- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I really need help with this.
I am trying to accelerate an algorithm using DPC++. what happens is that the normal calculations takes 1.5 times faster than kernel parallel execution. The following code is for both calculations:
the num_items currently equals 16,000, I tried small values like 500 but the same thing, the CPU is way faster the kernel.
// This is the normal CPU calculations
std::vector<double> distance_calculation(std::vector<std::vector<double>>& dataset, std::vector<double>& curr_test) {
auto start = std::chrono::high_resolution_clock::now();
std::vector<double>res;
for (int i = 0; i < dataset.size(); ++i) {
double dis = 0;
for (int j = 0; j < dataset[i].size(); ++j) {
dis += (curr_test[j] - dataset[i][j]) * (curr_test[j] - dataset[i][j]);
}
res.push_back(dis);
}
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed = finish - start;
std::cout << "Elapsed time: " << elapsed.count() << " s\n";
return res;
}
// This is for FPGA emulation.
std::vector<double> distance_calculation_FPGA(queue& q, const std::vector<std::vector<double>>& dataset, const std::vector<double>& curr_test) {
std::vector<double>linear_dataset;
for (int i = 0; i < dataset.size(); ++i) {
for (int j = 0; j < dataset[i].size(); ++j) {
linear_dataset.push_back(dataset[i][j]);
}
}
range<1> num_items{dataset.size()};
std::vector<double>res;
//std::cout << "im in" << std::endl;
res.resize(dataset.size());
buffer dataset_buf(linear_dataset);
buffer curr_test_buf(curr_test);
buffer res_buf(res.data(), num_items);
{
auto start = std::chrono::high_resolution_clock::now();
q.submit([&](handler& h) {
accessor a(dataset_buf, h, read_only);
accessor b(curr_test_buf, h, read_only);
accessor dif(res_buf, h, read_write, no_init);
h.parallel_for(range<1>(num_items), [=](id<1> i) {
// dif[i] = a[i].size() * 1.0;// a[i];
for (int j = 0; j < 5; ++j) {
dif[i] += (b[j] - a[i * 5 + j]) * (b[j] - a[i * 5 + j]);
}
});
});
q.wait();
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed = finish - start;
std::cout << "Elapsed time: " << elapsed.count() << " s\n";
}
/*
for (int i = 0; i < dataset.size(); ++i) {
double dis = 0;
for (int j = 0; j < dataset[i].size(); ++j) {
dis += (curr_test[j] - dataset[i][j]) * (curr_test[j] - dataset[i][j]);
}
res.push_back(dis);
}
*/
return res;
}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for posting in Intel Communities.
Could you please let us know on which device you are running the code?
Could you please provide us with the complete sample reproducer code? And also, could you please let us know the version of dpcpp you are using?
Thanks & Regards,
Varsha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am using visual studio 2022 that runs oneAPI dpc++ compiler, and trying to make emulation on an FPGA, but I don't know how to find the details of the FPGA emulator like what frequency it is running on. The full code is: https://ideone.com/iEHQHa
I have tried to use Jupyter notebook, and it gives faster results for both, yet the program runs on CPU (iterative code) for 8 seconds while on FPGA (kernel code using FPGA emulation) takes 30 seconds.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello amaltha,
When compiling for emulation your program is going to run 100% on the CPU.
It is compiled just like if you were using any SYCL compiler (that don't target FPGAs).
So FPGA specific information such as the device name or the target frequency don't really matter.
The performance that you get from this program is not at all representative of the performance you will get when compiling for FPGAs.
When writing a code that will run on an FPGA, the optimizations that you make are different that the ones you make when targetting a CPU.
Therefore, the optimizations that you wrote for accelerating your program on an FPGA may very well have worse performance when compiled for emulation than your original program.
In this case it is hard to understand what you are comparing to what because you mention that you compared the parallel_for loop to a "CPU" execution, but from my understanding all the programs you launched ran on a CPU.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have one more question, how can I know the details and specifications of the hardware FPGA I am using? Like the frequency.
Thank you a lot yuguen.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, I understand it is all on CPU, I might have misexplained this, I meant that the iterative normal for loop takes less time than that which allows for parallelism (parallel_for). Doesn't parallel_for apply parallelism at the same time to all the rows in the buffers, why its performance is worse? this is mainly my question. The iterative for loop is on the host and the parallel_for is on the kernel (device).
I have tried to split the input into smaller ones by using parallel_for_work_group but it gave the same results. The iterative code no more than 40 seconds while the parallel one takes more than 7 minutes.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello again,
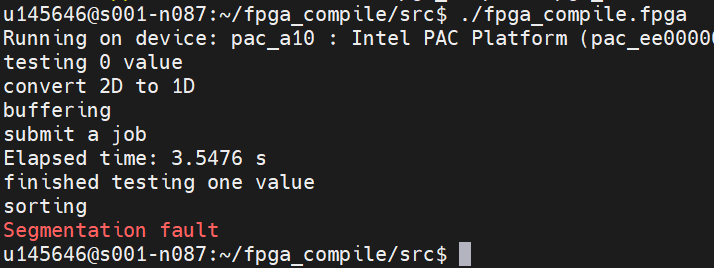
I've tried to run the same full code on FPGA Arria 10 OneAPI devcloud fpga_emulation, and FPGA hardware. The emulation worked normally and successfully and gave satisfying results as shown in the first picture. Running it on FPGA gave me incredible bad results compared to the emulation as the (distance_calculation_FPGA) in emulation resulted in 0.03 seconds and started to decrease, but on FPGA it was 3.5 seconds, and then segmentation fault as in the second picture.
The command I used for the emulation was:
1. dpcpp -fintelfpga -DFPGA_EMULATOR fpga_compile.cpp -o fpga_compile.fpga_emu
2. ./fpga_compile.fpga_emu
and for FPGA hardware:
1. dpcpp -fintelfpga -Xshardware fpga_compile.cpp -o fpga_compile.fpga
2. ./fpga_compile.fpga
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does Double precision in the code make it heavy for the FPGA to calculate distances?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello amaltaha,
"how can I know the details and specifications of the hardware FPGA I am using? Like the frequency. "
If you did not specify an FPGA target, I believe you'll target A10.
If you did not speicify a frequency target, you'll target the default frequency for this FPGA.
When compiling for FPGA it is recommended to build a report, where you can see all this information as well as many other usefull information.
I strongly encourage you to follow the "Explore SYCL* Through Intel® FPGA Code Samples" webpage that will guide you through FPGA development by trying out small code examples.
This will give you a better understanding about how to get performance for your application using this compiler.
"The iterative code no more than 40 seconds while the parallel one takes more than 7 minutes."
There can be multiple reasons causing this.
A first reason is that the compiler is not optimized for CPU execution, but for FPGAs. So having performance gaps between two CPU execution will not reflect the FPGA performance.
A second reason is that I can see on the code snipet you provided above that your parallel loop accumulates in one single location which leads to a race condition on a CPU (again, it will be a completely different story on FPGAs).
"Does Double precision in the code make it heavy for the FPGA to calculate distances?"
Yes, double precision operations are more expensive in terms of resources and have longer latencies than their single precision counterparts.
"in emulation resulted in 0.03 seconds and started to decrease, but on FPGA it was 3.5 seconds"
When using a FPGA, you are offloading a computation.
This offloading comes with an overhead: copying data from the host DDR to the FPGA DDR and copying the data from the FPGA DDR to the host DDR.
So to make the most use out of the FPGA, you need an application that is compute intensive enough to cover these latencies.
In your case, you emulation program is 0.03 seconds, so:
1/ The overhead of using the FPGA is going to be larger than that
2/ Were you expecting an execution faster than 0.03 seconds?
I'm guessing that the application you are trying to accelerate runs longer than 0.03 seconds, so you can try to accelerate your real application and see from there.
"and then segmentation fault as in the second picture. "
The code executed in the picture seems different than the code provided before (not the same print messages).
So it is hard to help you with a screenshot of a segfault
You should try using a debugger (such as gdb) to find where this segfault is coming from so you'll be able to fix it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1- I know that my target is A10, I am asking about the commands that help me see the information related to a specific device or general devices, and the commands that helps me specify the frequency and so on, but I couldn't find them?
2- The code finally worked with this dpcpp commands for emulation and hardware run:
dpcpp -fintelfpga -DFPGA_EMULATOR knn_trial2.cpp -o knn.fpga_emu
and
dpcpp -fintelfpga -Xshardware fpga_compile.cpp -o fpga_compile.fpga
The results give now an average of 0.0005 s, which is fine, it is still slower than the iterative code, this might be because of overhead you mentioned? yet it is way faster than python code that runs in 0.012 s.
The segmentation fault is caused by sorting, it works fine with emulation but the segmentation fault is only after fpga run, Isn't host and kernel codes separated even with fpga run?
3- I have a question regarding parallel_for, single_task, and work groups:
Doesn't parallel_for mean that all the elements (from 0 to num_size) do the same job at the same time? i.e. runs in parallel. I have searched for the difference between parallel_for, single_task, and work groups, and didn't find satisfying explanation for each of them. does parallel_for cause all elements to run in one operation in almost one clock cycle?
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1 - I'm not sure what other information than frequency you are looking for. To specify a clock target for your compile, you can add -Xsclock=<clock target> to your compile command.
You can find all this documentation in the "FPGA Optimization Guide for Intel® oneAPI Toolkits : Developer Guide".
The clock setting option is described in 4.1.1.
2 - I can't tell from your description what is limiting your implementation. However, if you are comparing the iterative vs parallel versions, both on FPGA, then you should in theory get better throughput with the parallel version. I don't know how long your computation lasts, but it should run more than a few seconds to get the benefits of an offload to an FPGA.
I don't know what you mean by "The segmentation fault is caused by sorting".
I'm not sure I understand what you mean by the "host and kernel codes separated even with fpga run" - your kernel code is in the q.submit section, the host code is everything around it. Your host code will issue a call to the FPGA, you'll need to wait for the FPGA to return the results and continue your host computation.
3 - Yes, parallel_for means that all the iterations are executed at the same time, however in the general case they won't execute in one cycle.
I encourage you again to have a look at the "Explore SYCL* Through Intel® FPGA Code Samples" webpage that shows a lot of examples to familiarize yourself with these concepts, as well as teach you what are the good coding practices when developing for FPGAs.
There even is a tutorial for loop unrolling on FPGA, which demonstrates the recommended method: use a for loop with a "pragma unroll" compiler directive (so no parallel_for).
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @amaltaha,
Good day, just checking in to see if there is any further doubts in regards to this matter.
Hope we have clarify your doubts.
Best Wishes
BB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @BoonBengT_Altera
I still have doubts regarding the hardware run of the FPGA. I don't understand why a small parallel operation may take milliseconds while the FPGA runs on more than 500 MHz. Even after I specify the clock flga rate:
–Xsclock=500MHznothing changes, it still runs with milliseconds where host code runs way faster. Isn't FPGA for acceleration? And the FPGA code above is very basic. And also, is there a way to know how many clock cycles the kernel code took, is it equivalent to the latency in the report? The latency in the report is 343, but without units, what does 343 mean, is it the number of clock cycles for example?
2- The segmentation fault problem was solved, nothing wrong with the hardware run except the amount of time it takes compared to a normal c++ code.
3- In my experiment, single_task with a loop inside took almost the same time as parallel_for without a loop inside. which means an iterative code takes as much as the parallel one in the hardware. Is this normal?
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey amaltaha,
1- Yes, FPGAs are used for acceleration. If you are not getting an acceleration it can be that your application is not suitable for FPGA acceleration (e.g. a very quick FPGA computation compared to the overhead of offloading your computation to the FPGA), or that your code needs to be reworked to better suit the programming model for FPGAs.
Yes, the latency is expressed as clock cycles. This is explained in section 2.1.1.1 of the "FPGA Optimization Guide for Intel® oneAPI Toolkits : Developer Guide".
Setting the command line parameter "-Xsclock=500MHz" does not guarantee you the hardware is going to run at that speed. This is a clock target, not an achieved target. To see the achieved clock target, you should look in the generated report. The section 2.0 of the above quoted guide covers the analysis of the generated report. Section 4.1.1 explains the "-Xsclock" parameter.
3 - As I mentioned earlier, I'd suggest you retry your experiment using the "pragma unroll" compiler directive rather that parallel_for. This is demonstrated in the "Explore SYCL* Through Intel® FPGA Code Samples" webpage with hands-on code examples, and is also described in the optimization guide in section 4.6.8
Yohann
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your support Yohann!
Finally, one last thing, it is not possible to view the report on Intel Devcloud as it is not allowed to install a browser like firefox. And viewing it through Jupyter Notebook on the cloud gives an empty HTML file. How to view the report?
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @amaltaha,
Yes you would be able to view the report by zipping it in the devcloud an downloading it via Jupyter notebook since you are familiar with that.
Reason why the HTML are empty when opening in devcloud is because other dependencies files are not opening.
Hence zipping and download it would fixed that.
Hope that clarify.
Note: zip at the entire report folder, just zipping the report.html wont work.
Best Wishes
BB
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you so much @BoonBengT_Altera ! Zipping files using python notebooks worked.
I don't have additional inquiries.
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @amaltaha,
Great! Good to know that you are able to get it worked, with no further clarification on this thread, it will be transitioned to community support for further help on doubts in this thread.
Thank you for the questions and as always pleasure having you here.
Best Wishes
BB
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page