 convergence: 0.16E+03 2018/03/16 15:47:50.0
>iteration 1 convergence:0.1079E+03:0.1079E+03
...
Step 4 out of 20 convergence: 0.47E+03 2018/03/16 15:51:59.8
>iteration 1 convergence:0.2544E+03
...
>iteration 180 convergence:0.1995E+02
>iteration 181 convergence:0.1981E+02
>iteration 182 convergence:0.1968E+02
>iteration 183 convergence:0.1955E+02
...
>iteration 298 convergence:0.1002E+02
>iteration 299 convergence:0.1001E+02
>iteration 300 convergence:0.1001E+02
...
and in another analysis the numbers become slightly different:
Run 2
Step 4 out of 20 convergence: 0.47E+03 2018/03/16 16:00:52.8
>iteration 180 convergence:0.1995E+02
>iteration 181 convergence:0.1982E+02
>iteration 182 convergence:0.1969E+02
>iteration 183 convergence:0.1956E+02
...
>iteration 298 convergence:0.1049E+02
>iteration 299 convergence:0.1045E+02
>iteration 300 convergence:0.1042E+02
...
Also step 4 in which this difference happens takes a very long number of iterations to converge.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Arjen Markus wrote:
Another possibility: are you using OpenMP or other multithreading/multiprocessing constructs? If so, you can simply not be sure that from one calculation to the next things are handled in exactly the same way. As we do not know anything about your program, it is difficult to be more specific.
Yes, I am using multithreading (the code runs on an Intel 10-core CPU machine).
I also link MKL library using Qmkl:parallel
Still trying to find which part in the code will cause such behavior but no luck so far.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, the MKL documentation covers the topic 'reproducible results' also, if I remember correctly. Further I found these documents:
In my codes I use the following settings and get normally good reproducible results (openmp/no openmp, Od vs. O3):
/fp:source /Qfp-speculation=safe /Qimf-precision:high
Further, to find issues with missing initialization, although I don't think from comparison debug/release that this is an issue for you, you can choose the compiler options:
/Qinit:snan /Qinit:arrays
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
johannes k. wrote:
Further, to find issues with missing initialization, although I don't think from comparison debug/release that this is an issue for you, you can choose the compiler options:
/Qinit:snan /Qinit:arrays
This won't apply if I use EXPLICIT NONE, am I correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
S. MPay wrote:
Quote:
Arjen Markus wrote:
Another possibility: are you using OpenMP or other multithreading/multiprocessing constructs? If so, you can simply not be sure that from one calculation to the next things are handled in exactly the same way. As we do not know anything about your program, it is difficult to be more specific.
Yes, I am using multithreading (the code runs on an Intel 10-core CPU machine).
I also link MKL library using Qmkl:parallel
Still trying to find which part in the code will cause such behavior but no luck so far.
The problem is that with multithreaded calculations things may be done in a different order from one run to the next. Suppose you have three threads and a fourth must sum the results:
Run 1:
Thread 4 gets the results in the order thread 1, thread 2, thread 3: answer = (R1+R2) + R3
Run 2:
Thread 4 gets the results in the order thread 3, thread 1, thread 2: answer = (R3+R1) + R2
As floating-point arithmetic cannot guarantee that the two answer are exactly the same, there is an opportunity for a random variation in the results. If your agorithm is senstive to small variations, this might be the cause.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
S. MPay wrote:
Quote:
This won't apply if I use EXPLICIT NONE, am I correct?
You mean IMPLICIT NONE? That has no effect here. The /Qinit options help detect uninitialied values at runtime.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Arjen Markus wrote:
As floating-point arithmetic cannot guarantee that the two answer are exactly the same, there is an opportunity for a random variation in the results. If your agorithm is senstive to small variations, this might be the cause.
Yes, I can admit that the algorithm is likely to be sensitive to small variation in this case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steve Lionel (Ret.) wrote:
You mean IMPLICIT NONE? That has no effect here. The /Qinit options help detect uninitialied values at runtime.
Yes, sorry for the mistake (I was thinking of option explicit probably!)
I see, so /Qinit:snan will set uninitialized variables to NAN value I suppose.
I will give those options a try and see.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My former colleagues cited legitimate cases in crack propagation where 2 solutions are equally valid within the accuracy of floating point arithmetic. Then, as hinted above, parallel computing could produce this situation where either solution might appear, due to insignificant differences in order of computation. Also, as hinted above, uninitialized data could trigger one or the other, even if the difference in initial values isn't significant. There may actually be a physical correspondence even when a correctly modeled experiment is undertaken i.e. very small differences in temperature or orientation might sometimes cause the crack to jump. Of course, you should assure in practice that you don't have uninitialized data, for example because you may not have control over whether differences are significant.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tim P. wrote:
My former colleagues cited legitimate cases in crack propagation where 2 solutions are equally valid within the accuracy of floating point arithmetic. Then, as hinted above, parallel computing could produce this situation where either solution might appear, due to insignificant differences in order of computation. Also, as hinted above, uninitialized data could trigger one or the other, even if the difference in initial values isn't significant. There may actually be a physical correspondence even when a correctly modeled experiment is undertaken i.e. very small differences in temperature or orientation might sometimes cause the crack to jump. Of course, you should assure in practice that you don't have uninitialized data, for example because you may not have control over whether differences are significant.
Dear Tim, Thank you very much, is it possible to have the citation of that research just in case you know.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would try running the code with a single processor.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page