- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
I experimented a very very big performance difference on a server used for HPC based on 2 x Intel® Xeon® Processor E5-2660v3. 10Cores. 20Threads, equipped with 512GByte RAM (DDR4-2133MHz). In particular, the two attached files contain the output from Intel LINPACK benchmark when used on a Windows Server 2012 and a CentOS linux OS. It is the first time I found such a difference (about 200x), but it is the first time we try Windows Server 2012 on a machine dedicated to HPC (we used Windows Server 2008 in the past and on other machines). Except disabling any power save option, anyone knows possible reasons for this behaviour?
- Tags:
- Parallel Computing
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A few notes on the Linux case:
- The Linux result is about right for that small problem size.
- Larger problem sizes and more iterations should provide better and more stable performance.
- Run times of 10 seconds or less give greater variability in the results because (in the default configuration) the chip can exceed its nominal 105 Watt power limit for up to 10 seconds. After 10 seconds it is forced to reduce frequency to stay within the running average power budget.
- I get about 91% of peak (based on the actual frequency, which is close to the base AVX frequency of 2.2 GHz on the Xeon E5-2660 v3) for problem sizes in the N=60,000 range. (UPDATE 2015-07-20: The base AVX frequency on this chip is 2.2 GHz, not 2.3 GHz as I originally posted.)
- On the Xeon E5 v3 platforms even LINPACK requires enough memory bandwidth that it can be helpful to use the Linux "numactl" command to control memory affinity.
- The default "first touch" memory placement behavior will put all the data in socket 0 (assuming it fits), forcing sockets 0&1 to share socket 0's memory bandwidth and forcing all of socket 1's accesses to go over QPI.
- When using cores in both sockets, I get the best results with "numactl --interleave=0,1 ./xhpl"
The Windows result is obvious severely messed up. It is possible that you might get a result this bad if all 20 threads are bound to a single core, but the performance is somewhat worse than I would expect even for that case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Assuming you are running with Intel openmp dll, one of the kmp_affinity options to bind to cores should approach optimum performance. Otherwise, you may need hyperthreads disabled.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John, Tim, thank you for your reply.
Hyperthreading is disabled on the server. Continuing with the use of the Intel LINPACK benchmark, is there a way to highlights possible system's or windows OS setting problems? Can we use VTUNE?
Thanks,
Alessandro
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>>Can we use VTUNE?>>>
How about running VTune on both machines (I assume that the same hardware is being used) in order to collect relevant data and compare the results? On the Windows Server machine I would advice to perform system-wide performance measurement with either VTune or Xperf(WPR). Start your investigation from possible runaway system threads or misbehaving ISR/DPC routines as highest consumers of CPU time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is possible for affinity to take longer to be effective on a Windows server than on linux.
Microsoft recommended a much larger than default value for KMP_BLOCKTIME, if your application can tolerate it.
If you were to use VTune, you might look for a significant rate of remote memory access (indicating that affinity isn't working).
As John said, you would want to see whether the threads are distributed across all cores. Did you check with KMP_AFFINITY verbose option to see that OpenMP is being instructed correctly?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are you running your timed section of code more than once?
The first pass typically encounters page faults for "first touch" of memory in the virtual address space. If "first touch" is an issue for typical run of the application (not just the first pass), then look in to how to configure the system (O/S) to use the Large or Huge virtual memory page size (larger page size == fewer "first touch" page faults). Also, do not have the main thread initialize/populate the initial data after allocation. Use the same parallel loop configuration to perform the "first touch" for the sections of the array(s) that those threads will be working on.
If the second and later passes exhibit the same slowdown, then run a performance monitor to see if the application is still experiencing a large number of page faults.
If it is slow without page faults, then run VTune. 200x slower is too high except for the unusual case where one system has high L1 cache hit, where the other system has all cache misses (and RAM on other node).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The test with the Intel LINPACK benchmark was made on the same machine, with Windows Server 2012 installed and a CentOS linux OS booted from a live usb pendrive. We have removed Windows Server 2012 and installed Windows Server 2008 and now Linux and Windows performances are similar.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergey,
Nice work.
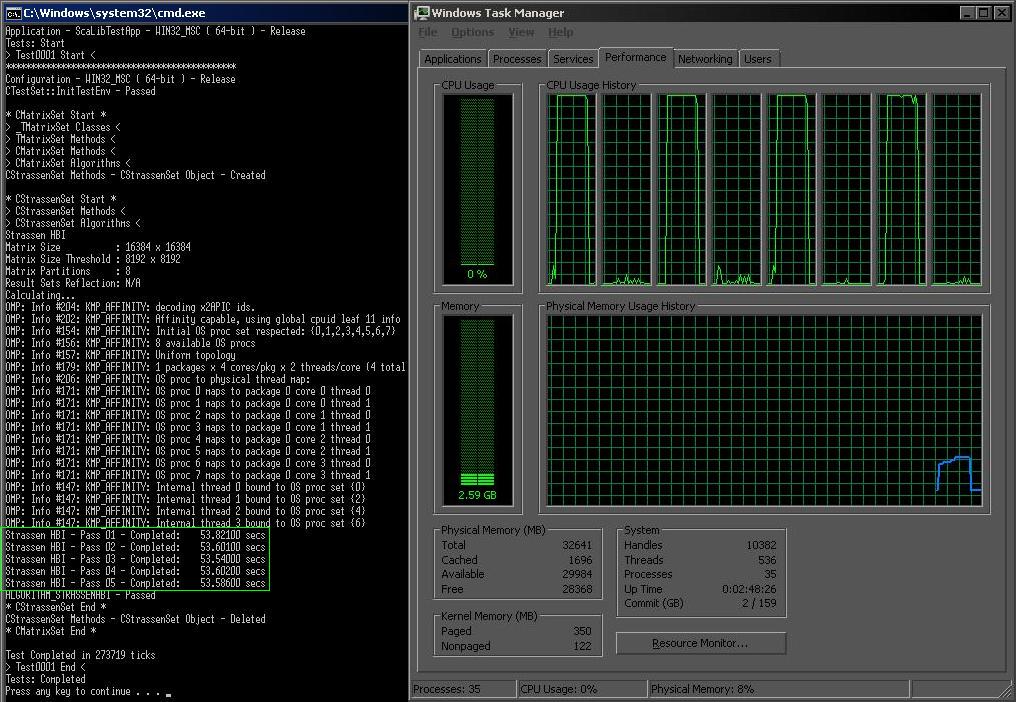
You forgot to mention in #9 that for your setup the intention of setting thread affinity was to configure one thread per core, and not have them migrate about. This is quite clear from your screenshots. I think it would also be enlightening to round out your presentation with two runs (pinned/unpinned) using all threads.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you don't set affinity, on Windows with hyperthreading, you need more threads than cores, so as to get at least 1 thread on each core (but it's typically better to avoid 2 threads per core). This sometimes works with the libgomp. libgomp on WIndows tells you when you set OMP_PLACES that it is not implemented.
Beginning with win7 SP1, the OS improved thread scheduling under HT, but we still see problems such as Sergei showed.
Scheduling on Intel(r) Xeon Phi(tm) presumably is more under Intel's control, but it doesn't spread threads evenly across cores by default. The Intel OpenMP facility KMP_PLACE_THREADS was set up originally for MIC to help with this. It sets the default NUM_THREADS in accordance with the number of threads allocated in PLACE_THREADS. MIC also has the peculiarity that core 0 (thread numer 0 and the 3 highest threads) supports linux threads so is not fully available to the application.
There appear to be BIOS issues as well. The original BIOS on my i5-4200U would cut CPU clock rate by 30% if it ever saw all hyperthreads busy, and would not recover until all cores went idle. This has improved with automatic upgrades.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page