- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I am interested in developing some instructions which can do the bignum operations (like adding two operands of 1024 bit) and hence by plan to implement a simple Full Adder like this: {carry,sum} = OP_A + OP_B; I am a beginner in Altera and realized that I can develop an IP component with Avalon MM slave interface which can talk with the NIOS II processor. I was wondering how to give the bignum values as the operand from the NIOS II processor (master) to the IP component (slave) from the application code? I see only these macros in the generated 'io.h' file: # define IOWR_32DIRECT(BASE, OFFSET, DATA) io_write((BASE_APB_ADDR) + __AVL_TO_APB((alt_u32)((BASE) + (OFFSET))), DATA, (BASE) + (OFFSET)) # define IORD_32DIRECT(BASE, OFFSET) io_read((BASE_APB_ADDR) + __AVL_TO_APB((alt_u32)((BASE) + (OFFSET))), (BASE) + (OFFSET)) I guess these are the 32 bits write and read instructions. So, do I get to clock in the 1024 bits as a single instruction? Or do I have to wait for 32 clock cycles (sampling the 32 bits in a clock cycle, do for 32 clocks. Please say a no to this..) ! Hope that question is clear and someone can respond. Really appreciate it. Thank You, AkhilLink Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would use the 5 bit C field (with writerc == 0) to select the operation.
That way you only need one custom instruction.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
After giving it several thoughts, I have decided on to have some sort of implementation like this: BIGNUM IP core: With a 1024 bit Avalon master interface with on-chip memory to read the operands into the operand registers as suggested by Ted. With a 32 bit Avalon master interface with NIOS ii to decide on the address from which we can read the operands. The 1024 bit on-chip memory interface will copy the value from memory onto the registers only if valid addresses are read using this 32 bit interface first and the values will be read from those valid addresses. This 32-bit interface also gives the 'opcode' interface for an operation to perform, as requested by the NIOSII. Like if the data read is 0, it corresponds to BIGNUMADD, if the data read is 1, it corresponds to BIGNUMSUB etc. So I will add a user note saying please exclude the 'opcode' values from being used as the operand read addresses. I did not see any edge of using a custom instruction with the IP core for the below reasons: 1) If the IP core has to get values from the custom instruction, then the NIOS II should talk with the custom instruction first, then the custom instr. send the output to the NIOS II and then the NIOS II has to give those values to the IP core. 2) I did not see any such custom instruction interface in the Avalon Interface spec. (I saw clock, reset, interrupt, MM, ST, tristate etc) 3) The custom instruction does not do anything specific in this scenario, O/P = I/P. So we can avoid an overhead. Instead, I plan to use another 32 bit MM master interface in the IP core as described above. Please correct me if I miss something here. I really appreciate everyone's patience. Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- Please correct me if I miss something here. --- Quote End --- There is no technical reason why you can't use a secondary Avalon-MM Slave port for the control activity, and that may very well be a better starting point for you, since you only have to learn one interface (Avalon-MM, but two different directions). The main reason (I see) for using custom instructions is the higher performance you should be able to achieve. (as dsl noted in post# 8 of this thread, NIOS IORD_ and IOWR_ macros [and the underlying hardware interactions] are relatively slow). In the end, for this component the control aspect is a relatively small portion of where your development time is going to be spent, so it is definitely something you can easily revisit later for performance or other reasons.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Ted,
Thank you for the reply! Now I understand that the custom instruction is faster than an IP core. I have just one more question here. How is it possible to create a custom instruction interface (?) in an IP core? I think in your design you plan to have such an interface (if my understanding is correct) I have read the Avalon interface manual (for sopc) and I do not see any interface of that sort. I have seen clock, reset, interrupt, MM, ST, Tristate etc. Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- How is it possible to create a custom instruction interface (?) in an IP core? I think in your design you plan to have such an interface (if my understanding is correct) I have read the Avalon interface manual (for sopc) and I do not see any interface of that sort. --- Quote End --- Yes I see the details are "light" to "non-existent" on how to do it via TCL. Probably the easiest way is to use Qsys (File->New Component) and then from the component editor use the Templates menu to add the type of instruction you would like to add. For what it's worth, I personally like editing the TCL manually, so I would just get the tool to generate the first round of port definitions and then copy&paste that into my own .tcl file. (I have had trouble with the Component Editor in the past, and I do not like it).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for the reply! I think it is high time for me to move on from SOPC to QSYS, right? I guess SOPC builder may not have the above feature.
(The templates menu to add the type of instruction to the IP core). I checked the SOPC and I could not see that tab. And you mean to say you rely on the hw_*.tcl file scripting than the GUI based SOPC builder? Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- Thank you for the reply! I think it is high time for me to move on from SOPC to QSYS, right? I guess SOPC builder may not have the above feature. (The templates menu to add the type of instruction to the IP core). I checked the SOPC and I could not see that tab. --- Quote End --- Yes, you should use Qsys. I believe even if you launch SOPC Builder in the latest edition, it will give you a "Not recommended for new designs" type of message. --- Quote Start --- And you mean to say you rely on the hw_*.tcl file scripting than the GUI based SOPC builder? --- Quote End --- Yes, but this is only my personal preference. If you search on here, you will find people having trouble using the graphical Component Editor so I know I am not alone. The TCL is not complicated (but unfortunately for custom instructions, I can't find a TCL reference).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for the explanation, Ted! Glad that I met you here who knows how to explain clearly, for a beginner in Quartus II like me.
So I am just confirming the tentative design to make sure we on the same page. Please see the attached diagram which shows the entire design for a typical RSA application. The NIOS II core uses the RSA IP core to implement the RSA in hardware. The RSA IP core talks with the BIGDIGITS IP core to get the desired bignum functionality. The control path will be from NIOS II -> RSA -> BIGDIGITS. And as you pointed out, the BIGDIGITS will have a custom instruction interface for the control signal to increase the speed. The functionality of that custom instruction is, output = input. It just passes along the address (for both the operands) and the 'opcode' to perform for the BIGDIGITS. The data path will be from the on chip memory to the BIGDIGITS IP core. Hope the above design is an okay one for me to start implementation in Qsys (I need to learn that as well, huh ! I had so far been an SOPC guy.) Thank You, Akhil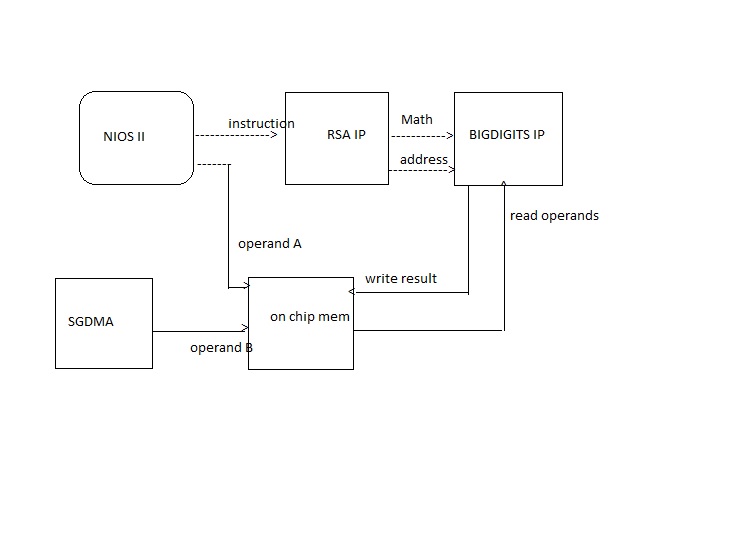{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A gentle bounce.
Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your block diagram looks OK. The bottleneck is going to be the "operand A" path from NIOS to onchip memory. I'm not familiar with the specific algorithm you are implementing: is "operand A" going to be generated from the body of a nested loop, or is it going to be generated only once (as an input parameter) before the algorithm/loops execute?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Ted,
The operand_A path and operand_B path to on_chip memory is just a tentative design. I can implement an RSA algorithm which generates the two prime numbers (operand_A and operand_B internally (the RSA IP core can take care of that). Just in thoughts of a future enhancement (the thought that BIGDIGITS IP should be an IP core that can be used with any application which can accept two input operands to use) I plan to use the data path. And as you pointed out, that might be a bottleneck. However I do not need to clock in the operand_A from the body of a nested loop. In fact, I plan to clock-in the data before the algorithm/loops execute. Also please note that if I need to clock-in 1024 bits of data, I need to do that for 32 clock cycles, 32 bits every cycle. (also please cross check that my understanding of the custom instruction is correct, i.e, the way it passes the addresses to the BIGDIGITS IP core) Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- Hello Ted, The operand_A path and operand_B path to on_chip memory is just a tentative design. --- Quote End --- OK, yes in reality your system will likely have additional components as well and they will all fit into the shared 32-bit address space seen by NIOS and SGDMA. It looks fine. --- Quote Start --- (also please cross check that my understanding of the custom instruction is correct, i.e, the way it passes the addresses to the BIGDIGITS IP core) --- Quote End --- Yes I believe you have got it correct. Good luck!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Ted,
Thank you for the kind explanations and the patience.. Really appreciate that. Now I really need to learn the modules (the SGDMA, the QSYS interconnects, IP core development etc). Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Off late, I am asking a question which I should have asked some time before. I have seen the way an application code can be accelerated using the C2H compiler at the link http://www.altera.com/literature/ug/ug_nios2_c2h_compiler.pdf This looks like a promising approach since I have the application code for RSA handy with me and I have to identify the bottlenecks (may be I can use the code profiling method). So, instead of developing a handwritten IP core design and verilog hardware, will it be a good approach if I can use the C2H compiler for the hardware acceleration? I am not a great programmer in Verilog, however I am okay in C/C++. One trade off I see here is, the C2H compiler cannot create accelerator for QSYS systems, it works only with the SOPC builder. Is there any altera gurus who can comment on the above concepts and trade-offs, that would be a huge help before I kick start the real implementation. Best, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The C2H compiler is mostly discontinued - I suspect it didn't really work very well.
More probably people tried to feed it inappropriate C and it generated far too much vhdl to be in anyway useful.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Even if it were supported / popular, I don't think C2H approach will be a good fit for you.
For starters, I think what it will try to do is generate a non-bursting Avalon-MM Master with 32-bit width for reading, writing your data. So you will spend many clocks loading/storing, and then it will generate possibly a lot of HDL to make your math execute in a single clock. Overall, I think you would not be satisfied with the result.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From what I heard you need to write your C code in a special way to limit the poor performance of the generated hardware (i.e. write HDL in C ;). In the best cases it generated not-so-efficient hardware (faster than the software version, but a lot slower than a real HDL implementation) and in the other cases it wouldn't recognize a part of the C code structure and would fail (with a more or less understandable error message). Besides, as others said here it isn't maintained any more and doesn't work with QSys.
I think your two best options for a better performance are either to run the software on a hardcode processor (either outside the FPGA, or by using one of the new Cyclone V with ARM cores) or take the time to convert it to HDL. Converting an algorithm written in C to HDL isn't very straightforward, because you often need to rethink completely the algorithm implementation. With hardware you can have more parallelization, and have a more efficient flow by using pipelining, but on the other hand the order of execution and the data flow can be quite different. Using a profiler is indeed the first thing to do. If you see that some functions are used a lot more than others, you can start thinking about what kind of hardware could replace them.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello dsl,
So there is no point in spending time on the C2H compiler stuff since that is being discontinued, right? I believe that is the reason QSYS builder does not have a C2H support. Thanks, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Daixiwen summed up what little I know of C2H.
You also need to answer the question 'How fast do I need it to go?' not 'How fast can I make it go?' A single core on a typical desktop system is probably 100 times faster than a niosII. You are very unlikely to 'win' by offloading something - unless it is something that VHDL is good at, or you have real-time constraints.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
For some reason the comments given by Ted and Daixiwen went unnoticed for the last couple of days. Thank you for the nice explanation ! and thank you dsl for the final summation regarding the assessment of the C2H and the speed of the NIOS II processor. I think as Daixiwen pointed out, I need to use the profiler to see the individual function usage profile in the entire algorithm. Thank You, Akhil- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm not sure I'd use the profiler, it's statistical nature (usually based on timer ticks) means it is of limited use.
You can probably guess which parts of the code take time, implement a TSC instruction and use it to count the number of cycles taken to get through the code sections. Use the elapsed time to generate a histogram of how long each section takes. I have these defines:#define STAMP_SET(stamp) (stamp = SYS_CLK_COUNT())
# define STAMP_COUNT(array, stamp, factor)
do {
unsigned int new_stamp, bucket, count;
new_stamp = SYS_CLK_COUNT();
bucket = ((new_stamp - stamp) & ((nelem(array) - 1) << (factor))) >> (factor);
count = array + 1;
stamp = new_stamp;
array = count;
} while (0) which I use to generate 64-entry histograms of the execution time of code blocks. I've a comment that says the above costs about 10 clocks - I can't remember if that includes the Avalon read to get the cycle count. Since my code runs from tightly coupled instruction/data memory and the few Avalon xfers are usually uncontended the clock counts I get match those I calculate from the object code. SDRAM accesses perterb things somewhat (but I don't have many of those). To get the code to run fast(er): 1) Ensure functions that can be inlined are inlined, try to get everything inlined (if code space permits). Mostly this reduces register pressure. 2) Try to use global register variable(s) to access static data (ie put it all in a single 'struct'). This generates slightly better code (even after my patches to gcc) than using 'small data'. With care you can use %gp as the global register. Without this the compiler will need a register to reference each global - and I've seen it have two registers pointing to the same global. 3) Ensure your C doesn't force the compiler to keep re-reading variables from memory (eg because a write via a 'char *' might overwrite the same location). 4) Avoid having too many live values in a function, gcc will create virtual registers and then spill them to stack. Sometimes it is necessary to force gcc to write the register values out to memory (asm volatile ("":::memory) is your friend here). 5) Avoid read delay stalls. gcc hasn't been told about these properly. Sometimes you need to force a read early. 6) Find out how to disable the dynamic branch predictor, and set all the branches with correct static prediction. 7) I could carry on .... I got considerable speedup from the above - and after I thought I'd made a good jod of the code!
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page