- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm trying to move a Monte-Carlo Fortran program using OpenMP from Xeons to the PHI. The program scales very well on Xeons but very badly on the PHI. I've attached some plots to quantify our results. The program is not huge but the data that the threads access -- only as reads -- are several GBytes. The data are mostly contained in two arrays which are not accessed sequentially while the code is running. The plots are all normalized to the same time for one thread as the focus is on the shapes of the curves, not the absolute values.
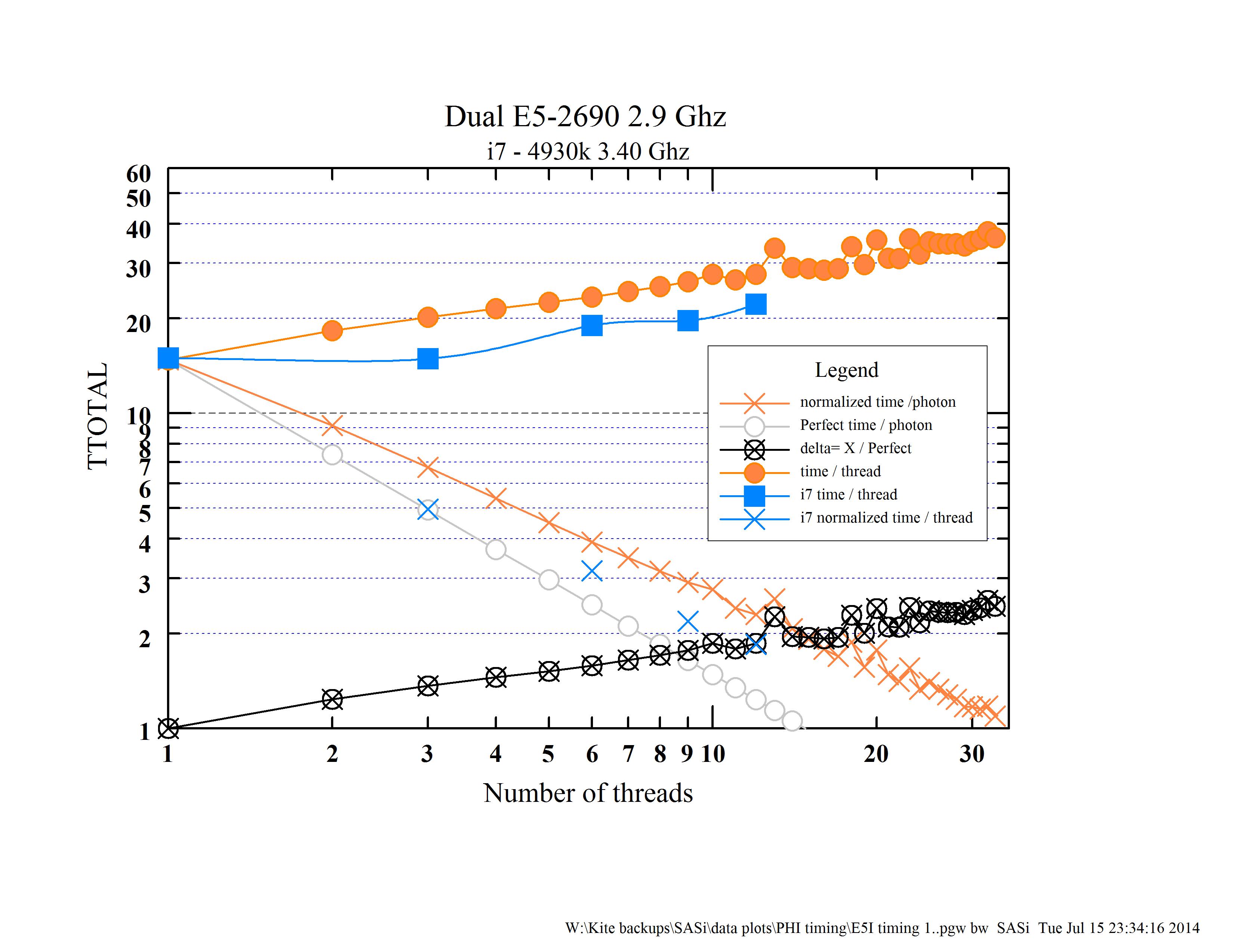
The plot "Intel Comparison plot a" summarizes the results for two Xeon computers (dual E5 w/ 32 threads & an I7 w/ 12 threads) and the PHI. The PHI is much slower than the Xeons. It starts off 20x slower for the first thread, which is not so bad but gets much worse quite rapidly. The two types of Xeons show little sign of fading, even with all the threads available on the I7 & E5 and the fact that the code is very (80%) back-end bound. The code was designed to be quite scalable (although not very vectorizable). This is shown in more detail in the E5I timing plot. The grey line shows perfect scaling and the Xeons show no sign of flattening out with the number of threads. The bumps at 13, 18 threads, and the few in the mid 20s are real, not statistical fluctuations. Don't understand those. Interestingly, the I7 is faster than the E5.
However, as shown in more detail in the "PHI timing 1" plot, at about 8 threads, the PHI results get quite flat and stay so until somewhere over 100 threads when they pick up steam again. In the end, the PHI ends up being about 100x slower than would be a Xeon with the same number of threads and using all the PHI threads is 4 - 5x slower than the 32-thread E5 setup. These results are pretty much the same no matter how we set the affinity (doesn't matter anyway, I think, as we want to run with all threads).
Our only thought so far is that there is something about the ring bus that is hosing up the access to the large arrays. We have not been able to think of a way to get around this or to decide exactly what is causing the problem way before we even get to one thread per core. We expected to get good scaling at least until we got to 56 threads. Any thoughts on this would be greatly appreciated.
thanks,
{kind=link}
{kind=link}
{kind=link}
Link Copied
- « Previous
-
- 1
- 2
- Next »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
*** In addition to my suggestion above, you might consider an alternative, which if doable, with have a much higher payback. This might be done without rearranging the indexes.
Your subroutine freeplnv, if this is called from a
do ln=1,nLns
call freeplnv(ln,...)
Then see if you can process vectors of particles (or whatever you want to call them)
a(1:nLns) = datinlns(1:nLns, izkm, 4)
dnudop(1:nLns) = datinlns(1:nLns, izkm, 5)
...
This would depend on if you can use your izkm across the vectors (1:nLns,...)
The potential payback (10x) might be well worth a couple of days of thought time.
Jim Dempsey.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Only H is a function; datinlns is the large array. We've swapped around the indicies in both the Xeon & the PHI w/o significant improvement. Note, on the PHI, that the L1 hit rate is 97%; if it doesn't hit in the L1, it pretty much ends up in memory after wasting time looking through the other cores L2 caches.
We have tried to vectorize Freep1nv but it is slower, probably because the search for the best dL is very efficient.
The H function was discussed several months ago but we re-did it for more accuracy which, on some machines, is slower than the previous version, on others, faster! But, for completeness, here it is:
function H(u,a)
real :: H
real, intent(in) :: u, a
i= (1000* abs(u))
if (i .lt. 0) then
print *,i,H2(i),u , "From H, i < 0 !!" !it seems to be happening
i= 20000
endif
if(i.gt.12099) then
!cc outside of table use far wing formula p229 Gray.
u2=u*u
u4=u2*u2
Hsub1=0.56419/u2 + 0.846/u4
Hsub3=-0.56/u4
! print *,a,i,u,Hsub1,Hsub3,"a,i,u,Hsub1,Hsub3"
H=a*(Hsub1+a*a*Hsub3)
! print *, H,"end top"
return
endif
!use table function
!cc H= H0(i)+ a* H1(i)+ a*a* H2(i)+ a*a*a* H3(i)+ a*a*a*a* H4(i)
H=a*H4(i)
H=a*(H3(i)+H)
H=a*(H2(i)+H)
H=a*(H1(i)+H)
H=H0(i)+H
return
end function H
end module H_module
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
H= H0(i)+ a* (H1(i)+ a* H2(i)+ a*a*(H3(i)+ a* H4(i)))
should offer a small reduction in latency and possibly improved accuracy.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- « Previous
-
- 1
- 2
- Next »