- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am having issues on implementing the "Feed-Forward Design Model with Buffer Management". Bare in mind that this is not the first implementation but the last of many attempts. I described my gathered knowledge so far and appreciate any help:
1- I am using OpenCL version 17.1 on an Arria 10 platform.
2- The problem to solve is to organize data coming from a pipe into buffers (large, global memory buffers) that are then used by other kernels or host.
3- The kernel writing to pipe must never stall (or its buffer must be enough to hold the data).
I have implemented the following ping-pong buffer like solution:
kernel 1: "StreamingToPipe" (streams the data to pipe with a know pattern to later be checked).
kernel 2: "Producer" reads the pipe from kernel 1, writes to a buffer and sends tokens to the consumers when data is available.
kernel 3 & 4: "ConsumerA" and "ConsumerB" when data is available they copy a fragment of the buffer requested by "producer" to a host allocated buffer.
HOST:
4 independent queues, each one executes 1 kernel.
The 2 queues on the consumers use callbacks to gather the data and check the patterns. Consumers are enqueued first.
Both examples showed below use the same kernels but change the host code:
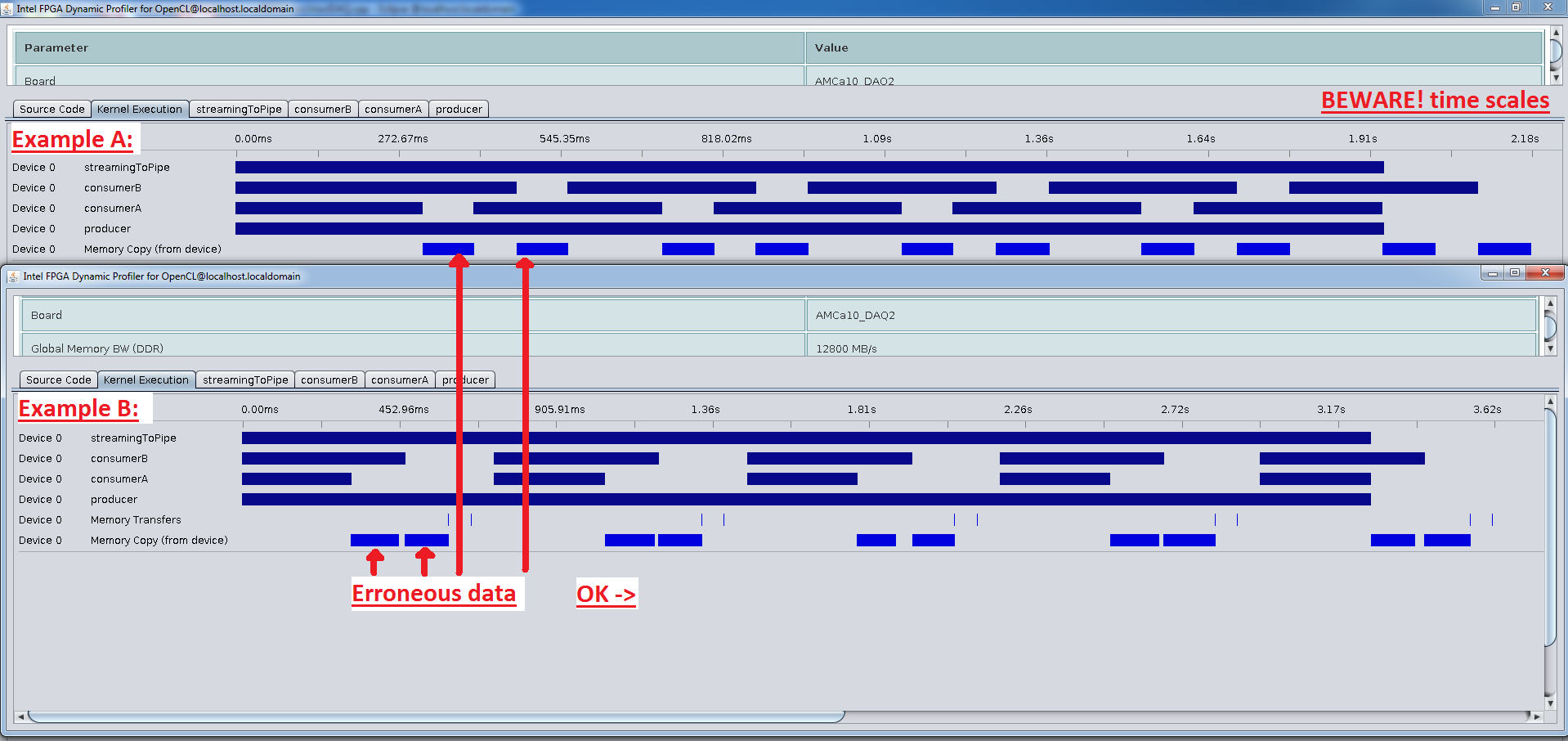
EXAMPLE A:
Uses enqueueMapBuffer calls to manage data transfers to host.
EXAMPLE B:
Uses enqueueReadBuffer calls to manage data transfers to host.
PROBLEMS AND QUESTIONS:
I have followed the guidelines and advices from best practices guide to use mem_fences. Consumers end, which is supposed to guarantee memory consistency.
- Example A manages better throughput. But the number of maximun enqueued kernels is low (seems like even when unmapping buffers, data is somehow still stored on RTE and an Error is raised when resources are depleted).
- Example B the queues for each consumer enqueues the NDrange execution and the enqueueReadBuffer alternatively. However, consumer A and B end up synchronized when they should not be (Higher stall rate and lower overall throughput). The number of kernels I can enqueue with this method does not seem to saturate (good memory handling)
- On BOTH examples the data on the first 2 buffers (one for each consumer) is inconsistent (data does not check with the patters, from element 8192 onwards). The rest of the buffers are correctly checked on HOST.
- The models that worked even worse that I tried are:
- Single consumer feed-forward (more buffer incosistencies)
- Event synchronized queues (having no events and synchonizing by blocking channels caused better management).
- Creating a host side-buffer pool to send different buffers each time to the consumers. (Idea taken from the 19.1 introduced "Double Buffered Host Application Utilizing Kernel Invocation Queue" example).
Any comment on what is going on with the RTE is appreciated.
The code is pretty much the same as the intel programing guide example for managed buffers but modified to use 2 consumers.
Thanks.
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page