- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
we recently changed from Intel Composer 2011 to Intel Parallel Studio 2017. We noticed a severe slow down (factor of 100) in the ** operator (i.e., pow function) in our fortran code base. It seems to be more or less insensitive to the optimization flags used.
I would be very grateful if someone could provide a work around (flags, etc.) to avoid this problem. This slowdown took us by surprise as you would expect the newer compiler to be faster.
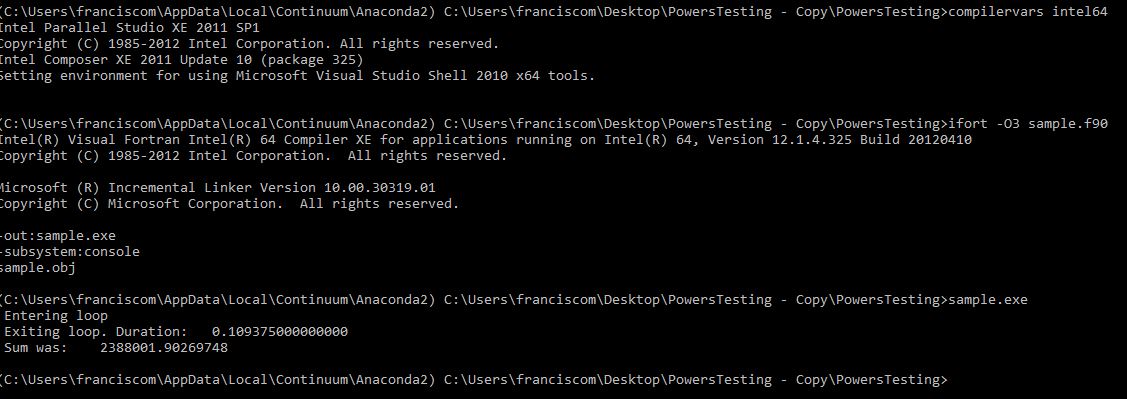
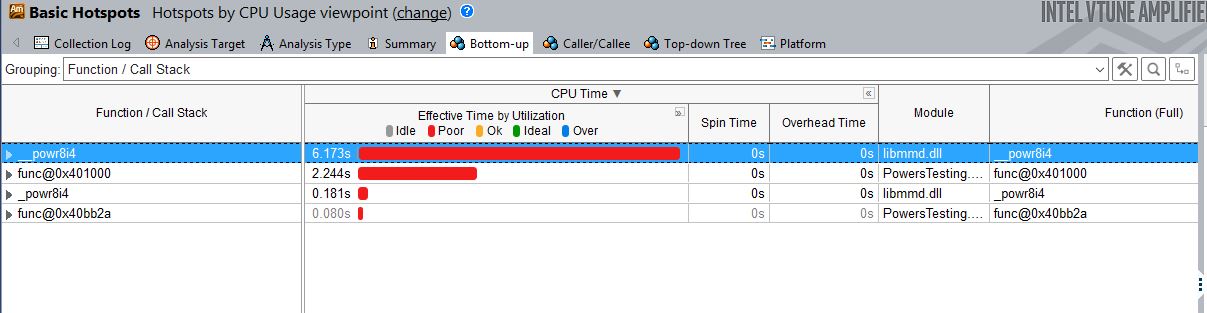
I wrote a very simple program that shows the problem (attached) and when you profile it (see snapshot attached) it can be clearly seen that the main culprit is the function _powr8i4.
When one compiles this simple program with Intel Fortran Version 17.0.4.210 the sample program takes about 7.5 secs in my local machine. On the other hand, when compiled with Version 12.1.4.325 it takes only about 0.1 secs !!! (See attached snapshots of command line)
Obviously, we prefer not going back in compiler version, so any work around would be appreciated.
Finally, I know that the sample loop is NOT the best way to program that loop. I just wanted to produce something simple that reproduces what we see.
Cheers,
Francisco
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
An analysis and answer from Intel people is required as soon as possible.
Moreover information about changes applied to basic math functions should be given to developers.
Regards
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, those power evaluations in the innermost loop are expensive. They are also unnecessary. By replacing the innermost ten lines as shown below, I was able to increase the speed by a factor of about 15.
real*8 pp,qq
...
pp = 1d0
do jj=1,11
qq = 1d0
do ii=2,12-jj
!Super slow line
sum1 = sum1 + a_assoc(ii,jj) * qq* pp*DBLE(ii-1)
qq = qq*sdrho
enddo
pp=pp*sdt
enddo
There is still more room for improvement. The multiplication by pp can be moved out of the inner loop by forming partial sums.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mecej4,
thank you for your fast reply.
I am well aware that there are many ways of re-writing the loop and improve the efficiency. However, that is not my question:
My question is, simply put: "Why is this loop slower in ifort 2017 than in ifort 2011?"
And maybe: "Is there a flag that can guarantee that such loops are at least as fast in ifort 2017 as as they were in 2011?
Cheers,
Francisco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you wish to have a chance of common subexpressions being seen the same by various compilers, you would use parentheses, and regroup the operands to permit this.. If you wish to avoid parentheses, placing the loop invariant part of the expression ahead of the varying part has a better chance, but there is no guarantee. It happens only because the compiler machinery may be shared with C where left to right evaluation of products is set by the C standard, but the default Intel options discard this aspect of the standard.
Also, if you wish to understand when simd optimizations occur, it is important to examine the compiler reports. You have several options there; I prefer /Qopt-report:4 (although it was different in the older compilers). I'm not prepared to guess whether the different compiler versions handle the inner loop exponentiation differently.
I would guess that Sham's expansion of the inner loop exponentiation could inhibit simd optimization, regardless of whether you set !$omp simd reduction(+: sum1) to make your intent clearer. Stretching my guessing instinct, the old compiler could be more aggressive with simd optimization, as it didn't support the OpenMP 4 syntax for the cases where you "really want" the optimization.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I suspect that the optimizer detected that nothing in any of the loops changed with icycle, and detected that it was enough to run through the outer loop once instead of 50,000 times. As a timing benchmark, the sample code does not succeed. How do the two compiler versions fare when you use them on the actual application code that you are developing?
You can insert OpenMP directives to control the optimizer and look at the optimization reports.
Or, you could add some code into the loop that does not take much time to execute but prevents the optimizer from doing away with the loop. If you want to pursue this, you could something along the lines of
...
c=0
do icycle = 1, ncycle
call sub(icycle,d)
c = c+d
end do
print *,c
in the main program, and move the i, j, ii, jj loops into SUB.
In the actual application (not sample.f90), you could consider storing sdrho**(ii-2) in an array, say, SDR, as a preparatory step. Then, use SDR(ii) in place of the expression in the innermost loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
An analysis and answer from Intel people is required as soon as possible.
Moreover information about changes applied to basic math functions should be given to developers.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
mecej4 wrote:
I suspect that the optimizer detected that nothing in any of the loops changed with icycle, and detected that it was enough to run through the outer loop once instead of 50,000 times. As a timing benchmark, the sample code does not succeed. How do the two compiler versions fare when you use them on the actual application code that you are developing?
It's all legacy code, thousands of lines. And a notable slowed down is observed when using the newer compiler.
If the older compiler could do such a nice optimization as you suggest, why can't the newer one do it?
Given the answer by Tim, it is possible that the Intel team decided to make less aggressive optimizations in order to support other features (e.g., openMP 4). However, it would be nice to know what those trade-offs were and how I can disable/enable them at will.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As you wait for a response from Intel, you can use a profiling tool such as Vtune to establish how many times __powr8i4 was called in the EXEs produced by the two compiler versions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fran,
Thank you for your report.
Please submit the ticket via Online Service Center for our compiler engineering to investigate further.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I initially suspected this would be as hypothesized by mecej4, with the icycle loop being optimized away (a common problem with small test codes). However, it turned out to be more complicated. Only the version 12 compiler runs it so quickly; a quick estimate suggests that there can't be a full pow function call for every iteration. All earlier and later compilers are slower.
What I think is happening is that the version 12 compiler fully unrolls the two inner loops. It computes the powers of SDT by multiplication and I think precomputes the powers of SDRHO, so there are no function calls such as powr8i4. Curiously, the inner loops seem to be fully unrolled only for matrices of order 9, 10, 11, 12, 13 but not for smaller ones.
For any compiler version other than 12, the inner loops are not fully unrolled by default. The powers are computed by calls to powr8i4. For 18.0, the inner loops do get fully unrolled for matrices of order 8 or less. For higher orders such as 11, adding the directives
!dir$ unroll(11) do jj=1,na !dir$ novector do ii=2,na+1-jj
causes both loops to be fully unrolled and the calls to powr8i4 are eliminated. It runs ~20X faster, though still a factor of 2 slower than 12.1. It might be that 12.1 somehow figured out that it didn’t need to loop over all values of i and j, just a triangle.
When to fully unroll is a matter of tuning, what works well for one application may work badly for another. I have escalated this to the compiler developers to consider whether improvements could be made to 18.0 that don't negatively impact other applications. In the meantime, you could add these directives to your code, or make some of the improvements suggested by mecej4 above. If you experiment by varying the order of the matrix assoc_int_drho, e.g. by increasing it to 15, you may see that the 18.1 compiler with the directives is very much faster than the version 12 compiler, with or without directives.
The impact of unrolling and avoiding calls to math library functions is so great, that vectorization is not so important to this particular code (and there isn't a SIMD version of powr8i4). However, it's possible you might be able to get additional speedups by doing OpenMP explicit vectorization in addition to the loop unrolling.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Francisco,
You may not want to know how optimising the loop can change the performance of your sample code, but it would be interesting to see the change in performance of the original loop to a "hand crafted" loop for different compiler versions and compiler options.
I ran the attached program with gFortran and was surprised by the lack of improvement gained by removing the ** operator, while varying the optimisation level gave more performance influence for both loop tests.
I'd be interested to see the change between the 2 loop tests for different versions of ifort. Should Ver 12 provide minimal change while Ver 17 more substantial, that would confirm the problem being identified, although the reality can sometimes be different.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As Martyn pointed out, different compiler versions perform different optimizations. As I pointed out, you can expect differences among compiler versions which you might avoid by writing your source code so as not to depend on them. It's possible that Intel was given a test case which was broken by the optimization you refer to in 12.0 (maybe in combination with something else which had to change in later versions). For just one example, adding in too many optimizations could make the compiler hang with extremely large source codes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here are some timing results to support the comments in #12. All runs were made on a Dell XPS-17 with Windows 10-64, CPU: i2720QM.
Version Opt Time with ** Time (s) 18U1-64 /Od 16.5 2.44 18U1-64 default 10.1 0.094 14U4-64 /Od 16.8 2.45 14U4-64 default 9.4 0.078 11.1-64 /Od 15.2 1.78 11.1-64 default 9.0 0.66 Windows 10-64, i7-2720QM.
The test program is the sample code of #1, with a second hand-optimized version added (see msample.f90, attached). On a different system (Linux server with Xeon E5-1560), Gfortran 7.2 -O3 ran the calculation in half the time when the power evaluations were optimized as in the second half of this code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It would be interesting to see the test in #13 also performed using Version 12.1.4.325 and Version 17.0.4.210. This would give some understanding of how the historical changes to optimisation have effected **, or perhaps more limited to this particular code example.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John Campbell wrote:
It would be interesting to see the test in #13 also performed using Version 12.1.4.325 and Version 17.0.4.210. This would give some understanding of how the historical changes to optimisation have affected **, or perhaps more limited to this particular code example.
Those are the compiler versions mentioned in the OP's reports, so OP can run msample.f90 and share the timings. It would also be useful to have the profiler (Vtune or other such tool) provide counts for powr8i4 rather than time. If, as I suspect, the counts differ between the results for 12.1 and 17.0, we can conclude that the issue is not the speed of the powr8i4 library function, as the title of this thread and the original post suggest, but the number of times that the function gets called, which is at the mercy of the optimizer.
Here is a "back-of-the=envelope" calculation that is useful. The code of #1, if executed sequentially and the calculations of loop invariants were not moved out of loop, would make 2 X 55 X 20 X 20 X 50000 = 2 billion calls to powr8i4. On a 2 GHz processor, that would require powr8i4 to be called, do its thing, and return, all within 1 cycle, to complete the run in 0.1 second, even if the rest of the program consumed no CPU cycles! You may then consider, say, 8 threads, and vectorization with 512-bit registers, and knock down the time required, but one has to conclude that the powr8i4 function is not called once for each reference to it in the Fortran source code.
In fact, since all elements of a_assoc have the same value, the entire calculation of sample.f90 could be done at compile time (or on the back of an envelope), and we could express disappointment that the compiler could not figure that out. A more meaningful test code is needed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John Campbell wrote:
It would be interesting to see the test in #13 also performed using Version 12.1.4.325 and Version 17.0.4.210. This would give some understanding of how the historical changes to optimisation have effected **, or perhaps more limited to this particular code example.
Hi John,
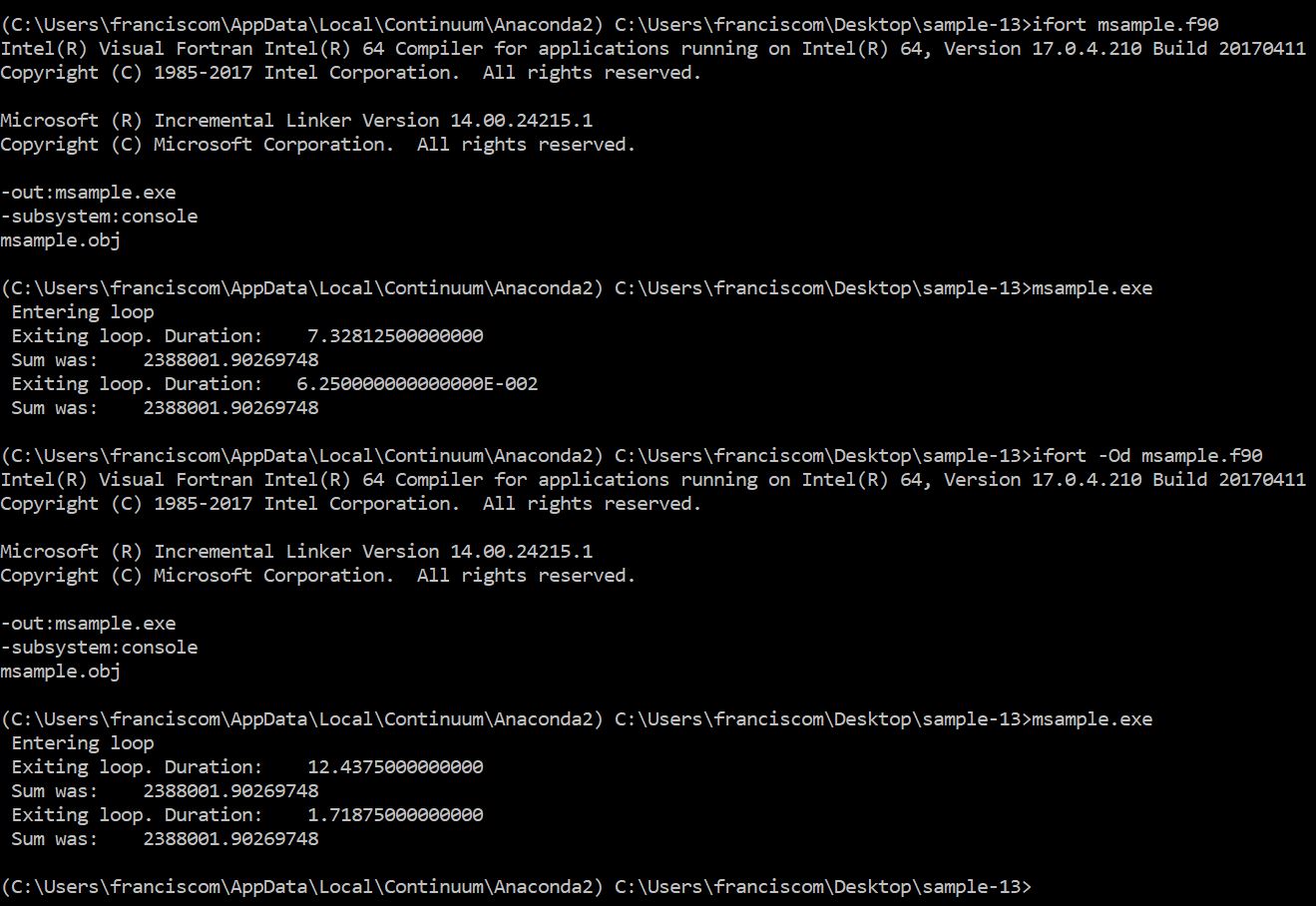
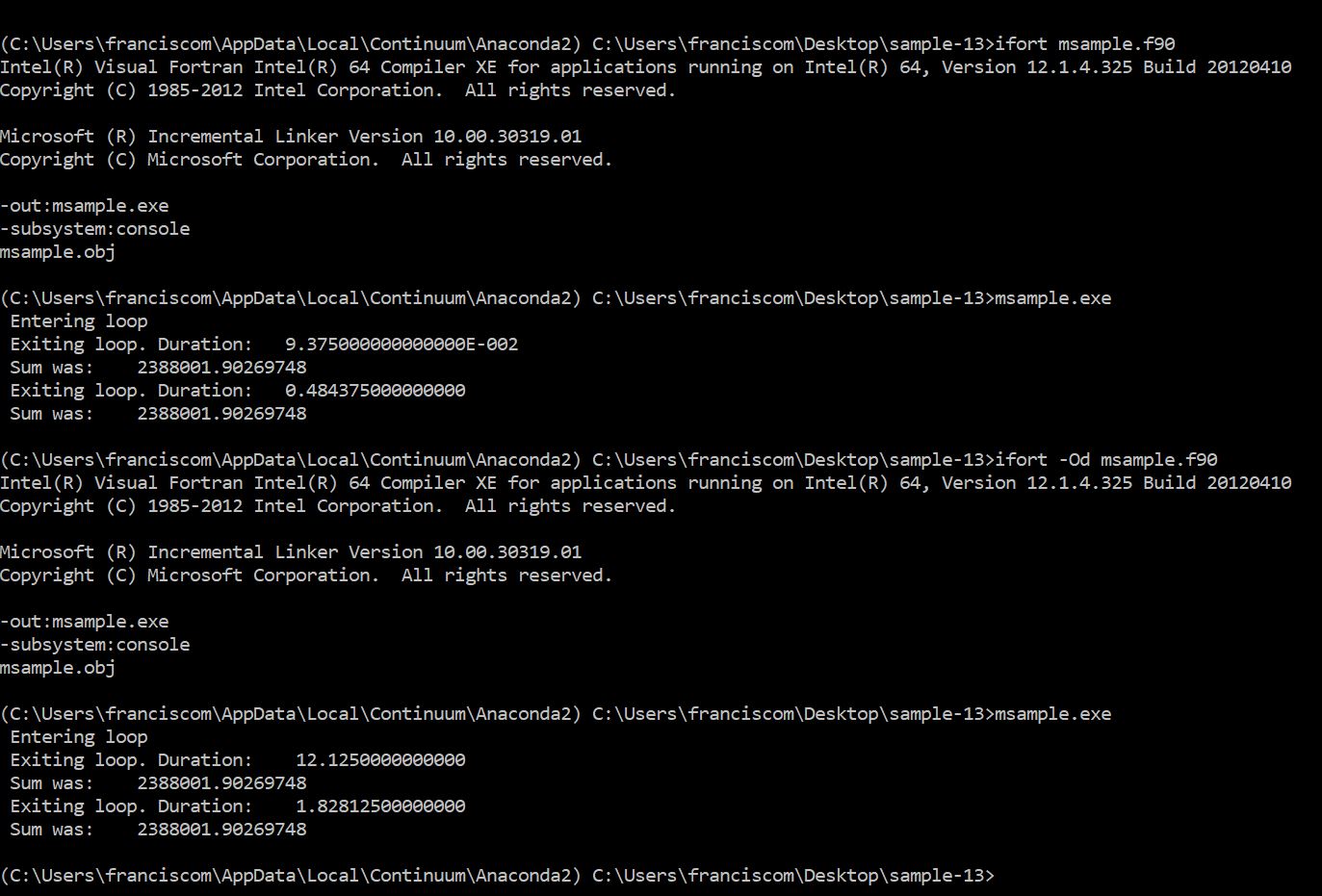
I quickly ran the tests of mecej4 with his file msample.f90. The relevant snapshots are attached.
It is very interesting that in version 12 the "brute force" loop actually runs faster than the "optimized" one given by mecej4. In version 17.0 results are much more predictable ...
Also, I ran it without optimizations (-Od) and in this case the results are the same between versions.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That was exactly my finding. The version 12 compiler (and no others) fully unrolled the inner loops for relatively large matrix order (loop trip counts), and optimized the resulting scalar code to avoid any calls to powr8i4 by making repeated multiplies. If you force the version 12 compiler to call powr8i4, the speed is very similar to all the other compilers.
If you use directives to speed up the most recent compilers, this results in fully unrolled loops and no calls to powr8i4.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page