- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
since I can run now the mkl library 2017, I have a couple of follow up questions that hopefully deserve a thread of their own. I am doing some mode matching, and consequently I need matrix inversions on matrices of the order 10x10 up to 50x50 most of the time (the maximum size would be somewhere aroud 200x200 but very rarely, they will almost exclusively be in the 10-50 range). I have optimized my non mkl parts of the code so they are under 10% of all the simulation time, so any speedup on the mkl functions would be greatly beneficial, if possible. Now I have set the mkl_num_threads to max, release mode, ia32, O2 optimization, optimized for speed and so forth to make it as fast as I can/know to make currently. I only have a couple of matrices to invert per frequency point (5 to 6), and the code must execute one frequency point at a time. My questions are as follows:
1) Is there a way to improve the performance of the mkl functions in any way (by setting some flags in the program itself, or in Visual studio, or am I missing some functions that are better in this situation, or something else completely), either in the mkl 2017 or the old mkl 10.0.012 that I have? I am using cblas_zgemm, cblas_zdscal, zgetri, zgetrf, vzSqrt, cblas_zaxpy, but most of the time is spent in matrix inversion, so zgetri, zgetrf take most of the time. Are there better functions than these or can I set some additional flags to make them faster?
2) Since the optimization is for speed and not size, I of course expected the output (exe) to be bigger, but can someone explain and/or help me optimize the output size for the exe in mkl 2017, because it is 3x bigger than with the old mkl 10.0.012? This represents a small problem unfortunatelly, and if possible I would be very happy if it can be mittigated in any way (without optimize for size)
3) Some of the matrices are symmetrical, and I was hopping that the symmetrical versions of zgetri, zgetrf, that is zsytrf and zsytri, I would be able to theoretically get a 2x speedup, but for some reason the speed is the same. Is this expected? Are my matrices too small for any noticeable effect? Am I missing something? In both cases I feed the functions the full matrix to invert, and while I am debugging I can see that only half of the matrix elements are calculated for the symmetrical functions, and I fill the symmetric elements, but there is no speed up.
Any information, even if not good is welcome. Thank you all in advance.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marko,
It is nice topic for discuss here. If possible, could you attach your test code, especially zgetri, zgetrf code, so we can test at same basic line?
Some comments about your questions
1. the matrix size 10x10 to 50x50. (max 200x200). right, the matrix size seem too small to optimize by any ways.
But as you tried, Here is some tips to improve the performance or reduce overhead of MKL way ,
1.1 may you please try -DMKL_DIRECT_CALL_SEQ
https://software.intel.com/en-us/mkl-linux-developer-guide-limitations-of-the-direct-call
1. 2. what kind of CPU are you using? try sequential MKL or set OMP_NUM_THREADS=1,2, 4 etc and find the best performance. (as for small workload, it may not best solution to set max threads.
1.3 other tips, like array alignments etc. https://software.intel.com/en-us/mkl-linux-developer-guide-other-tips-and-techniques-to-improve-performance
2. Regarding the exe size. How do you link mkl in your code? Maybe the later version add more CPU-specific optimized code thus bigger size. You may read the article https://software.intel.com/en-us/articles/intel-math-kernel-library-intel-mkl-linkage-and-distribution-quick-reference-guide and find some suitable link model.
3. the symmetric feature may or may not helps. The problem may be caused by small matrix or less optimize in MKL functions. Let's test if you provide the test code.
Best Regards
Ying
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ying,
Thanks for all the suggestions. It is more out of curiosity, since there is a big difference between the mkl versions I am using. Essentially there is no noticeable difference in speed for me between mkl 10.0.012 and mkl 2017, but I was hoping that with potential new options there could be some new options that I don't know or have overlooked. As for the suggestions I have tried:
1.1 When I add the MKL_DIRECT_CALL_SEQ or MKL_DIRECT_CALL to the preprocessor I get some errors of the form "cannot convert argument k from complex<double> * to const MKL_Complex16 *". I have used some variables of complex double form as arguments for mkl functions but before using this preprocessor directive I did not get these errors, and the produced results were correct.
1.2 My CPU is Intel Core i7-2670 QM @ 2.20 GHz. I have tried testing with different number of threads, but the max number always gave the smallest time, but only by a little bit, maybe there was a 15% difference between 1 thread and 4 threads, and 2 and 4 are almost the same.
1.3 I have not tried this, but will try to see if it helps.
2. It is static linking, but I only used the automatic inclusion of mkl in Visual studio. I will try individual libraries, like in the old mkl version to see if I can reduce the size of the exe.
My example code is bellow. The first function is to check if the matrix is symmetric, checks separately the real and imag part to a given tolerance, and the other function uses the first one to determine the input matrix symmetry and if symmetric uses the symmetric mkl functions.The third function is for matrix multiplication, two matrices in, one out, nothing special. There could be errors in my code, or total misunderstanding of what the functions should do, so if anybody has any complaints, feel free to express them. I did the visual studio profiler and diagnostics on my release version and 77.2% of the time is in libiomp5md.dll (I don't know if this can be optimized), and from the other 22.8%, about 16% is in zgemm, zgetrf and zgetri (for a 40x40 matrix test). This was done for 1000 frequency points, so to have some reasonable time measurement, so 77.2% and the other values are after 1000 calls to my top level function. In the matrix multiply function, there are const complex<double> alpha (1.0,0.0), beta(0.0,0.0).
If I missed anything please ask, and thank you all in advance for the advices.
Matrices are made with : new MKL_Complex16[N*N], so maybe the alignment would do something.
bool m_check_if_matrix_symmetric(MKL_Complex16 * matrix, int N){
bool result = true, test_real_part, test_imag_part;
int i, j;
double num_real_1, num_real_2, eps = 1e-10;
for (i = 0; i < N; i++){
for (j = i+1; j < N; j++){
num_real_1 = matrix[i*N + j].real;
num_real_2 = matrix[j*N + i].real;
test_real_part = fabs(num_real_1 - num_real_2) <= ((fabs(num_real_1) < fabs(num_real_2) ? fabs(num_real_2) : fabs(num_real_1)) * eps);
num_real_1 = matrix[i*N + j].imag;
num_real_2 = matrix[j*N + i].imag;
test_imag_part = fabs(num_real_1 - num_real_2) <= ((fabs(num_real_1) < fabs(num_real_2) ? fabs(num_real_2) : fabs(num_real_1)) * eps);
if (!test_real_part || !test_imag_part){
result = false;
break;
}
}
}
return result;
}
void m_matrix_inversion(MKL_Complex16 *& matrix, int N){
int i, j;
bool test_if_symm;
int *NLi = new int(N), *MLi = new int(N), *ldaLi = new int(N), *ipivLi = new int, *infoLi = new int(0);
int lworkLi = -1;
MKL_Complex16 *dummywork = new MKL_Complex16[1];
test_if_symm = m_check_if_matrix_symmetric(matrix, N);
if (test_if_symm){
zsytrf("U", NLi, matrix, ldaLi, ipivLi, dummywork, &lworkLi, infoLi);
}else{
zgetri(NLi, matrix, ldaLi, ipivLi, dummywork, &lworkLi, infoLi);
}
lworkLi = (int)(dummywork[0].real);
MKL_Complex16 *work = new MKL_Complex16[lworkLi];
if (test_if_symm){
zsytrf("U", NLi, matrix, ldaLi, ipivLi, work, &lworkLi, infoLi);
zsytri("U", NLi, matrix, ldaLi, ipivLi, work, infoLi);
for (i = 0; i < N; i++){
for (j = i + 1; j < N; j++){
matrix[i*N + j] = matrix[j*N + i];
}
}
}else{
zgetrf(MLi, NLi, matrix, ldaLi, ipivLi, infoLi);
zgetri(NLi, matrix, ldaLi, ipivLi, work, &lworkLi, infoLi);
}
delete[] dummywork;
delete[] work;
delete NLi;
delete MLi;
delete ldaLi;
delete[] ipivLi;
delete infoLi;
return;
}
void m_matrix_multiply(MKL_Complex16 *& matrix1, MKL_Complex16 *& matrix2, MKL_Complex16 *& matrix_res, int M, int N, int P, char * order, char * trans1, char * trans2){
CBLAS_TRANSPOSE tr1 = CblasNoTrans, tr2 = CblasNoTrans;
CBLAS_ORDER ord;
int prv, sec;
if (trans1 == "N"){
tr1 = CblasNoTrans;
prv = P;
}
else if (trans1 == "T"){
tr1 = CblasTrans;
prv = M;
}
else if(trans1 == "C"){
tr1 = CblasConjTrans;
prv = M;
}
if (trans2 == "N"){
tr2 = CblasNoTrans;
sec = N;
}
else if (trans2 == "T"){
tr2 = CblasTrans;
sec = P;
}
else if (trans2 == "C"){
tr2 = CblasConjTrans;
sec = P;
}
if (order == "R"){
ord = CblasRowMajor;
}
else{
ord = CblasColMajor;
}
cblas_zgemm(ord, tr1, tr2, M, N, P, &alpha, matrix1, prv, matrix2, sec, &beta, matrix_res, sec);
return;
}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marko,
thank you for the sharing. we will check them and the performance.
Generally speaking, right it is hard to see any obvious changes to improve to small matrix operation by any tips as the small matrix often means too less computation to find room to optimization.
Regarding zgemm, there are other functions seems save some computation time theoretically
cblas_?gemm3m
Computes a scalar-matrix-matrix product using matrix multiplications and adds the result to a scalar-matrix
product.
Syntax
void cblas_cgemm3m (const CBLAS_LAYOUT Layout, const CBLAS_TRANSPOSE transa, const
CBLAS_TRANSPOSE transb, const MKL_INT m, const MKL_INT n, const MKL_INT k, const void
*alpha, const void *a, const MKL_INT lda, const void *b, const MKL_INT ldb, const void
*beta, void *c, const MKL_INT ldc);
void cblas_zgemm3m (const CBLAS_LAYOUT Layout, const CBLAS_TRANSPOSE transa, const
CBLAS_TRANSPOSE transb, const MKL_INT m, const MKL_INT n, const MKL_INT k, const void
*alpha, const void *a, const MKL_INT lda, const void *b, const MKL_INT ldb, const void
*beta, void *c, const MKL_INT ldc);
Include Files
• mkl.h
Description
The ?gemm3m routines perform a matrix-matrix operation with general complex matrices. These routines are
similar to the ?gemm routines, but they use fewer matrix multiplication operations (see Application Notes
below).
or cblas_?gemmt
Computes a matrix-matrix product with general
matrices but updates only the upper or lower
triangular part of the result matrix
maybe you can try them.
secondly, do you have many of such kind of small matrix to do the computation?
If yes, you may try the batch gemm function
cblas_?gemm3m_batch
Computes scalar-matrix-matrix products and adds the
results to scalar matrix products for groups of general
matrices.
https://software.intel.com/sites/default/files/managed/7b/36/Batch-DGEMM-vs-GEMM-xeon-processor.png
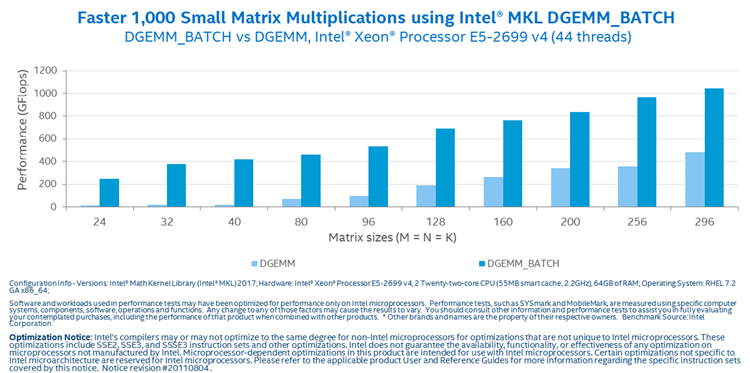{kind=link}
Best Regards,
Ying
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi everybody,
First of all, thank you for your effort and advices.I made a sample test program that compares mkl's zgemm and my implementations of matrix multiplication. Unfortunately it seems that my program is at least 2 to 2.5 times slower than mkl (which is expected, but I was full of hope after Sergey wrote the last message). Anyway i will post the code, what options I used in visual studio and if anyone can spot any errors, or give me some advice how to possibly accelerate my code, i would be very grateful. Even if the answer is negative, that is also good. So here goes the code:
#include <complex>
#include <cmath>
#include <vector>
#include <omp.h>
#include <Windows.h>
#include <algorithm>
#include <iomanip>
#include <iostream>
extern "C" {//
#include"mkl_cblas.h"
#include"mkl_lapack.h"
#include "mkl_service.h"
#include "mkl.h"
}//
using namespace std;
const complex<double> alpha(1, 0), beta(0, 0);
#define CACHE_LINE 64
#define CACHE_ALIGN __declspec(align(CACHE_LINE))
/************************************************************************//**
* @brief Checks if the matrices that are compared, are they the same
*
* @param[in] matrix1 First matrix to compare
* @param[in] matrix2 Second matrix to compare to first element by element
* @param[in] N Square matrix size
*
* @return true if they are same, false otherwise
*
*******************************************************************************/
bool check_if_matr_match(MKL_Complex16 *& matrix1, MKL_Complex16 *& matrix2, int N){
int i, j;
double matr_1_real, matr_1_imag, matr_2_real, matr_2_imag;
bool result = true;
for (i = 0; i < N; i++){
for (j = 0; j < N; j++){
matr_1_real = matrix1[i*N + j].real;
matr_1_imag = matrix1[i*N + j].imag;
matr_2_real = matrix2[i*N + j].real;
matr_2_imag = matrix2[i*N + j].imag;
if ((fabs(matr_1_real) > 1.0000001*fabs(matr_2_real)) && ((fabs(matr_1_real) < 0.9999999*fabs(matr_2_real)))){
return false;
}
if ((fabs(matr_1_imag) > 1.0000001*fabs(matr_2_imag)) && ((fabs(matr_1_imag) < 0.9999999*fabs(matr_2_imag)))){
return false;
}
}
}
return result;
}
/************************************************************************//**
* @brief Simple wrapper around mkl zgemm function
*******************************************************************************/
void m_matrix_multiply_mkl(MKL_Complex16 *& matrix1, MKL_Complex16 *& matrix2, MKL_Complex16 *& matrix_res, int M, int N, int P, char * order, char * trans1, char * trans2){
CBLAS_TRANSPOSE tr1 = CblasNoTrans, tr2 = CblasNoTrans;
CBLAS_ORDER ord;
int prv = 0, sec = 0;
if (string(trans1) == "N"){
tr1 = CblasNoTrans;
prv = P;
}
else if (string(trans1) == "T"){
tr1 = CblasTrans;
prv = M;
}
else if (string(trans1) == "C"){
tr1 = CblasConjTrans;
prv = M;
}
if (string(trans2) == "N"){
tr2 = CblasNoTrans;
sec = N;
}
else if (string(trans2) == "T"){
tr2 = CblasTrans;
sec = P;
}
else if (string(trans2) == "C"){
tr2 = CblasConjTrans;
sec = P;
}
if (string(order) == "R"){
ord = CblasRowMajor;
}
else{
ord = CblasColMajor;
}
cblas_zgemm(ord, tr1, tr2, M, N, P, &alpha, matrix1, prv, matrix2, sec, &beta, matrix_res, sec);
return;
}
/************************************************************************//**
* @brief Simple wrapper around my matrix multiplication function
*
* Bellow we have :
* #define simple_mat_mul this is the simplest implementation of a triple loop matrix multipication
* #define simple_mat_mul_better_vars in my original program when I changed the the variables to be like this, I got a 40% increase in speed, but in this test program it doesn't appear to be the case
* #define simple_mat_mul_transpose version where we first transpose the second matrix and then do the multiplicaton
* #define simple_mat_mul_openmp like the transpose version but with openmp using 4 threads
*******************************************************************************/
//#define simple_mat_mul
//#define simple_mat_mul_better_vars
//#define simple_mat_mul_transpose
#define simple_mat_mul_openmp
void m_matrix_multiply_mine(MKL_Complex16 *& matrix1, MKL_Complex16 *& matrix2, MKL_Complex16 *& matrix_res, int M, int N, int P, char * order, char * trans1, char * trans2){
int i, j, k;
#ifndef simple_mat_mul
double temp_var_1, temp_var_2;
double c1r, c1i, c2r, c2i;
MKL_Complex16 *temp_mat = new MKL_Complex16[P*N];
#endif
for (int i = 0; i < M; i += 1){
for (int j = 0; j < N; j += 1){
matrix_res[i*N + j].real = 0.0;
matrix_res[i*N + j].imag = 0.0;
}
}
#ifdef simple_mat_mul
for (i = 0; i < M; i += 1){
for (j = 0; j < N; j += 1){
for (k = 0; k < P; k += 1){
matrix_res[i*N + j].real += matrix1[i*P + k].real * matrix2[k*N + j].real - matrix1[i*P + k].imag*matrix2[k*N + j].imag;
matrix_res[i*N + j].imag += matrix1[i*P + k].real * matrix2[k*N + j].imag + matrix1[i*P + k].imag*matrix2[k*N + j].real;
}
}
}
#endif
#ifndef simple_mat_mul
#ifndef simple_mat_mul_better_vars
for (j = 0; j < N; j += 1){
for (k = 0; k < P; k += 1){
temp_mat[j*P + k] = matrix2[k*N + j];
}
}
#endif
#ifdef simple_mat_mul_openmp
#pragma omp parallel for private ( i, j, k, temp_var_1, temp_var_2, c1r, c1i, c2r, c2i) num_threads ( 4 )
#endif
for (i = 0; i < M; i += 1){
for (j = 0; j < N; j += 1){
temp_var_1 = 0.0;
temp_var_2 = 0.0;
for (k = 0; k < P; k += 1){
c1r = matrix1[i*P + k].real;
c1i = matrix1[i*P + k].imag;
#ifdef simple_mat_mul_better_vars
c2r = matrix2[k*N + j].real;
c2i = matrix2[k*N + j].imag;
#endif
#ifndef simple_mat_mul_better_vars
c2r = temp_mat[j*P + k].real;
c2i = temp_mat[j*P + k].imag;
#endif
temp_var_1 += c1r*c2r - c1i*c2i;
temp_var_2 += c1r*c2i + c1i*c2r;
}
matrix_res[i*N + j].real = temp_var_1;
matrix_res[i*N + j].imag = temp_var_2;
}
}
delete[] temp_mat;
#endif
return;
}
int main(){
LARGE_INTEGER dsd_starting_time, dsd_ending_time, dsd_elapsed_microseconds_time_mkl, dsd_elapsed_microseconds_time_mine;
LARGE_INTEGER Frequency;
CACHE_ALIGN MKL_Complex16 *matr_1, *matr_2, *matr_3, *matr_4;
unsigned long long int mkl_microsecond, mine_microseconds;
int num_repetition = 20, num_start = 2, num_stop = 200;
int iml_1, iml_2, i, j;
MKL_Set_Num_Threads(MKL_Get_Max_Threads());
QueryPerformanceFrequency(&Frequency);
///Loop to traverse matrix sizes from num_start to num_stop
for (iml_1 = num_start; iml_1 <= num_stop; iml_1++){
mkl_microsecond = 0;
mine_microseconds = 0;
///Loop how many times to get total time and then average it with num_repetition
for (iml_2 = 0; iml_2 < num_repetition; iml_2++){
matr_1 = new MKL_Complex16[iml_1*iml_1];
matr_2 = new MKL_Complex16[iml_1*iml_1];
matr_3 = new MKL_Complex16[iml_1*iml_1];
matr_4 = new MKL_Complex16[iml_1*iml_1];
for (i = 0; i < iml_1; i++){
for (j = 0; j < iml_1; j++){
matr_1[i*iml_1 + j].real = 0.01 + (double)rand() / RAND_MAX*120.0;
matr_1[i*iml_1 + j].imag = 0.01 + (double)rand() / RAND_MAX*120.0;
matr_2[i*iml_1 + j].real = 0.01 + (double)rand() / RAND_MAX*120.0;
matr_2[i*iml_1 + j].imag = 0.01 + (double)rand() / RAND_MAX*120.0;
matr_3[i*iml_1 + j].real = 0.0;
matr_3[i*iml_1 + j].imag = 0.0;
matr_4[i*iml_1 + j].real = 0.0;
matr_4[i*iml_1 + j].imag = 0.0;
}
}
///MKL zgemm part
QueryPerformanceCounter(&dsd_starting_time);
m_matrix_multiply_mkl(matr_1, matr_2, matr_3, iml_1, iml_1, iml_1, "R", "N", "N");
QueryPerformanceCounter(&dsd_ending_time);
dsd_elapsed_microseconds_time_mkl.QuadPart = dsd_ending_time.QuadPart - dsd_starting_time.QuadPart;
dsd_elapsed_microseconds_time_mkl.QuadPart *= 1000000;
mkl_microsecond += dsd_elapsed_microseconds_time_mkl.QuadPart;
///my implementation part
QueryPerformanceCounter(&dsd_starting_time);
m_matrix_multiply_mine(matr_1, matr_2, matr_4, iml_1, iml_1, iml_1, "R", "N", "N");
QueryPerformanceCounter(&dsd_ending_time);
dsd_elapsed_microseconds_time_mine.QuadPart = dsd_ending_time.QuadPart - dsd_starting_time.QuadPart;
dsd_elapsed_microseconds_time_mine.QuadPart *= 1000000;
mine_microseconds += dsd_elapsed_microseconds_time_mine.QuadPart;
///Check if the calculated matrices by both methods give the same (approximately the same) result
if (!check_if_matr_match(matr_3, matr_4, iml_1)){
cout << "ERROR, matrices are not same : " << iml_1 << "\n";
}
delete[] matr_1;
delete[] matr_2;
delete[] matr_3;
delete[] matr_4;
}
///Output average times for mkl and my implementation
cout << "Average times are (for size = " << iml_1 << " ): mkl : " << mkl_microsecond / num_repetition / Frequency.QuadPart << " mine : " << mine_microseconds / num_repetition / Frequency.QuadPart << "\n";
}
return 1;
}
So I work with MKL_Complex16 matrices, so complex double is in play (MKL_Complex16), I used mkl version 10.0.012 but I can switch to mkl 2017 if someone thinks it would help. I work in Visual studio 2013, the target architecture is ia 32, I am in release mode, and from additional settings in project properties, and other, I have:
- Debugging Environment _NO_DEBUG_HEAP=1
- C/C++ Optimizations /O2 and /Ot
- C/C++ code generation /MT and /fp:precise
- C/C++ Language /openmp
- Linker Optimizations /OPT:REF and /OPT:ICF
- Linker Advanced Image Has safe exceptions NO
- It is on windows (7 in my case)
- My CPU is Intel Core i7 2670 QM @ 2.20 GHz
If I missed something please let me know.
Additional questions:
1) Does openmp clash with mkl library or they can coexist in the same project? Is the above code correct in thos regard?
2) Is there any way to improve my codes execution times ?
3) If question 2) is a yes, and I can get it to be faster than mkl code for small matrices, is the same possible for matrix inversion?
Thank you all in advance :D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm not very familiar with the degree to which msvc supports AVX in 32-bit mode (why 32-bit mode?). Evidently, x87 mode won't be competitive (don't even bother with vec-report). As msvc doesn't support SSE3 code generation, you will have difficulty getting satisfactory performance with that compiler with /arch:SSE2. You may need to split your data into separate real and imag arrays in order to take advantage of SSE2 or AVX vectorization.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marko,
I did test on one machine i5-6300, Visual Studio 2015, release and 32bit model. with MKL 2017 update 2. Basically, when size < 32, your self code had better performance than mkl. INV operation is complex , so maybe same or better behaviors to use MKL instead of optimize your code.
Best Regards,
Ying
MKL_VERBOSE Intel(R) MKL 2017.0 Update 2 Product build 20170126 for 32-bit Intel(R) Advanced Vector Extensions 2 (Intel(R) AVX2) enabled processors, Win 2.40GHz intel_thread
MKL_VERBOSE ZGEMM(N,N,2,2,2,003F6290,00C9F4E0,2,00C97E90,2,003F6280,00C9F528,2) 68.62us CNR:OFF Dyn:1 FastMM:1 TID:0 NThr:2
Average times are (for size = 2 ): mkl : 124654 mine : 9908
MKL_VERBOSE ZGEMM(N,N,12,12,12,003F6290,00CB5B10,12,00CB5208,12,003F6280,00CB6418,12) 40.15us CNR:OFF Dyn:1 FastMM:1 TID:0 NThr:2
C:\Users\yhu5\Desktop\eigen\Fiona\Release>EU.exe
Average times are (for size = 2 ): mkl : 144 mine : 244
Average times are (for size = 12 ): mkl : 82 mine : 23
Average times are (for size = 22 ): mkl : 55 mine : 30
Average times are (for size = 32 ): mkl : 54 mine : 97
Average times are (for size = 42 ): mkl : 59 mine : 119
Average times are (for size = 52 ): mkl : 111 mine : 1196
Average times are (for size = 62 ): mkl : 146 mine : 342
Average times are (for size = 72 ): mkl : 171 mine : 546
Average times are (for size = 82 ): mkl : 271 mine : 781
Average times are (for size = 92 ): mkl : 516 mine : 783
Average times are (for size = 102 ): mkl : 477 mine : 1007
Average times are (for size = 112 ): mkl : 695 mine : 1440
Average times are (for size = 122 ): mkl : 768 mine : 1469
Average times are (for size = 132 ): mkl : 940 mine : 3289
Average times are (for size = 142 ): mkl : 2289 mine : 6033
Average times are (for size = 152 ): mkl : 1449 mine : 4930
Average times are (for size = 162 ): mkl : 2230 mine : 6156
Average times are (for size = 172 ): mkl : 2371 mine : 5887
Average times are (for size = 182 ): mkl : 2783 mine : 5961
Average times are (for size = 192 ): mkl : 3705 mine : 6690
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By the way, few weeks ago I encountered an article of Intel about Intel MKL for improvement in MKL when one wants to multiply many matrices by the same matrix.
Anyone knows the link to this article?
Thank You.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Royi,
do you mean another small matrix optimization compact format in MKL?
https://software.intel.com/en-us/articles/intelr-math-kernel-library-introducing-vectorized-compact-routines
One for larger matrix:
Packed APIs for GEMM
https://software.intel.com/en-us/articles/introducing-the-new-packed-apis-for-gemm
Best Regards,
Ying
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page