- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Guys:)
It is very nice to have this forum. I'm a fresh on the ISA Extension and expect to have your insight:)
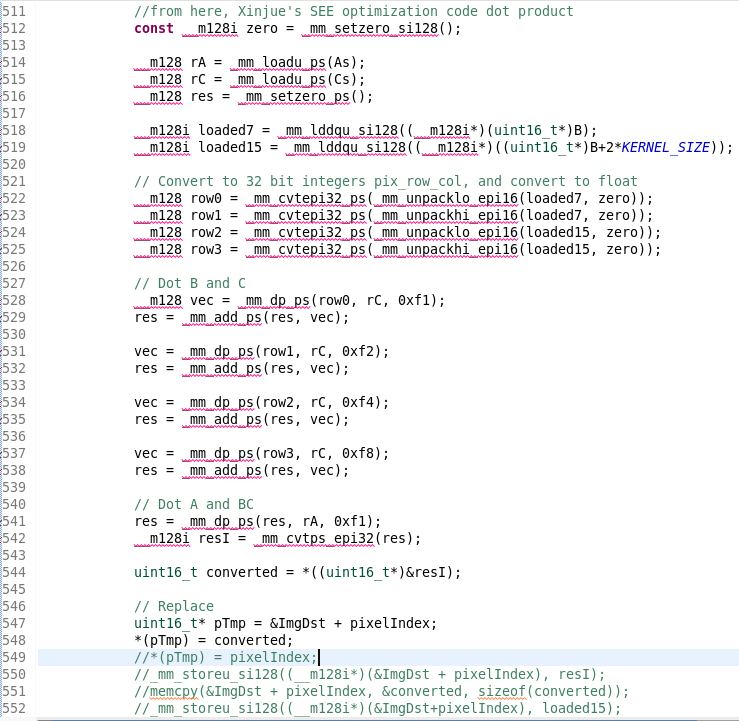
My code snippet, which conducts a convolution computing, is attached as a figure. and here is my confusing issue:
Time was consumed hugely when I tried to assign the computed result to image buffer. Computing time of extension sets(line 512~544) only takes about 7~8ms, but the assign work(line 548) takes about 25~26ms.
The most confusing thing to me is that there is little time-cost while assign the image buffer with other value like loop control index(line 549) or other register(line 552). As long as I try to assign the buffer with computed result(line 544), time-cost will raise hugely. I tried several ways(line 547~552) on assign work, all of these ways cost huge time as well.

My env. info:
compiler: icpc version 12.1.0 (gcc version 4.4.5 compatibility)
OS: Linux version 2.6.32-220.4.1.el6.x86_64
if there is any unclear about the issue description, please kindly let me know. Again, thanks a lot in advance!
- Tags:
- Intel® Advanced Vector Extensions (Intel® AVX)
- Intel® Streaming SIMD Extensions
- Parallel Computing
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you have VTune profiler installed?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Xinjue Z.,
You could use either
*pTmp = _mm_extract_epi16(resI, 0);
or even better
_mm_stream_si32((int *)pTmp, _mm_extract_epi16(resI, 0));
Don't forget that _mm_stream_si32() stores 4 bytes, and call _mm_mfence() at the end.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would try to check disassembly of LOC #544 and LOC #548 and post it here. Do you have any kind of Store-Forwarding Stalls? Does your code operates on the same buffer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
iliyapolak wrote:
Do you have VTune profiler installed?
Hello iliyapolak,
No. I didn't buy the tool, I'll check if there is trial version. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Vladimir Sedach wrote:
Hello Xinjue Z.,
You could use either
*pTmp = _mm_extract_epi16(resI, 0);or even better
_mm_stream_si32((int *)pTmp, _mm_extract_epi16(resI, 0));Don't forget that _mm_stream_si32() stores 4 bytes, and call _mm_mfence() at the end.
Hello Vladimir Sedach
Thank you very much for such info. I think I missed some info and led you to wrong direction, but I still learned couple of new sets:)
My compiler is enabled with O3 level optimization. The ways of assigning(line 549 and 552) didn't use computing results, then it seems the computing sets(line 512~544) were optimized. Is this possible?
Such guess is based on my another try by commenting computing sets from line 531~538. And the time cost is about 19ms.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
iliyapolak wrote:
I would try to check disassembly of LOC #544 and LOC #548 and post it here. Do you have any kind of Store-Forwarding Stalls? Does your code operates on the same buffer?
Hello iliyapolak again:)
Yes, I agree. Checking the disassembly will have some leads. I'll do so and come to you. For the Store-Forwarding Stalls, the variable I used for assigning is a reference of image buffer. Will the reference cause write & read issue? Anyway I'm on my way to check the disassembly.
Again thanks a lot!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Xinjue Z.,
> My compiler is enabled with O3 level optimization. The ways of assigning(line 549 and 552) didn't use computing results,
> then it seems the computing sets(line 512~544) were optimized. Is this possible?
Not just possible - it is true. Compile omits statements with unused results.
To speed it up a bit more you might use _mm_stream_si128() - combine the results of 8 16-bit values in a __m128i reg and "stream" it to the memory.
The huge time could be either due to the cache issues or just time miscalculation )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Xinjue Z. wrote:
Quote:
iliyapolak wrote:
Do you have VTune profiler installed?
Hello iliyapolak,
No. I didn't buy the tool, I'll check if there is trial version. Thanks!
You can download and use trial version.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>>the variable I used for assigning is a reference of image buffer>>>
Maybe in your code there are some pointers or references which are dereferencing/referencing that image buffer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Once you figure out the memory issue, you might consider tweaking the code a little:
// remove // __m128 res = _mm_setzero_ps(); ... // change // Dot B and C row0 = _mm_dp_ps(row0, rC, 0xf1); row1 = _mm_dp_ps(row1, rC, 0xf2); row2 = _mm_dp_ps(row2, rC, 0xf4); __m128 res = _mm_add_ps(row0, row1); row3 = _mm_dp_ps(row3, rC, 0xf8); res = _mm_add_ps(res, row2); res = _mm_add_ps(res, row3); // Dot A and BC ...
The above saves two instructions and attempts to overlap the adds with the multiply. You might get a few clock cycles back.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page