- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
DateRep,Day,Month,Year,Cases,Deaths,Countries and territories,GeoId,Pop_Data.2018
25/03/2020,25,3,2020,2,0,Afghanistan,AF,37172386
21/03/2020,21,3,2020,2,0,Cape_Verde,CV,543767
10/03/2020,10,3,2020,-9,1,Cases_on_an_international_conveyance_Japan,JPG11668,
2/03/2020,2,3,2020,0,0,Cases_on_an_international_conveyance_Japan,JPG11668,
1/03/2020,1,3,2020,0,0,Cases_on_an_international_conveyance_Japan,JPG11668,
The death data file for the Corona Virus is in the above format. I had a small play with the data in C# but run into graphing problems, I am translating the program into Fortran - there appear to be some interesting features in the FFT of the data, which I hope to publish to help the health stat people.
Does anyone have a good idea for reading the line and then taking apart into
21/03/2020 -- ignore
21 integer to 0 on first line all integers the name is different character length, CV is usually only 2 chars and the population is an integer, but is pop missing from the JPG line and the id is not two characters.
There is a new file every day
Regards
John
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry it took so long to get back to you, but it does mean Fast Fourier Transform. Although it is food for thought.
There will be many PhD's written in the next 100 years on the COVID statistics.
I was looking at the CSV file for acceleration data. The comment yesterday by mecej4 on the use of C# prompted me to think about the problem of finding the comma's and the way it is done in C#.
I think this is the simplest code to solve the problem:
bits = 0
do k = 1, 100
READ (sRT, '(A)', IOSTAT=IOstatus)iline1 ! Read line
IF (IOstatus < 0) EXIT ! if end-of-file reached, exit
Num = Num + 1 ! no, have one more value
count = 1
do 120 j = 1, 127
comma = iline1(j:j)
write(*,'(A)')comma
if(comma .eq. ',') then
bits(count) = j
write(*,*)k,count,j
count = count+1
end if
120 end doThanks for the idea.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John Nichols has displayed semi-log plots and has conjectured some death rates based on exponential growth models. Such models correspond to linear autonomous differential equations. Realistic models of predator-prey interaction, financial collapse or infection propagation are linear only in the early stages of a rare event. With exponential growth/decay, the only possibilities are reaching infinity or zero (plus, perhaps, a nonzero offset or bias).
Consider a more reasonable model that is simple, but nonlinear: the SIR model, please see https://www.medrxiv.org/content/medrxiv/early/2020/02/13/2020.02.12.20021931.full.pdf . That model can be represented in terms of three ordinary differential equations. If we scale (by N) the three dependent variables (number tested and found susceptible, S, number tested and known to be infected, I, and the number removed -- by death or recovery -- R, by the sum of the three, N = S+I+R, which is estimated to be a few percent of the total population Ntot, and is assumed to be fixed, because the population is isolated, and births are not counted), u = S/N, v = I/N, w = R/N, and scale the independent variable t by 1/(α.N), we obtain the following nonlinear ODEs:
du/dτ = - u v, dv/dτ = (u - λ) v, dw/dτ = λ v
with initial conditions u = 1 - 1/N, v = 1/N, w = 0 at τ = 0. Please note that u + v + w = 1 at all times.
Note that after scaling the problem has only two parameters: the coefficient λ = ρ/αN in the ODE, and the initial value parameter, 1/N.
Here is Matlab code to integrate the equations and display the results.
The "function" definition file, "sir.m":
function df = sir(t,f) global lambda df = [-f(1)*f(2); (f(1)-lambda)*f(2); lambda*f(2)]; end % https://www.medrxiv.org/content/medrxiv/early/2020/02/13/2020.02.12.20021931.full.pdf % Dependent variables: fraction susceptible and not infected; fraction infected; fraction removed;
The Matlab script to solve and display, "rsir.m":
global lambda
lambda = 0.72338; %https://www.medrxiv.org/content/medrxiv/early/2020/02/13/2020.02.12.20021931.full.pdf
g0 = 0.1; y0 = [1-g0; g0; 0]; % initial conditions
[t,y] = ode45('sir',[0 10],y0);
figure(1); clf; plot(y(:,2),y(:,3)); xlabel('Infected'); ylabel('Removed'); grid
figure(2); clf; plot(t,y(:,1),t,y(:,2),t,y(:,3)); xlabel('scaled time'); ylabel('fraction of susceptible population');
legend('still susceptible','infected','removed'); grid
My apologies to the forum moderators and those readers who find this response blatantly off-topic, and irrelevant to Intel Fortran. The topic is definitely of current interest if not concern, and John Nichols is the one who led me astray (sorry, John!).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, I will do this again, I lost the first effort when I tried to load a png file and I was told that it could only be so many pixels. I offer no apology for starting this post. I am using Intel Fortran to do some statistical analysis for a bunch of health statisticians around the world. I was plugging along quite nicely on Wednesday working on my bridge monitoring stuff and looking at starting an NSF proposal and listening in the background to CNN on Alexa and heard Gov Cuomo talk about the death and the infection data. He said that there was a dip in the data, and that intrigued me. We see dips in human data and it is not always significant I also have a very good friend in Northern Italy and I have been worried about my friend, his family and all the people I worked with from the area in the last five years. So I decided to take a few minutes and have a quick look.
I found the COVID-19-Geographic Data from Europe. It is in CSV format and it was quite easy to tear apart my bridge monitoring program and cobble together a C# program to do some analysis. C# handles CSV easily and MATH.NET is not to bad. A great statistician showed me a method that takes the linear regression, determine the residuals and then do a FFT on the residuals. The GS is now at Macquarie University in Sydney. FFT = Fast Fourier Transform.
The plot I got out is in the attached zip file. You can use Paint.NET to blow it up and look at the bottom left corner. The axes are not relevant really the shape of the FFT is important. I finished it on Thursday and sent it off to the GS and thought - there is nothing really there. I will not bore you with her response - but she saw some patterns and then showed me what the broadly distributed group were doing. This is Friday morning and I said a few bad Hindi words and then I sent the GS a note to say I would help.
It took 2 milliseconds to decide that the work had to be done in FORTRAN and using DISLIN. The decision was easy I needed access to Jim, mecej4 and "He who shall not be named" to help with all the problems that would arise and to get MKL. I can only talk to you through this forum and I offer no apologies to Intel. Of course if a Intel Moderator wants to talk to me there is the private message channel and I will respond.
Reading a CSV file in Fortran is a pain in the butt, luckily Jim has helped a lot.
Yes, there are some models we can make, I have been thinking about that model for a few weeks, when we have solved the GS's problem, which is a publically available program to do plots of the daily data, we can turn to the larger problem. The early data is somewhat linear in log time and we are looking for the bend point and the waves. So the program will produce plots of the daily data and let someone who is sitting in Sydney use the program, someone who does not write Fortran -- this group - me excluded is very good.
Step one is linear regression, step 2 is residuals and FFT. The GS asked for specific FFT plots. I can assure you I am no where her class at looking at the FFT data, but this small group is able to provide these people with the data in a form they can use.
So I will keep asking questions. I know you will all help, which is all I ask. If an Intel Moderator tells me to stop then the next step would be a brief phone call to R Swann's office. I know that is not going to happen, Intel is just to good to make such a stupid political mistake. They are intelligent.
So now I go back to it.
PS: the best model would be to create a huge model of all people and their relative location to other people and then turn a virus loose on one person, -- it would be Brownian motion in fast motion. The issues are interaction rates and infection rates and human conditions. Run it a million times -- need an Intel supercomputer.
We have so much data we could probably get a good idea of the currently asymptomatic - no one can measure that directly at the moment.
So mecej4 - this is done in Fortran because of you and Jim and one other. My apologies.
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think some of these charts may need to be presented in a different manner.
Most of the published charts show number of (tested) infections and death (subset of infections) per total population for each country/region, or world in total.
I think an equally important chart would be:
(new infection since last sample) / (population of region - accumulated persons infected of region at last sample)
And additionally:
(new infection since last sample) / (estimated number of contagious persons)
I am not a statistician, I would not know how to factor in the unknowns (as all of the populous is not being continuously tested)
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>PS: the best model would be to create a huge model of all people and their relative location to other people and then turn a virus loose on one person, -- it would be Brownian motion in fast motion.
The above model (something like a diffusion problem) assumes people do not travel, they only mingle locally.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
jimdempseyatthecove (Blackbelt) wrote:>>PS: the best model would be to create a huge model of all people and their relative location to other people and then turn a virus loose on one person, -- it would be Brownian motion in fast motion.
The above model (something like a diffusion problem) assumes people do not travel, they only mingle locally.
Jim Dempsey
The model would need to have access corridors where people move so we have area a with 1000 people, area b with 1000 people and a transport system between them -- so we model houses , roads, planes etc.. internal movement and interplace movement - really hard.
Yes the plots were for a start and not for an end.
The GS understands - but we need to do better
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1. The Europeans went back to the old format -- yeah
2. 188 US 90 484 411 246 249 211 119 131 80 110
US death data start - 484 is yesterday - you can see the wave on top of the main line
Human death data often does this -- we have had deaths on 90 days so far. - Tomorrow will be 600 -800 is my guess
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Last picture is the chinese data -- they are most likely lying -- the curve would not look like this in only 40 days
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the help on this and the MKL Forum.
I enclose the first plot as a PDF. The linear regression is performed on the
YB(i) = log10(YA(i))
So I was wanting opinions on how I should present the regression equation on the graph to explain to people how it is derived.
Also how would you annotate the axis and what other information to show on the graph -- it has to be understandable by a undergrad level student.
This is the Belgium data, Teh X axis is days -- I will have to go back and fit into the data the days they leave out.
Thanks
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I make the assumption that 0 is really 0.1 -- it has to be something for this to work.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
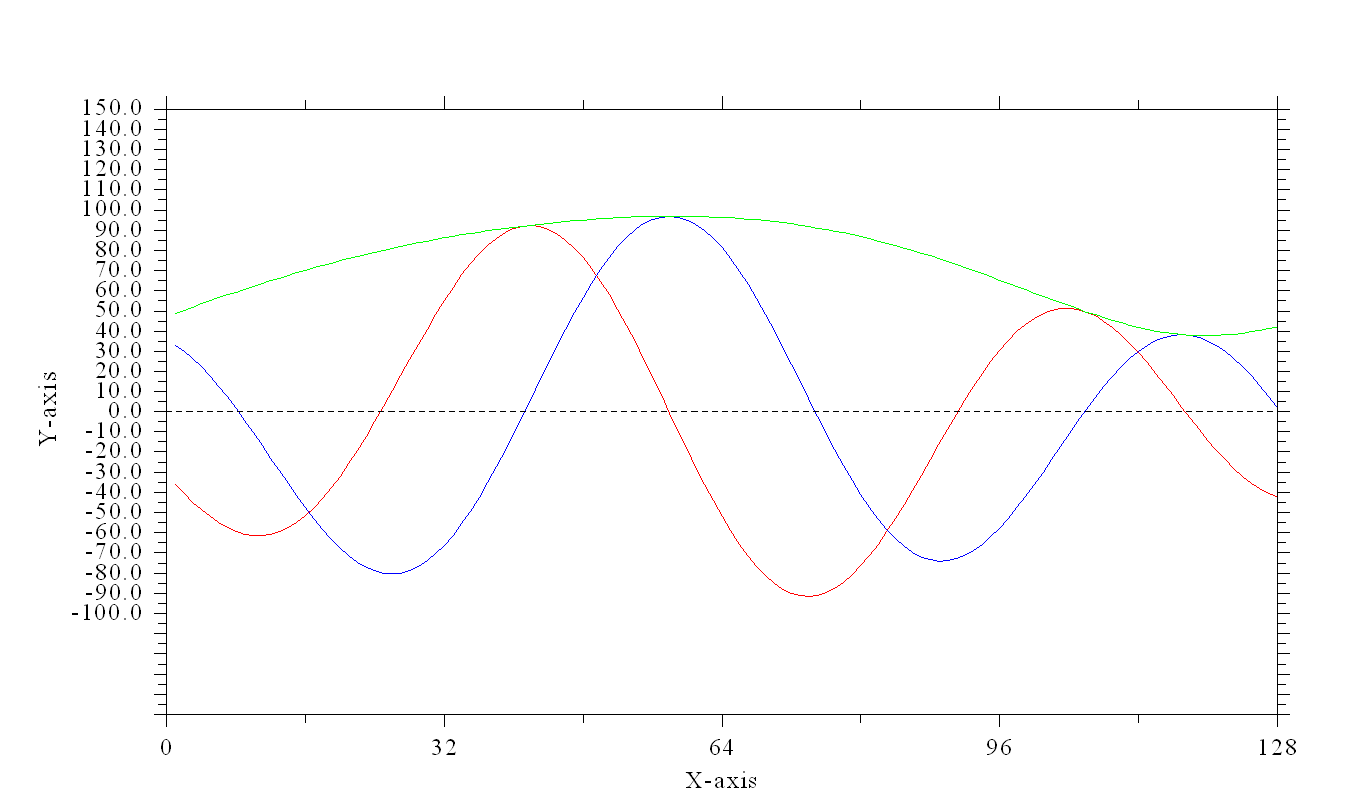
I got the FFT running, this is the Belguim data - now I need to normalize it so it makes sense.
MKL is a problem to get going with DISLIN --
It is a lot smoother than I thought --
red is real amplitude and blue is phase angle data
Question: How do I package up the finished program so I can ship it to the others so it can run on any computer?
Thanks
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
dateRep,day,month,year,cases,deaths,countriesAndTerritories,geoId,countryterritoryCode,popData2018
The European data was again contaminated today -- the line above shows the contamination. If I look at the data in NOTEPAD++ you cannot see the characters. I printed them out with Fortran write statement and they look as shown on the figure.
I can see them in VEDIT -- but few people have an editor like VEDIT.
My guess is the people are saving the data as CSV format from EXCEL - they check it with NOTEPAD or similar - I solved the problem in Fortran by brute force, but is there a way to actually check for these characters and ignore them? IN FORTRAN.
The death toll yesterday was 574, I had estimated 600 to 800 -- the +- is about 40 per day per country at this level. I thought we would hit 1000 by Friday -- my guess is Thursday.
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John, what you are seeing is a UTF-8 encoded file. See: https://en.wikipedia.org/wiki/UTF-8
This file format prepends a 3 byte header identifying it as UTF-8 and default character set (in this case USASCII). The UTF-8 format also can contain an (UTF-8)escape sequence to permit alternate character set.
If you open the file in WordPad you will see it sans the three header bytes (as well as any other "junk to you" should (UTF-8)escape sequence be embedded).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The projection in #35 does look bad. However, New York has started trials of the Hydroxychloroquine, the trial data (quantity) and test results data have not yet made it into the Daily Deaths. John, If you can also obtain daily death rates from other contributing factors (eliminate travel and work related) to chart with your data. This might be informative..
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is the US data for today - the r squared is high and the line is not dropping -- the problem is the new cases is about 10 days in advance of this --
The Fortran issues
dateRep,day,month,year,cases,deaths,countriesAndTerritories,geoId,countryterritoryCode,popData2018
The European data is again contaminated with non ALPHABET characters and numbers. They supply the data as a CSV file clearly saved from an EXCEl file.
How do I look for these characters and ignore them in Fortran? I have worked out a brute force method -- but there has to be a subtle solution?
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is the next stage -- stat analysis of the infected rate, this graphs shows the hope of Dr Fauci for a downturn - if this is real and not just poor reporting then the pain is worth it -- the only true measure is the death rate -- that is the only one we have reasonable confidence in
The analysis is now finding errors in the European data --
These are EXCEl graphs to show me how to do it in Fortran
The problem is Houston and Dallas are not yet engaged in the infections
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jim:
Thanks for the information -- I understand now -- the problems are:
1. there is not a single data source, the CDC data is very hard to find -- personally I think this is delibrate
2. there are errors in the data so there is no great QA. When the data is 12 standard deviations then one starts to look at it and that takes time.
3. I am trying to make this automatic - so your ideas are next week.
IF we are lucky we will level off at 6000 to 10000 per day.
John
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page