The new problem I encountered, the quantization of ssd-mobilenet-v2 failed to obtain the correct mAP, the error is as follows, please refer to the attachment link for details.
pot -c ssd_mobilenet_v2_license_plate_new_raw_pos_300x300_0525_qtz.json --output-dir backup -e
INFO:compression.algorithms.quantization.default.algorithm:Computing statistics finished
INFO:compression.algorithms.quantization.default.algorithm:Start computing statistics for algorithms : MinMaxQuantization,FastBiasCorrection
INFO:compression.algorithms.quantization.default.algorithm:Computing statistics finished
INFO:compression.pipeline.pipeline:Finished: DefaultQuantization
===========================================================================
INFO:compression.pipeline.pipeline:Evaluation of generated model
INFO:compression.engines.ac_engine:Start inference on the whole dataset
Total dataset size: 30
30 objects processed in 0.488 seconds
INFO:compression.engines.ac_engine:Inference finished
INFO:app.run:map : 0.0
INFO:app.run:AP@0.5 : 0.0
INFO:app.run:AP@0.5:0.05:95 : 0.0
Please help me experiment and teach me how to solve it. Maybe my .json is wrong. Thank you for your careful help!!!
链接已复制
Hi Jacky0327,
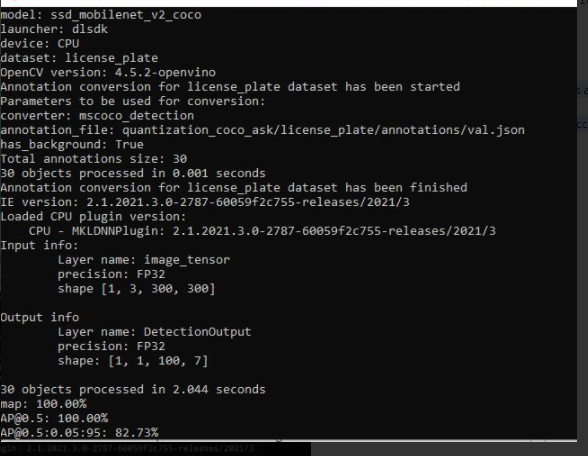
Thank you for your patience. Here are our findings. The error derived from the generated annotation file whereby the SSD model predicts classes started by 1 while val.json contains all objects with class 0. This has resulted that the metric defined cannot find any matches detected by class and return the result as 0. This can be resolved by adding the parameter has_background:true in the annotation_conversion section in the quantization/accuracy checker config:
"annotation_conversion": {
"converter": "mscoco_detection",
"annotation_file": "quantization_coco_ask/license_plate/annotations/val.json"
"has_background": true
},
Once changed, you will manage to obtain the results like the screenshot below.
Some additional input, there is a small bug in the script where "license plate" is a single class name which consists of 2 words, but in categories, it was defined as {0: "license", 1: "plate"}, however, this is minor and does not influence on model accuracy.
Regards,
Aznie
{kind=link}
Hello, I am glad you can reply to me,
Regarding your answer, I understand. When I modify the json in your way, I get exactly the same result, nothing has changed at all.
Regarding the script for generating val.json, I have also changed it to license_plate, making her the first class.
Could you please share your modified json for my own reference?
I may not need accuracy_checker.yml, I need pot.json, thank you.
The instructions I gave are as follows:
pot -c ssd_mobilenet_v2_license_plate_new_raw_pos_300x300_0525_qtz.json --output-dir backup -e
{kind=link}
Hi Jacky0327,
From your screenshot I noticed you are putting the has_background parameter in the preprocessing part. You have to put the has_background parameter inside the annotation_conversion part as below:
"annotation_conversion": {
"converter": "mscoco_detection",
"annotation_file": "quantization_coco_ask/license_plate/annotations/val.json"
"has_background": true
},
Regards,
Aznie
Hi Jacky0327,
I am glad to hear that. Therefore, this thread will no longer be monitored since this issue has been resolved. If you need any additional information from Intel, please submit a new question.
Regards,
Aznie