- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Robert Loffe,
Need your help here!
I am using Intel Iris 5200 GPGPU and Inel i7 4770R processor, Windows 8.1 as OS.
I am optimizing my below code snippet on Intel Iris:
global_size is 1920x1080
local size is kept NULL. I have left this to compiler.
__kernel void experiment(__read_only image2d_t YIn, __write_only image2d_t YOut)
{
uint4 best_suited=0;
uint4 temp =0;
int best_sum,ssum;
int2 coord_src = (int2)(get_global_id(0), 2*get_global_id(1)+1);
const sampler_t smp = CLK_FILTER_NEAREST | CLK_NORMALIZED_COORDS_FALSE | CLK_ADDRESS_CLAMP_TO_EDGE;
uint4 pixel1 = read_imageui(YIn, smp, coord_src + (int2)(-3,0));
uint4 pixel2 = read_imageui(YIn, smp, coord_src + (int2)(-2,0));
uint4 pixel3 = read_imageui(YIn, smp, coord_src + (int2)(-1,0));
uint4 pixel4 = read_imageui(YIn, smp, coord_src + (int2)( 0,0));
uint4 pixel5 = read_imageui(YIn, smp, coord_src + (int2)( 1,0));
uint4 pixel6 = read_imageui(YIn, smp, coord_src + (int2)( 2,0));
uint4 pixel7 = read_imageui(YIn, smp, coord_src + (int2)( 3,0));
/* Read luma pixels of next line */
uint4 pixel_nxt1 = read_imageui(YIn, smp, coord_src + (int2)(-3,2));
uint4 pixel_nxt2 = read_imageui(YIn, smp, coord_src + (int2)(-2,2));
uint4 pixel_nxt3 = read_imageui(YIn, smp, coord_src + (int2)(-1,2));
uint4 pixel_nxt4 = read_imageui(YIn, smp, coord_src + (int2)( 0,2));
uint4 pixel_nxt5 = read_imageui(YIn, smp, coord_src + (int2)( 1,2));
uint4 pixel_nxt6 = read_imageui(YIn, smp, coord_src + (int2)( 2,2));
uint4 pixel_nxt7 = read_imageui(YIn, smp, coord_src + (int2)( 3,2));
/* main loop: */
{
best_sum= abs_diff(pixel3.x,pixel_nxt4.x) + abs_diff(pixel4.x,pixel_nxt5.x) + abs_diff(pixel5.x,pixel_nxt6.x) -8;
best_suited.x = (pixel4.x+pixel_nxt2.x) >> 1;
sum = abs_diff(pixel2.x,pixel_nxt2.x) + abs_diff(pixel3.x,pixel_nxt6.x) + abs_diff(pixel4.x,pixel_nxt1.x);
if (sum < best_sum)
{
best_sum = sum;
best_suited.x = (pixel3.x+pixel_nxt3.x) >> 1;
sum = abs_diff(pixel1.x,pixel_nxt5.x) + abs_diff(pixel2.x,pixel_nxt6.x) + abs_diff(pixel3.x,pixel_nxt7.x) + 16;
if (sum < best_sum)
{
best_sum = sum;
best_suited.x = (pixel5.x+pixel_nxt1.x) >> 1;
}
}
sum = abs_diff(pixel4.x,pixel_nxt5.x) + abs_diff(pixel5.x,pixel_nxt2.x) + abs_diff(pixel6.x,pixel_nxt1.x);
if (sum < best_sum)
{
best_sum = sum;
best_suited.x = (pixel4.x+pixel_nxt3.x)>> 1;
sum = abs_diff(pixel5.x,pixel_nxt3.x) + abs_diff(pixel6.x,pixel_nxt4.x) + abs_diff(pixel7.x,pixel_nxt3.x);
if (sum < best_sum)
{
best_sum = sum;
best_suited.x = (pixel6.x+pixel_nxt2.x) >> 1;
}
}
}
/* Pix4(0,0) is the current pixel in below calculations */
write_imageui(YOut, coord_src, pixel4);
/* store the result: */
write_imageui(YOut, coord_src+(int2)(0,1),best_suited);
}I have tried the following things: 1) abs_diff is the inbuilt function and by replacing abs_diff with the bitwise code is not giving any improvement.
2) Analysed its performance using intel Vtune and saw execution units are idle for 30% of time. GPU memory read is 7.6GB/sec and write is 3.942GB/sec.Number of L3 cache misses is close to 177x10^9 and Computing Thread are close to 35 lacs. Also Sampler Bottlenecks are 8.3%.
Thinking further: 1) I don't know whether reading the data in local memory will benefit me or not. Since local memory cache line access is same as accessing L3 cache on intel architecture. And reading via image api's I am already accessing the cache memory for image objects i.e. Texture memory. The only help I can think can be reducing sampler bottlenecks if I write code something like this: __local smem [256] ; smem[get_local_id(0) = read_imageui(YIn, smp, coord_src);
2) I also don't know what should be the optimal work group size here.
Can anyone explain me in full detail how this code can be optimized?How can I reduce my execution idle time, computing threads, L3 cache misses and increase my GPU memory read and write access. If you can re-write the code that will be really helpful.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Robert,
Any Comments here, please!
-Manish
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Manish,
Sorry for the late reply: I am swamped by internal requests and meetings.
Looks like abs_diff is not your real problem here: it is reading a lot of data in a work item that is the issue.
Don't think moving to local memory will help you much here. You might try it, though, just to make sure. You might also try switching to buffers instead of images.
Reordering image reads might help, e.g.
uint4 pixel1 = read_imageui(YIn, smp, coord_src + (int2)(-3,0));
uint4 pixel_nxt1 = read_imageui(YIn, smp, coord_src + (int2)(-3,2));
and then the rest in a similar fashion.
You can also run experiments on the best work group size via Code Builder/OpenCL Kernel Development/Run Analysis feature. It can come up with a better than 0,0 workgroup size. Please see this link https://software.intel.com/en-us/node/530794 on how to go about this.
You might also consider using the following Intel extension: https://www.khronos.org/registry/cl/extensions/intel/cl_intel_subgroups.txt, specifically shuffle functions to minimize and reuse data pulled by different work items - this might make your code unportable, though.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Robert for reply.
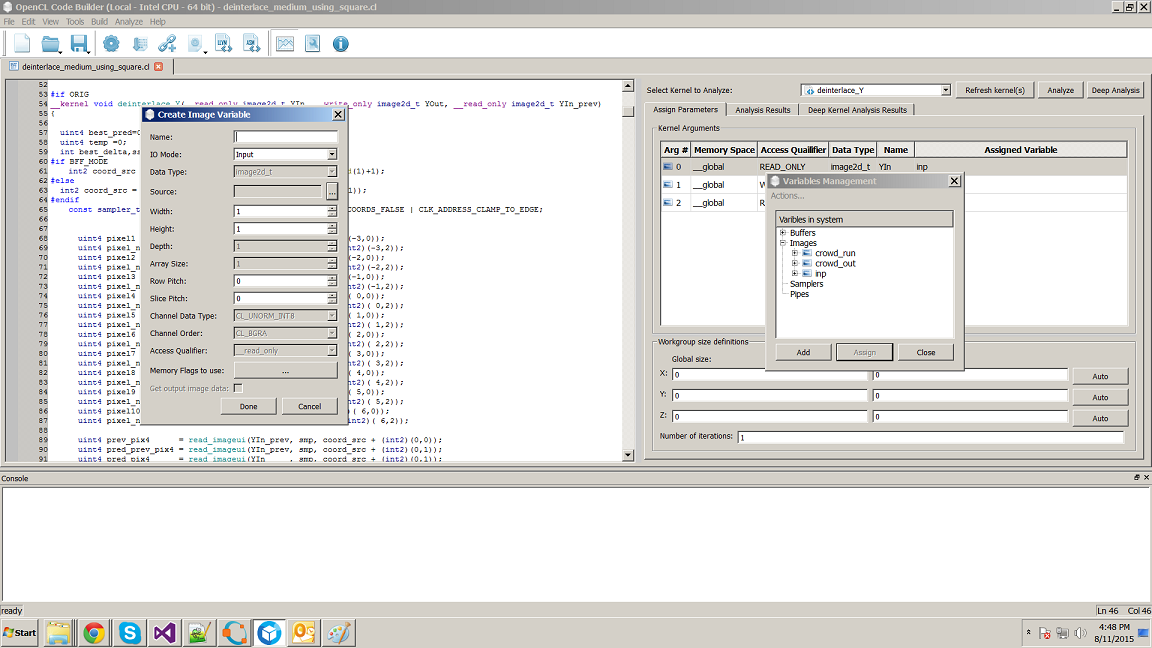
I have tried the reordering but no improvement or degradation is seen here. Also I treid using Code builder to get the best work-group size, However, I am getting the CL_INVALID_IMAGE_DESCRIPTOR error. Also the channel order in the assigned variable is fixed by defalut. I am not able to change this. Pelase see the attachment.
I was able to increase the performance by processing four pixels per work item instead of one pixel per work item. However EU execution units are active for only around 40% of time and idle for around 35% of time. Can this be improved?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Manish,
What graphics driver version do you have? Do you have the latest and greatest version of Code Builder? What about your version of Visual Studio? Very weird that you cannot alter channel order.
If processing 4 pixels works for you, you need to try processing 8 pixels, and also things like 4 by 2 or 4 by 4 pixels. You maybe bandwidth limited in this work load, so EU units idle maybe OK.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Driver Version is 10.18.14.4251.
Code Builder Version 1.4.0.25. Visual Studio 2013 Community Edition.
When I tried increasing the group size I saw the Computing Threads got reduced but GPU read bandwidth to 9GB/s and write bandwidth to 3GB/s from 14GB/s and 8GB/s respectively. Can you tell me how much should I get around?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Manish,
The best you can do on this chip is ~50GB/s read BW and ~40 GB/s write BW. Realistically, on the 1920 by 1080 image, You could get ~31 GB or read BW and ~17 GB of write BW using buffers in ideal situations. For images, I measured ~14.7 GB/s BW for simple read/write kernels. For buffers, it was ~15.5 GB/s. But this is for simple kernels. When running an optimized Sobel kernel, which does a lot more reads in a work item, I got about 8.9 GB/s on a 1024 by 1024 image and 11.9 GB/s on a 2048 by 2048 image, so a total BW ~10.5 GB/s in your case should be achievable.
Could you send me your 4-pixel kernel for analysis? The best I can do on your 1 pixel kernel is ~3 GB/s with the WG size of 16 by 8.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Robert!
Fortunately I was able to run the Code Builder Analysis using Visual Studio. and I was able to find the best work group size is 32,4.
But I would say there might be some bug with the standalone application of Code Builder 64 bit, due to which I am not able to change the Channel order while assigning the variables.
I might not be able to share the full code due to client rights. However, thanks for your support.
If you can provide me any way to further optimize this algo in OPENCL and Iris GPGPU.
Also, I have few questions in my mind if you can answer:
What is the minimum work group size I can select for a group?
What is the maximum work group size size I can select?(I know its always mentioned in specs of device, But I want to know the parameters on which the maximum size is decided).
Why for the above written kernel code we are getting 16 by 8 has the best work group size and not other sizes. I am not able visualize it.If you can provide a detail explanation that will be helpful.
Regards,
Manish Kumar
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page