- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
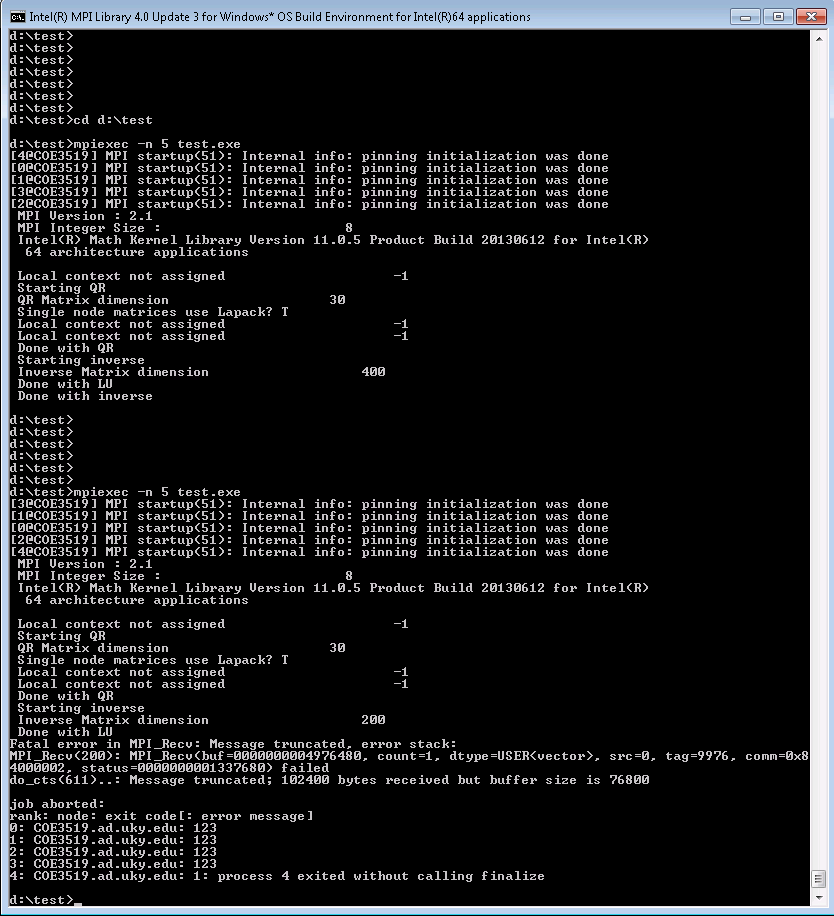
Attached is a test case for some Scalapack calls that are exibiting strange behavior that seems like a bug. I also attached screen shots of the output and of the compile output. I'm using Windows 7 (64-bit) , MKL 11.0.05, Intel MPI 3.0, and the 8-byte integer MKL interface and 8-byte integer MPI interface.
Basically, when I perform a QR factorization on individual mpi nodes followed by a matrix inverse on all nodes, I see a crash depending on the matrix size used in the inverse. More particularly, the matrices in the QR factorization are assigned to individual nodes or groups of nodes.
Whether the crash occurs depends on if the matrices assigned to individual nodes are QR factorized with the lapack QR factor (crash occurs) or the scalapack QR factor (crash does not occur). Any matrix assigned to more than one node will always use the scalapack QR factor. In particular, it is the PZUNQGR/ZUNQGR call that results in the crash in the inverse and not the (P)ZGEQRF call. The final inverse is performed on a single matrix distriubted across all nodes in the grid and the crash may or may not occur basd on the size of the matrix to be inverted.
Does anyone know if I am doing something wrong or if this is a Scalapack bug?
Thanks,
John
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,John,
I have found a mistake in your test.
Matrix qq is allocated with size 30x0 ( in a case Matrix 4 is on two nodes ) in the eye subroutine.
After deleting codes for “! create diagonal matrices” with allocating matrix qq (30x0), test passes for “! invert a matrix” (see attached test).
Remark. It is not so good idea to use MB=NB=32 for matrix qq(30,30).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tamara Kashevarova (Intel) wrote:
I have found a mistake in your test.
Matrix qq is allocated with size 30x0 ( in a case Matrix 4 is on two nodes ) in the eye subroutine.
After deleting codes for “! create diagonal matrices” with allocating matrix qq (30x0), test passes for “! invert a matrix” (see attached test).
Tamara,
First of all, thanks for taking the time to look at this problem
Maybe I am misunderstanding your point, but I do not see a mistake in the test. You are correct that matrix qq is allocated with size (30x0). This, I think, is one of the points of the test. Scalapack should be able to handle properly any distributed matrix even if one of the nodes in the context has an empty portion of the matix. Of course, this would not the most efficient distribution of the matrix across the nodes, but it should work.
In your, test-passed.F90, you have completely removed the the QR factorization 'pzgeqrf' and the Q computation 'pzungqr'. In this case, the matrix inverse does work as you point out. However, the Scalapck bug, in our view, is in the interplay of the QR factorization/Q computation followed by the inverse. Actually, it is really only set off by the call to pzungqr, i.e., just calling pzgeqrf alone followed by the inverse does not produce a crash.
Please let us know if we are misunderstanding the point you are trying to make.
Tamara Kashevarova (Intel) wrote:
Remark. It is not so good idea to use MB=NB=32 for matrix qq(30,30).
Yes, it is not the most efficient, but sometimes it is convenient. In our software, we have multi-level distributed problem. Operations at finer levels are distributed across subsets of nodes and operations at coarser levels are distributed across a greater number of nodes. At any given level and context, there is a complicated set of operations being performed with quite a number of matrices. For example, at one level, we may have a context with 10 nodes. Within these nodes, there might be very large matrices and some matrices that are not so large. However, all of the matrices interact using scalapack and pblas operations, so they need to be in the same context. Hence, the large matrices are efficiently distributed across the context with a large MB,NB block size, and, although the smaller matrices would benefit from a smaller block size, we find it easiest code-wise to fix the block size for all matrices in the context. The efficiency hit seems very minor anyway since the matrices are small to begin with.
Anyway, we feel that scalapack should gracefully handle any matrix even if some of the nodes have an empty portion of the distributed matrix. The attached code does not seem to us to solve the bug since it is masked by the removal of the QR calls. In our experience so far, every other (intel) scalapack function that we have used seems to gracefully handle nodes which have empty portions of the distributed sub-matrix except for pzungqr. We feel there is still a bug in the pzunqgr code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tamara Kashevarova (Intel) wrote:
Matrix qq is allocated with size 30x0 ( in a case Matrix 4 is on two nodes ) in the eye subroutine.
After deleting codes for “! create diagonal matrices” with allocating matrix qq (30x0), test passes for “! invert a matrix” (see attached test).
I just want to clarify my previous post. The bug occurs when you mix the pzunqgr for matrices on multiple nodes with the plain zungqr for the matrices on only single nodes. If you use the pzungqr for all matrices on across all nodes, the bug does not occur. So, when pzungqr is always used, it gracefully handles matrices distributed across multiple nodes where some nodes have empty sub-matrices. However, when pzungqr is used alongside zungqr, the bug shows up.
It's almost like pzungqr is communicating some information that is escaping the blacs context but is received by the other blacs contexts when pzungqr is used on the other nodes. So, when the matrix inverse is called, no crash occurs. However, when zungqr is used for the single-node matrices, this information is not received and then it corrups the mpi calls of the inverse. I'm sure this is not really what is happening, but it does sort of seem like the matrix inverse is being corrupted by some data being received that should not be (and this extra data seems to be sparked some how by the pzungqr call).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tamara Kashevarova (Intel) wrote:
Hello,John,
I have found a mistake in your test.
Matrix qq is allocated with size 30x0 ( in a case Matrix 4 is on two nodes ) in the eye subroutine.
After deleting codes for “! create diagonal matrices” with allocating matrix qq (30x0), test passes for “! invert a matrix” (see attached test).
It seems my original reply to your message did not get posted properly, so my secondary reply may seem a little out of context.
I guess I do not understand the point you are making. From looking at the test case you provided, the *zgeqrf and *zunqgr calls have been completely removed. The crash in the inverse is actually a result of the *zunqgr call, so the test-passed.F90 does not seem like a valid solution. Our feeling is that there is still a bug in scalapack and that the QR calls should handle the original test case. We are aware that one of the nodes has a 30x0 local matrix. We feel that this should not be a problem for scalapack and it should handle it without crashing. If we are misunderstanding your point and there is a mistake in the test case other than the two-node context which has the empty sub-matrix on one node, could you please clarify.
Tamara Kashevarova (Intel) wrote:
Remark. It is not so good idea to use MB=NB=32 for matrix qq(30,30).
We agree that it is not optimum efficiency wise, but in our case, it is desirable from a code perspective. Some of our contexts use a variety of matrix operations on a number of matrices. For example, we might have a context with very large and very small matrices. These matrices might be operated on individually, .e.g., QR factorization and then the results combined with other operations, e.g., multiplies, etc. It is easiest for us to use a single block size optimized more towards the larger matrices (which would fully use the process grid) and take a hit in efficiency for the smaller matrices that might not fully utilize the process grid. Since the matrices are small, the efficiency hit is minor compared to the operations on the large matrices.
Thanks for you help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
I recalled i had replied the issues last time. It seems not here. Sorry, the current verson seems only work with any nonzero local matrix. We have submitted CQ #DPD200390535 for further investigation. I will update you if any news.
Thanks
Ying
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Test reveals problem in MKL. John, thank you for finding it.
Fix is ready and will be available in Intel® Math Kernel Library 11.1 Update 2. Problem is that pzungqr call leads to undesirable change of BLACS topology settings which do not work for your test. This is a global setting, not a part of BLACS context.
So there is workaround:
Enclose pzungqr invocation in call of pb_topget, pb_topset routines
call pb_topget( icontextA, 'Broadcast', 'Rowwise', rowbtop )
call pb_topget( icontextA, 'Broadcast', 'Columnwise', colbtop )
call pzungqr(qr_size, qr_size, qr_size, qq, 1, 1, qq_desc, tau, work, lwork, info)
call pb_topset( icontextA, 'Broadcast', 'Rowwise', rowbtop )
call pb_topset( icontextA, 'Broadcast', 'Columnwise', colbtop )
Declare rowbtop, colbtop as integer.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page