- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Consider the following code and the generated assembly from ifort 14 (with -xCORE-AVX2 and -O2).
Assuming that the B.9 segment is the peel loop, why the compiler still uses unaligned mov instructions for the vectorized loop body?
subroutine aligntest (acc,z,n)
real, dimension(*) :: acc
real, dimension(*) :: z
integer n
integer i
do i = 1 ,n
acc(i) = acc(i) * z(i)
enddo
end subroutine
..B1.9: # Preds ..B1.7 ..B1.9
vmovss (%rdi,%rcx,4), %xmm0 #9.26
vmulss (%rsi,%rcx,4), %xmm0, %xmm1 #9.17
vmovss %xmm1, (%rdi,%rcx,4) #9.17
incq %rcx #8.14
cmpq %r8, %rcx #8.14
jb ..B1.9 # Prob 82% #8.14
# LOE rax rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15
..B1.12: # Preds ..B1.7 ..B1.9 ..B1.12
vmovups (%rdi,%r8,4), %ymm0 #9.26
vmovups 32(%rdi,%r8,4), %ymm2 #9.26
vmulps (%rsi,%r8,4), %ymm0, %ymm1 #9.17
vmulps 32(%rsi,%r8,4), %ymm2, %ymm3 #9.17
vmovups %ymm1, (%rdi,%r8,4) #9.17
vmovups %ymm3, 32(%rdi,%r8,4) #9.17
addq $16, %r8 #8.14
cmpq %rdx, %r8 #8.14
jb ..B1.12 # Prob 82% #8.14
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As all CPUs which support AVX have identical performance for aligned and unaligned instructions when the data are aligned, the unaligned instructions are chosen. This change was made before production release of AVX.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings Tim P,
Thank you for the answer. Since the performance of aligned and unaligned instructions is the same are you possibly aware of
any way to disable the peeling loop.
Assuming this was a reduction loop, I would like to guarantee reproducible results from run to run and at the same time I would like to maintain the vectorization of reductions. I think that disabling the peeling would be enough to guarantee this, maybe at the slight expense of more L1 cache misses in the main vector loop because of bad alignment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do this. Add:
!DEC$ ASSUME_ALIGNED acc:4,z4
after all the declarations. When you do so, there is no remainder loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greeting Steve,
Thanks, adding the assumed aligned statement as it is I still get the peel loop before the main loop.
However the peel loop goes away if use alignement 16 for sse (i.e. !DEC$ ASSUME_ALIGNED acc:16,z16)
and 32 for avx.
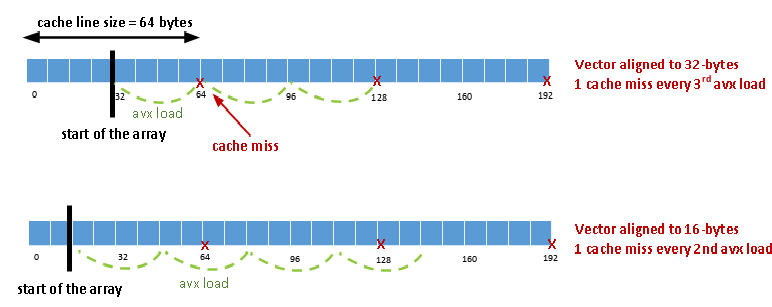
I believe this is expected assuming that the compiler wants to reach optimal alignment with respect the L1 cache line size (see attached diagram).
I was wondering if there is a way to get the peel loop out (because I want to run-to-run reproducibility) but without aligning the accesses.
E.g. something like forcing the compiler to do the main vectorized loop in unaligned mode (at the cost of some performance).
Is there a way to do that?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This sounds like a request for a new directive:
!DIR$ USE_UNALIGNED
This should be relatively easy to implement by the compiler team.
If not a directive, then perhaps a command line option.
I agree that their is a benefit to having better run-to-run reproducibility.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Greetings Jim,
Yes, something like that. I understand that currently the best way to get reproducibility is to ensure the arrays are aligned
but with some access patterns like accessing non-contiguous array chunks I would expect it is not enough to have just the base address of the array aligned.
BTW are there any ideas on how much executing the main vector body in unaligned mode would affect the performance in modern processors?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>BTW are there any ideas on how much executing the main vector body in unaligned mode would affect the performance in modern processors?
Implement your test code in C/C++ using the Intel intrinsic vector functions.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page