- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
I'm checking out my code's "CPU Usage Histogram" and I have a fairly significant overhead in the function kmp_launch_thread. Is there any way to reduce this time? I have tried varying KMP_AFFINITY with only minor improvements. I'm at a loss. I realize I'm not giving a whole lot of information, so just let me know what you need (system info, code snippets, etc.).
Thanks in advance!
Enlace copiado
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
> I have a fairly significant overhead in the function kmp_launch_thread
Usually it indicated many threads were invoked (kmp_launcd_thread's CPU time was accumulated) but ran shortly, since tasks were tiny in these threads. ...using KMP_AFFINITY doesn't help, please control OMP threads' number and extend threads' life.
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
>>>Is there any way to reduce this time? I have tried varying KMP_AFFINITY with only minor improvements>>>
I am not sure if anything significant can be done. AFAIK kmp_launch_thread can be calling OS threads further in the call chain in order to spawn new threads. So it can have significant overhead at start time of your app. Bear in mind that thread creation task is costly in terms of CPU cycles.
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
What VTune analysis do you use? If you use collection with stacks could you please switch to Call Stack Mode on filter bar to "User/system fucntion" mode and see if CPU distribution is different and what function consums it while it is not attributed to _kmp_launch..
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
Peter, no matter the thread number, the kmp overhead is large. I vary from 1 to 4x #cores.
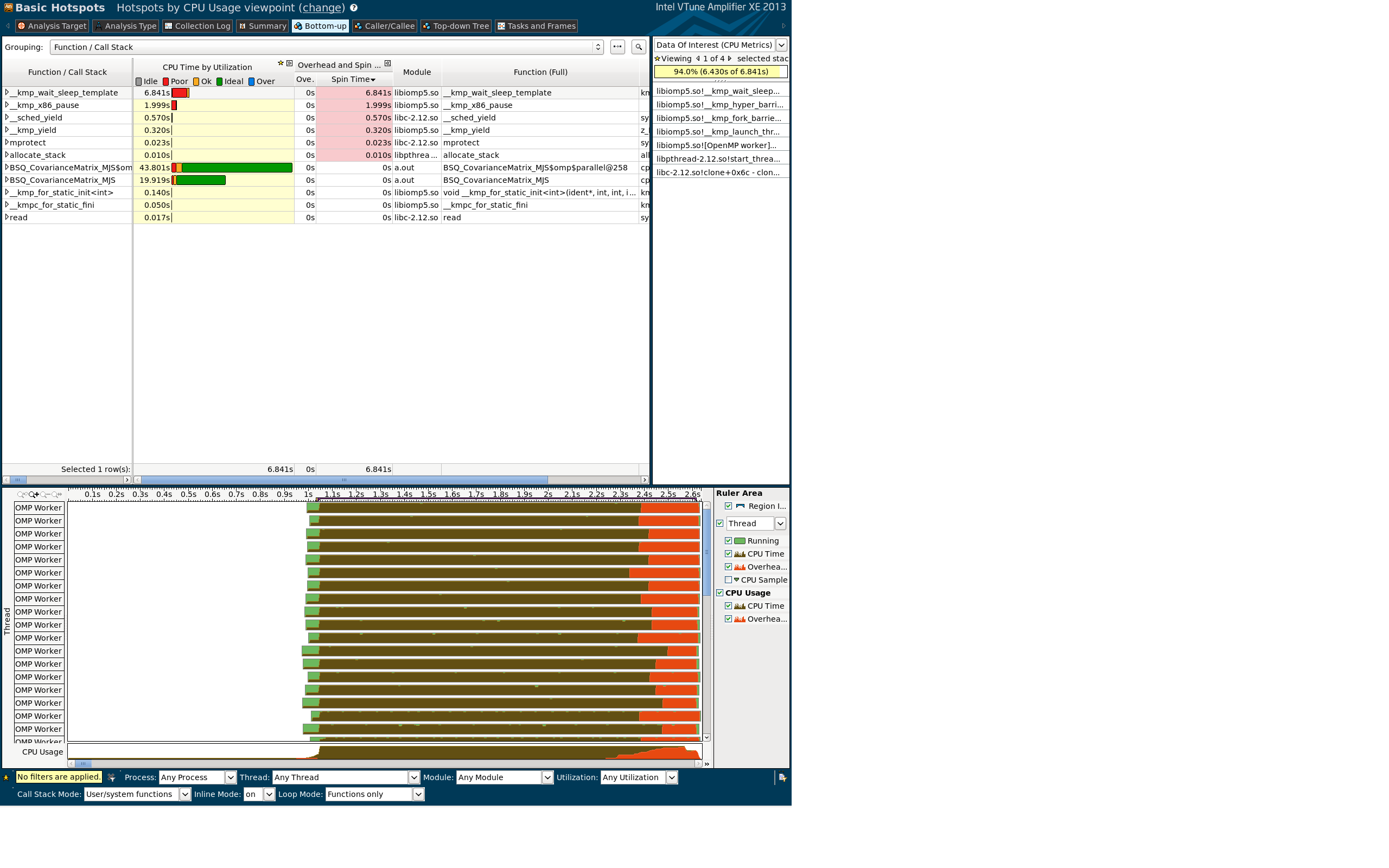
Dmitry, I've just been using the "Basic Hotspots Analysis." I'm not sure where the filter bar you're talking about is located. I've attached a screenshot snippet of what my CPU Usage Histogram looks like.
Thanks for the help!
{kind=link}
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
@Matt S
Is there an option to disassemble main$omp$parallel function? Maybe there is a call to OS system function and the perceived delay is on the side of OS kernel.
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
@ Matt S
You had 48 threads to run on 4 cores box, so overhead was high. Many time on spin locks and context switch.
You need to reduce thread number to logical cores, and run task more time on these threads. Another thought is to reduce spin locks, or put spin lock in small code region, etc to reduce wait time or wait count.
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
@Peter
Good point.
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
Before jumping to conclusiont we need to be sure that overhead attribution to kmp_launch by VTune is correct.
Matt, on the picture below is the knob that will allow you to disable reattribution from system to user.

- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
{kind=link}
{kind=link}
{kind=link}
- Marcar como nuevo
- Favorito
- Suscribir
- Silenciar
- Suscribirse a un feed RSS
- Resaltar
- Imprimir
- Informe de contenido inapropiado
Hello Matt,
Thank you for the screenshots - they explain things - the spin time actually happened on a barrier (kmp_wait_sleep..) but VTune attributed it to kmp_launch_thread - will think how to improve that not to be misleading.
So you have OpenMP imbalance when there were threads that finished their portion of work earlier than others and dis spinning on a barrier.
You can try dynamic schedule if you have parallel loop like
#pragma omp parallel for schedule (dynaic, <chunk_size>)
where chunk_size a number of iterations that will be assigned to a worker thread. You might not point chunk_size having it 1 by default but if you have a big number of iterations you might see overhead on work sheduling. Experiment with this stuff.
Also supporting advice on limiting the number of threads with the number of cores.
Thanks & Regards, Dmitry
- Suscribirse a un feed RSS
- Marcar tema como nuevo
- Marcar tema como leído
- Flotar este Tema para el usuario actual
- Favorito
- Suscribir
- Página de impresión sencilla